







参考论文:https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2001.04193
文章目录
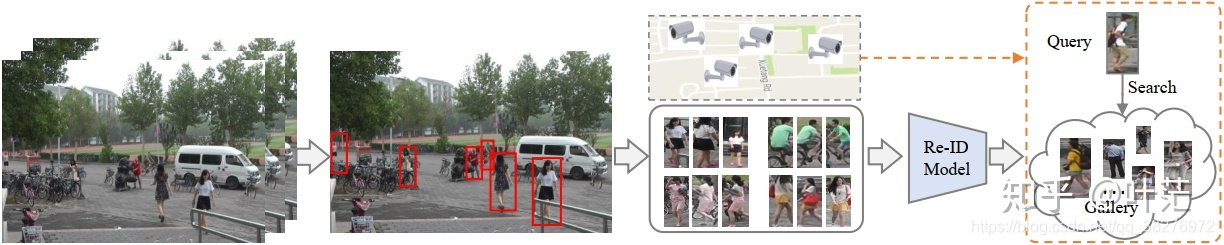
1. Re-ID的五个步骤
- 数据采集。一般来源于监控摄像机的原始视频数据。
- 行人框生成。从视频数据中,通过人工方式或者行人检测、跟踪方式将行人从图中裁切出来。
- 标注训练数据。包含相机标签和行人标签等其他信息。
- 模型训练。设计模型,让它从训练数据中尽可能挖掘“如何识别不同行人的隐藏特征表达模式”。
- 检索行人。检验该模型的实际效果。
将ReID技术分为 Closed-world 和Open-world 两大子集。Closed-world概括为大家常见的标注完整的有监督的行人重识别方法,Open-world概括为多模态数据,端到端的行人检索,无监督或半监督学习,噪声标注和一些Open-set的其他场景。
Closed-world与Open-world在这五个方面的比较
| Closed-world(在固定数据集上的理想研究) | Open-world(实际应用研究) |
|---|---|
| 单模数据(图片或者视频) | 异构数据(红外摄像头、深度摄像头) |
| 认为标记好的框 | 端到端的应用,考虑怎样框 |
| 已经标记好的 | 标记费时费力、成本高(无监督、半监督) |
| 标签都是正确的 | 噪声、错误标签 |
| 检索的人一定会出现(Query in Gallery) | 行人不一定会在第二个摄像头出现 |
2. Closed-world
2.1 特征学习(模型方面)
- 全局特征学习。例:用两个CNN提取两张图片特征,映射到高维空间之后,判断是否为同一个人。2个优化方式:模型的优化(如在最后一层全连接后加一个奇异值分解,优化了深层表达学习的能力)、注意力机制、多尺度融合等。
- 局部特征学习。把一个身体通过一个全局卷积,分成多个部分,每一部分通过一个网络,最后通过全连接层连接起来。这样提取的特征会更丰富,识别率会高一点。
- 辅助特征学习。用一些其他的信息来辅助我们,提高识别率。语义信息(如将图像通过一个网络提取深层丰富的特征,然后通过不同的全连接提取不同语义相对应的特征,然后与语义一一对比,提高识别率)、视角信息(如先用训练的图片训练得到一个前后左右的视角分类网络,测试的时候先把图片通过分类网络做一下分类,再去同类别的图片里面去找相似的)、其他域信息(如结合人脸检测和姿态颗粒检测,红外。确定了人脸和骨骼的架构,它就去识别库去寻找相同的人脸位置和骨骼架构的图像)、Generation/Augmentation扩充数据、数据增强等。
- 视频特征学习。视频比图片多了时间域,前一帧和后一帧的图片之间是有关联的,在CNN提取特征后面加上一个RNN,联系前后帧的关系。
- 特定的网络设计。利用Re-ID任务的特性,设计一些细粒度,多尺度等相关的网络结构,使其更适用于Re-ID的场景。
2.2 度量学习(损失函数方面)
早期的度量学习主要是设计不同类型的距离/相似度度量矩阵。深度学习时代,主要包括不同类型的损失函数的设计及采样策略的改进。
(1)损失函数设计
- 身份损失(Identity Loss): L i d = − 1 n ∑ i = 1 n l o g ( p ( y i ∣ x i ) ) ) L_{id} = - \frac{1}{n}\sum_{i=1}^{n}log(p(y_{i}|x_{i})))
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









