




 本文介绍了一种名为AGW的方法,通过非局部注意力块获取全局特征,通用均值池解决细粒度检索问题,以及加权正则化三元组损失优化身份验证。实验结果显示在SYSU-MM01和RegDB数据集上,通过加入CAJ随即擦除和通道增强,模型性能显著提升。
本文介绍了一种名为AGW的方法,通过非局部注意力块获取全局特征,通用均值池解决细粒度检索问题,以及加权正则化三元组损失优化身份验证。实验结果显示在SYSU-MM01和RegDB数据集上,通过加入CAJ随即擦除和通道增强,模型性能显著提升。
1. AGW主要有以下三个主要的部分
(1)Non-local Attention (Att) Block
我们采用强大的非局部注意块,来获得所有位置的特征的加权和。其中Wz是一个要学习的权值矩阵,φ(·)表示一个非局部操作,而+xi制定了一个残余学习策略。模块的输入输出维度相同。
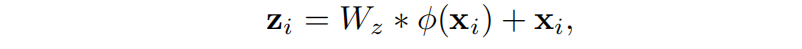
(2)Generalized-mean (GeM) Pooling
作为一个细粒度的实例检索,广泛使用的最大池或平均池不能捕获特定于领域的鉴别特征。我们采用了一个可学习的池层,称为generalized-mean (GeM) pooling。其中pk是一个池化超参数,可以在反向传播过程中学习。上述操作近似于pk→∞时的最大池化,以及pk=1时的平均池化。用一句话说:在最低纬度上,对每个元素的p次方求均值,再开p次方。
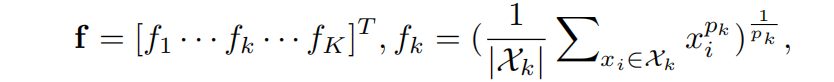
(3)Weighted Regularization Triplet (WRT) loss
除了具有软最大交叉熵的baseline身份损失外,我们提出了加权正则化的三元组损失。其中(i、j、k)表示每个批次中三元组。P是相应的正集,N是负集。上述加权正则化方法继承了正负对之间的相对距离优化的优势 ,而且避免了引入任何额外的 margin 参数。
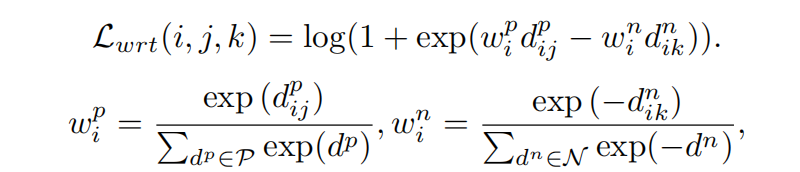
2. Overall Framework
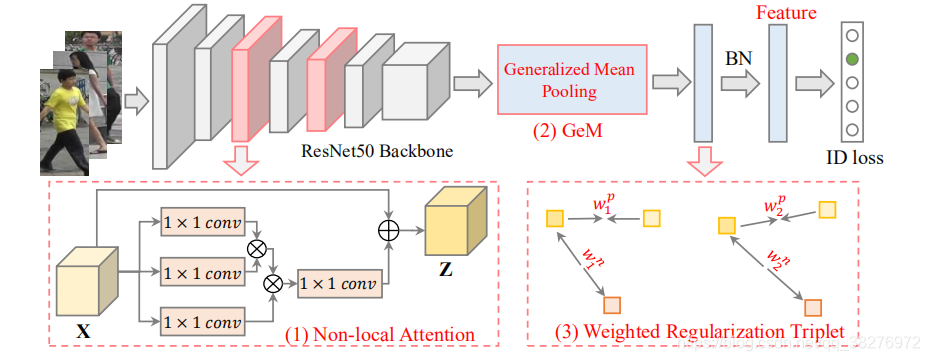
在进行跨模态reid任务时,使用两分支的该网络提取特征。在两个分支中,第一层参数是不一样的,后四层参数共享,在后四层(blocks)中只在第二个和第三个block中加入non_local模块。具体的,resnet50的后四层中包含残差块的个数分别为[3, 4, 6, 3],在第二个block中的第3、4个残差块后嵌入non_local,在第三个block中的第4、5、6个残差块后嵌入non_local。因此,总共在后四层中嵌入了5个non_local模块。
3. 实验结果
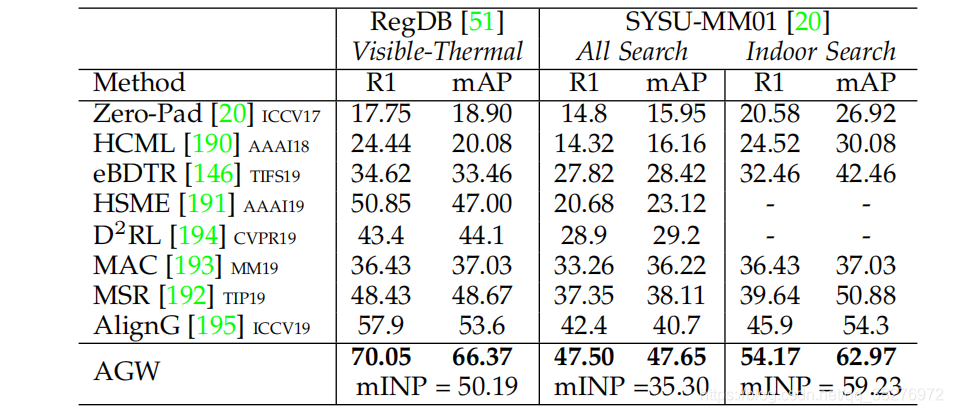 服务器结果:
服务器结果:
-----------------SYSU-MM01数据集--------------------------
-------all search
FC: Rank-1: 49.18% | Rank-5: 76.08% | Rank-10: 85.58%| Rank-20: 92.96%| mAP: 47.85%| mINP: 34.62%
POOL: Rank-1: 47.57% | Rank 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2608
2608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









