







 本文介绍了知识蒸馏的概念及其在模型优化中的应用,包括Teacher-Student模式的基本框架、基于目标蒸馏(Logits方法)的具体操作流程,以及如何通过Soft-targets提升小模型的泛化能力。
本文介绍了知识蒸馏的概念及其在模型优化中的应用,包括Teacher-Student模式的基本框架、基于目标蒸馏(Logits方法)的具体操作流程,以及如何通过Soft-targets提升小模型的泛化能力。
1. 知识蒸馏介绍
什么是知识蒸馏?
一般地,大模型往往是单个复杂网络或者是若干网络的集合,拥有良好的性能和泛化能力,而小模型因为网络规模较小,表达能力有限。因此,可以利用大模型学习到的知识去指导小模型训练,使得小模型具有与大模型相当的性能,但是参数数量大幅降低,从而实现模型压缩与加速,这就是知识蒸馏与迁移学习在模型优化中的应用。

2. 知识蒸馏基本框架
知识蒸馏采取Teacher-Student模式:将复杂且大的模型作为Teacher,Student模型结构较为简单,用Teacher来辅助Student模型的训练,Teacher学习能力强,可以将它学到的知识迁移给学习能力相对弱的Student模型,以此来增强Student模型的泛化能力。复杂笨重但是效果好的Teacher模型不上线,就单纯是个导师角色,真正部署上线进行预测任务的是灵活轻巧的Student小模型。
知识蒸馏是对模型的能力进行迁移,根据迁移的方法不同可以简单分为基于目标蒸馏(也称为Soft-target蒸馏或Logits方法蒸馏)和基于特征蒸馏的算法两个大的方向。下面,主要来看应用较广的基于目标蒸馏。
3. 目标蒸馏-Logits方法
Hinton将问题限定在分类问题下,分类问题的共同点是模型最后会有一个softmax层,其输出值对应了相应类别的概率值。在知识蒸馏时,由于我们已经有了一个泛化能力较强的Teacher模型,我们在利用Teacher模型来蒸馏训练Student模型时,可以直接让Student模型去学习Teacher模型的泛化能力。一个很直白且高效的迁移泛化能力的方法就是:使用softmax层输出的类别的概率来作为“Soft-target” 。
3.1 Hard-target 和 Soft-target
传统的神经网络训练方法是定义一个损失函数,目标是使预测值尽可能接近于真实值(Hard- target),损失函数就是使神经网络的损失值和尽可能小。这种训练过程是对ground truth求极大似然。在知识蒸馏中,是使用大模型的类别概率作为Soft-target的训练过程。

Hard-target:原始数据集标注的 one-shot 标签,除了正标签为 1,其他负标签都是 0。
Soft-target:Teacher模型softmax层输出的类别概率,每个类别都分配了概率,正标签的概率最高。
知识蒸馏用Teacher模型预测的 Soft-target 来辅助 Hard-target 训练 Student模型的方式为什么有效呢?softmax层的输出,除了正例之外,负标签也带有Teacher模型归纳推理的大量信息,比如某些负标签对应的概率远远大于其他负标签,则代表 Teacher模型在推理时认为该样本与该负标签有一定的相似性。而在传统的训练过程(Hard-target)中,所有负标签都被统一对待。也就是说,知识蒸馏的训练方式使得每个样本给Student模型带来的信息量大于传统的训练方式。
如在MNIST数据集中做手写体数字识别任务,假设某个输入的“2”更加形似"3",softmax的输出值中"3"对应的概率会比其他负标签类别高;而另一个"2"更加形似"7",则这个样本分配给"7"对应的概率会比其他负标签类别高。这两个"2"对应的Hard-target的值是相同的,但是它们的Soft-target却是不同的,由此我们可见Soft-target蕴含着比Hard-target更多的信息。
在使用 Soft-target 训练时,Student模型可以很快学习到 Teacher模型的推理过程;而传统的 Hard-target 的训练方式,所有的负标签都会被平等对待。因此,Soft-target 给 Student模型带来的信息量要大于 Hard-target,并且Soft-target分布的熵相对高时,其Soft-target蕴含的知识就更丰富。同时,使用 Soft-target 训练时,梯度的方差会更小,训练时可以使用更大的学习率,所需要的样本也更少。这也解释了为什么通过蒸馏的方法训练出的Student模型相比使用完全相同的模型结构和训练数据只使用Hard-target的训练方法得到的模型,拥有更好的泛化能力。
3.2 知识蒸馏的具体方法
在介绍知识蒸馏方法之前,首先得明白什么是Logits。我们知道,对于一般的分类问题,比如图片分类,输入一张图片后,经过DNN网络各种非线性变换,在网络最后Softmax层之前,会得到这张图片属于各个类别的大小数值 [公式] ,某个类别的 [公式] 数值越大,则模型认为输入图片属于这个类别的可能性就越大。什么是Logits? 这些汇总了网络内部各种信息后,得出的属于各个类别的汇总分值 [公式] ,就是Logits,i代表第i个类别, [公式] 代表属于第i类的可能性。因为Logits并非概率值,所以一般在Logits数值上会用Softmax函数进行变换,得出的概率值作为最终分类结果概率。Softmax一方面把Logits数值在各类别之间进行概率归一,使得各个类别归属数值满足概率分布;另外一方面,它会放大Logits数值之间的差异,使得Logits得分两极分化,Logits得分高的得到的概率值更偏大一些,而较低的Logits数值,得到的概率值则更小。
神经网络使用 softmax 层来实现 logits 向 probabilities 的转换但是直接使用softmax层的输出值作为soft target,这又会带来一个问题: 当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。因此"温度"这个变量就派上了用场。下面的公式是加了温度这个变量之后的softmax函数:

其中 q 是每个类别输出的概率,z 是每个类别输出的 logits, T就是温度。当温度T=1 时,这就是标准的 Softmax 公式。T越高,softmax的output probability distribution越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
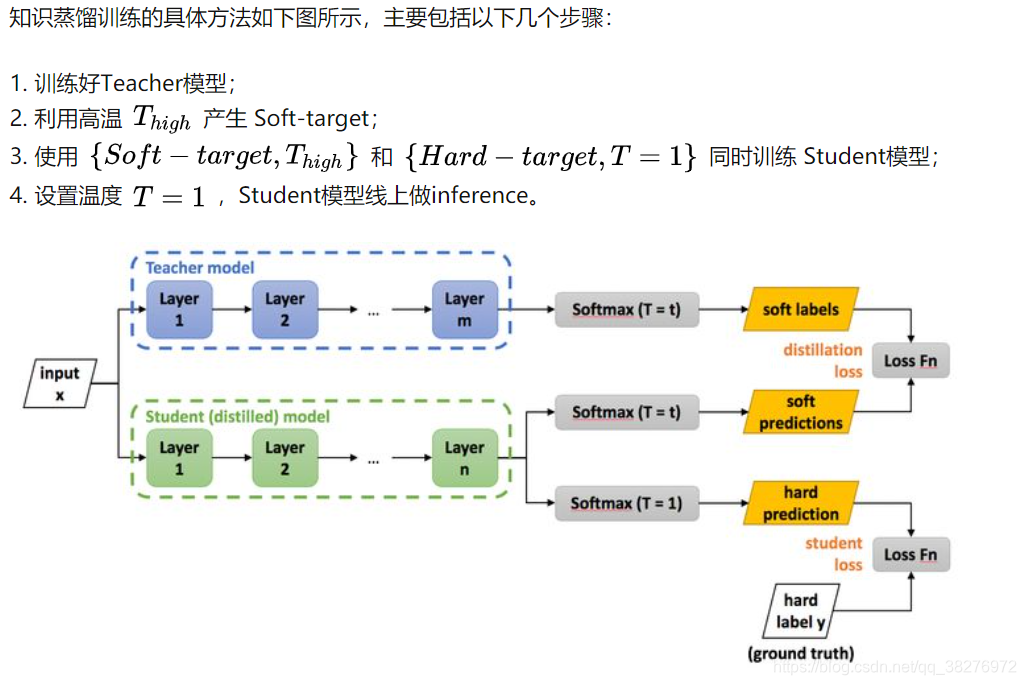
总之,将同一批数据同时放入两个模型中,将教师模型的预测输出作为软标签,将真实标签作为硬标签,分别计算学生模型的两种损失,最后将两个损失加权求和,作为最终损失更新网络参数。预测的时候,仅使用学生模型。

















 1723
1723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









