







论文:Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-identification
出处:ICLR2020
1. 创新点
该文为了解决基于聚类的无监督领域自适应方法中的伪标签噪声问题,提出使用"相互平均教学"框架在线生成并优化更为鲁棒和可信的 "软"伪标签 ,并设计了针对三元组的合理伪标签以及对应的损失函数
2. 背景
无监督领域自适应在行人重识别上的现有技术方案主要分为基于聚类的伪标签法、领域转换法、基于图像或特征相似度的伪标签法,其中基于聚类的伪标签法被证实较为有效,且保持目前最先进的精度 ,所以该论文主要围绕该类方法进行展开。
基于聚类的伪标签法,顾名思义,(i)首先用聚类算法(K-Means, DBSCAN等)对无标签的目标域图像特征进行聚类,从而生成伪标签,(ii)再用该伪标签监督网络在目标域上的学习。以上两步循环直至收敛。基于聚类的伪标签法通用框架:

尽管该类方法可以一定程度上随着模型的优化改善伪标签质量,但是模型的训练往往被伪标签噪声所干扰,并且在初始伪标签噪声较大的情况下,模型有较大的崩溃风险。
伪标签噪声主要来自于源域预训练的网络在目标域上有限的表现力、未知的目标域类别数、聚类算法本身的局限性等等。所以如何处理伪标签噪声对网络最终的性能产生了至关重要的影响。
3. 解决方法
3.1 概述
为了有效地解决基于聚类的算法中的伪标签噪声的问题,该文提出利用"同步平均教学"框架进行伪标签优化,核心思想是利用更为鲁棒的"软"标签对伪标签进行在线优化。在这里,"硬"标签指代置信度为100%的标签,如常用的one-hot标签[0,1,0,0],而"软"标签指代置信度<100%的标签,如[0.1,0.6,0.2,0.1]。

如上图所示,A1与A2为同一类,外貌相似的B实际为另一类,由于姿态多样性,聚类算法产生的伪标签错误地将A1与B分为一类,而将A1与A2分为不同类,使用错误的伪标签进行训练会造成误差的不断放大。该文指出,网络由于具备学习和捕获数据分布的能力,所以网络的输出本身就可以作为一种有效的监督。然而,利用网络的输出来训练自己是不可取的,会无法避免地造成误差的放大。所以该文提出同步训练对称的网络,在协同训练下达到相互监督的效果,从而避免对网络自身的输出误差形成过拟合。在实际操作中,该文利用"平均模型"进行监督,提供更为可信和稳定的"软"标签,将在下文进行描述。
- 提出"相互平均教学"(Mutual Mean-Teaching)框架为无监督领域自适应的任务提供更为可信的、鲁棒的伪标签;
- 针对三元组(Triplet)设计合理的伪标签以及匹配的损失函数,以支持协同训练的框架。
3.2 相互平均教学(MMT)
 如上图所示,该文提出的"相互平均教学"框架利用离线优化的"硬"伪标签与在线优化的"软"伪标签进行联合训练。"硬"伪标签由聚类生成,在每个训练epoch前进行单独更新;"软"伪标签由协同训练的网络生成,随着网络的更新被在线优化。直观地来说,该框架利用同行网络(Peer Networks)的输出来减轻伪标签中的噪声,并利用该输出的互补性来优化彼此。而为了增强该互补性,主要采取以下措施:
如上图所示,该文提出的"相互平均教学"框架利用离线优化的"硬"伪标签与在线优化的"软"伪标签进行联合训练。"硬"伪标签由聚类生成,在每个训练epoch前进行单独更新;"软"伪标签由协同训练的网络生成,随着网络的更新被在线优化。直观地来说,该框架利用同行网络(Peer Networks)的输出来减轻伪标签中的噪声,并利用该输出的互补性来优化彼此。而为了增强该互补性,主要采取以下措施:
- 对两个网络Net 1和Net 2使用不同的初始化参数;
- 随机产生不同干扰,例如,对输入两个网络的图像采用不同的随机增强方式,如随机裁剪、随机翻转、随机擦除等,对两个网络的输出特征采用随机dropout;
- 训练Net 1和Net 2时采用不同的"软"监督,i.e. “软"标签来自对方网络的"平均模型”;
- 采用网络的"平均模型"Mean-Net 1/2而不是当前的网络本身Net 1/2进行相互监督
此处,"平均模型"的参数是对应网络参数的累计平均值,具体来说,"平均模型"的参数不是由损失函数的反向传播来进行更新的。而是在每次损失函数的反向传播后,利用以下公式将对应的网络参数以a进行加权平均: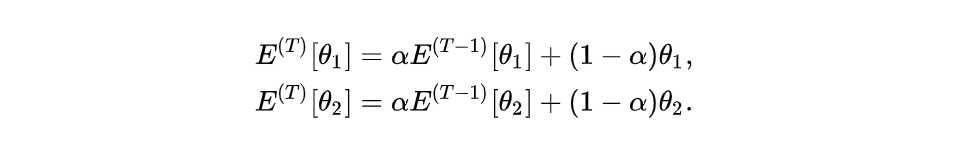
"平均模型"可以看作对网络过去的参数进行平均,两个"平均模型"由于具有时间上的累积,解耦性更强,输出更加独立和互补。值得注意的是,由于"平均模型"不会进行反向传播,所以不需要计算和存储梯度,并不会大规模增加显存和计算复杂度。在测试时,只使用其中一个网络进行推理,相比较baseline,不会增加测试时的计算复杂度。
在行人重识别任务中,通常使用分类损失与三元损失进行联合训练以达到较好的精度。其中分类损失作用于分类器的预测值,而三元损失直接作用于图像特征。该文提出的"相互平均教学"框架利用"硬"/“软"分类损失和"硬”/"软"三元损失联合训练,在每个训练iteration中,主要由三步组成:
- 通过"平均模型"计算分类预测和三元组特征的"软"伪标签;
- 通过损失函数的反向传播更新Net 1和Net 2的参数;
- 通过参数加权平均法更新Mean-Net 1和Mean-Net 2的参数。
有一种简单的协同学习方案是将此处的"平均模型"去除,直接使用网络自己的输出去监督对称的网络,如利用Net 1的输出去监督Net 2。而在这样的方案下存在两点弊端,(1)由于网络本身靠反向传播参数更新较快,受噪声影响更严重,所以用这样不稳定的监督容易对网络的学习造成影响。(2)该简化方案让网络直接训练逼近彼此,会使得网络迅速收敛至相似,降低输出的互补性。
3.3 软分类损失
"硬"伪标签,由聚类产生。在"相互平均教学"框架中,"软"分类损失中的"软"伪标签是"平均模型"Mean-Net 1/2的分类预测值。针对分类预测,很容易想到"软"交叉熵损失函数,该损失函数被广泛应用于模型蒸馏,用以减小两个分布间的距离。
该式旨在让Net 1的分类预测值逼近Mean-Net 2的分类预测值,让Net 2的分类预测值逼近Mean-Net 1的分类预测值。
3.4 软三元损失
传统的三元(anchor, positive, negative)损失函数。该式可以用以支持"硬"伪标签的训练。但是,不足以支持软标签的训练,减法形式的三元损失也无法直观地提供软标签。
作者提出了可以让Traplet loss支持软标签的softmax-triplet loss
该损失函数旨在让Net 1输出的softmax-triplet逼近Mean-Net 2的softmax-triplet预测值,让Net 2输出的softmax-triplet逼近Mean-Net 1的softmax-triplet预测值。通过该损失函数的设计,该文有效地解决了传统三元损失函数无法支持"软"标签训练的局限性。















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









