







Learning to Navigate for Fine-grained Classification
摘要
文中为细粒度分类提出了一种新的有效的网络结构,这种网络结构分成三个部分,导航结构,教师结构,检查结构。导航结构在教师结构的引导下挖掘出绝大数的信息区域,但是在检查结构检查推荐的区域,并做出预测。 模型训练来说是可以端到端的。
简介
网络中需要,被标记groud-truth大概率的区域,需要包含更多促进分类准确性的语义信息。为此文中设计了一个新的loss function,这个函数可以优化信息素,能够使得选择区域与它是groud truth的概率有相同的顺序。文中使用全图的groud truth 类别作为区域的groud truth类别。
文中网络分成三个结构,导航结构,检查结构,教师结构。导航结构的功能是关注与大多信息区域,这个区域包含什么样的信息,以及推荐信息多的区域。
教师结构功能是评估导航结构推荐的区域并给出反馈。并通过新的Loss函数,促使导航区域推荐更加信息化的区域。检查结构检查推荐来自导航结构的推荐区域,并完成分类任务。在检查结构中每一个区域都会被resize成相同大小,并且抽取区域特征,将区域特征与图像的整体特征相结合。并作出分类结果。
文中的主要贡献如下:
- 使用一种多结构自监督的网络,来提取信息,并且这中结构不需要详细的标注。
- 设计了一个新的Loss Function, 可以促使教师结构引导导航结构定位最主要的信息区域。这种机制是通过促进区域信息量与groud truth相结合实现的。
模型概略如下图

算法方案
算法基于的假设如下,区域信息能够更好的表达目标特性,所以区域和全局的混合特征能够收获到更好的表现。 首先假设集合A代表图像所有的局部,定义信息函数如下
![]()
定义置信函数如下
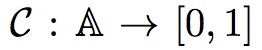
这个函数主要是评价区域是否属于groud truth的置信度。
基本假设是信息越多置信度越高
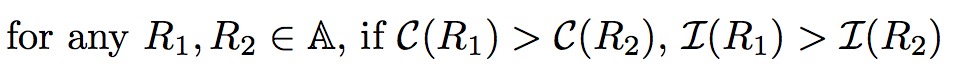
使用引导网络逼近信息函数I,使用教师网络逼近置信度函数C。
从区域集合中选择出M个区域。同时优化引导网络满足下面两个序列
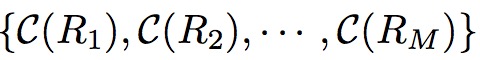
有相同的顺序。
教师和引导
引导结构的功能有点类似于RPN网络。用来推荐区域。在本文中也是用了anchors机制,使用的anchor是对于448的图片,{48, 96, 192},比例{1:1, 3:2, 2:3},引导结构产生一个列表代表说有anchor的信息量,之后重新排序这个信息列表。
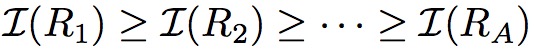
为了减少区域的冗余,使用了极大抑制方法,根据区域的信息量。然后选择出最大的M个区域
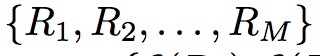
并且将他们送到教师结构中获得置信度
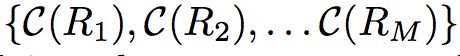
其中M是超参,代表使用几个区域训练引导结构,优化训练结构使得上面两个序列有相同的顺序。每一个推荐的区域优化教师结构通过最小化groud truth类别以及预测置信度之间的交叉熵。
下图是anchor的设计方式,448的网络,{48, 96, 192},比例{1:1, 3:2, 2:3}

网络结构
为了获得区域推荐和feature map特征的相关性,文中使用了全卷积网络来提取特特征,其中网络的三种网络结构,共享特征提取网络参数。

引导结构:
借鉴与FPN的结构,文中设计了一个top-down 的横向连接结构,定位多尺度区域。通过卷积获得各层不同的feature map,其中大feature map的anchor对应小区域。不同的feature map可以生成不同尺度的信息区域,使用{14x14, 7x7, 4x4}与尺度{48x48, 96x96, 192x192}区域对应。
教师结构
教师结构主要是给推荐区域一个置信度,其中引导结构给出的推荐区域需要resize成224x224大小,其中教师结构有一个2048的全连接神经网络。

检查结构
检查结构将这些推荐区域的向量以及全局向量concat到一起,然后输出结果。
损失函数和优化
引导损失
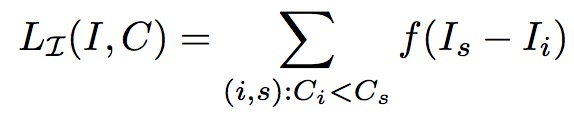
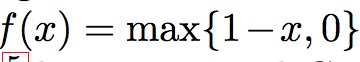
反向传播的公式如下

教师Loss
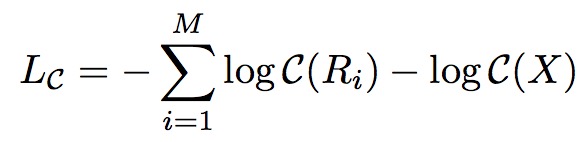
检查Loss
使用的交叉熵Loss
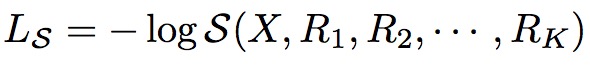
其中总的Loss是
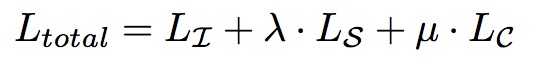
其中两个参数都为1.
文中的超参有K, M其中K是要输入到检查网络中的top-k区域。M表示从引导结构中选择出的M个区域。

这是算法的主要流程。
附一:
排序学习
排序学习主要应用在机器学习领域。定义对象的排序如下
![]()
对象的索引如下
![]()
如果yi > yj 意味着xi应该排在xj之前。给定一个排序函数F.
对于排序算法来说类别主要有如下几类
- point-wise方法
将排序问题作为一个回归问题来看待,那么它的Loss函数就是L2
- pair-wise放法
将排序问题作为一个分类问题来看待,那么其Loss 函数如下
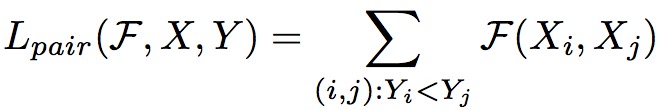
F(xi, xj)只有两个值一个为0另一个为1。
如果xi排序在xj以前那么F(xi, xj)= 0
- list-wise方法
















 2120
2120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









