







博主:CherFen
一、 马尔科夫决策过程之Markov Processes(马尔科夫过程):
马尔科夫决策过程(Markov Decision Processes,MDP),是强化学习研究的理论基石,MDP过程是一种随机过程,该模型能够提供一种非常简便的表达方式,对于解决序贯决策问题(Sequential Decision)十分有效。
l 面对的状态St,数量是有限的
l 采取的行动方案at,数量是有限的
l 对应于特定的状态St,当下的收益rt是明确的
l 在某一个时刻t,采取行动方案at,状态从当前的St转换成下一个状态,下一个状St+1态有很多种可能,记为Sit+1,i=1…n。
具有马尔科夫性质的状态满足下面公式:

所谓的马尔科夫性是指系统的下一个状态St+1仅与当前的状态St有关,而与以前的状态无关,面对局面St,采取行动at,下一个状态是,不是确定的,而是概率的,状态转换概率,记为P(Sit+1 |St,at),但是状态的转换只依赖于当前的状态St,而与先前状态St-1,St-2…无关。
马尔科夫过程是一个二元组(S,P),且满足:S是有限状态集合,P是状态转移概率,
状态转移概率公式:Pss’ = P(St+1 = s’| St = s)
状态转移概率矩阵为:

马尔科夫链是指在给定状态转移概率时,从某个状态出发存在多条马尔科夫链,马尔科夫过程中不存在动作和奖励,将动作(策略)和回报考虑在内的马尔科夫过程称之马尔科夫决策过程。
二、马尔科夫决策过程之MarkovReward Process(马尔科夫奖励过程):
马尔科夫决策过程是由元组(S,A,P,R,γ)描述:其中
l S 为有限的状态集
l A 为有限的动作集
l P 为状态转移的概率
l R 为回报函数
l γ为折扣因子,用来计算累计回报
强化学习的目标在于给定一个马尔科夫决策过程,寻找最优策略。策略是指状态到动作的映射,策略常用符号π表示,指给定状态S时,动作集上的一个分布,
即:
强化学习是找到最优的策略,这里的最优是指得到的总回报最大。当给定一个策略π时,我们可以计算累计回报。
即:
在策略π下,我们可以获得多个Gt值,由于策略π是随机的,因此累积回报也是随机的。为了评价状态St的价值,我们需要定义一个确定量来描述状态St的价值,很自然的想法是利用累积回报来衡量状态S1的价值。然而,累积回报Gt是个随机变量,不是一个确定值。因此无法描述,但其期望是个确定值,可以作为状态值函数。
状态-值函数:
当智能体采用策略π时,累积回报服从一个分布,累积回报在状态S处的期望值定义为状态-值函数:
即:
状态-行为函数为:
三、马尔科夫决策过程之BellmanEquation(贝尔曼方程):
状态-值函数的贝尔曼方程:
即:
状态-动作值函数贝尔曼方程:
即:
计算状态值函数的目的是为了构建学习算法从数据中取得到最优策略,每个策略对应着一个状态值函数,最优策略自然对应最优状态值函数。
最优状态值函数为所在策略中值最大的值函数,
即:
最优状态-行为值函数为所在策略中最大的状态-行为值函数,
即:






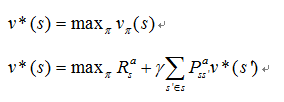















 709
709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









