






1.金标准
在上一节课中,我们看到了相关与因果关系是不一样的以及为什么不一样。我们还明白了相关与因果关系差在哪里。
E
[
Y
∣
T
=
1
]
−
E
[
Y
∣
T
=
0
]
=
E
[
Y
1
−
Y
0
∣
T
=
1
]
⏟
A
T
T
+
{
E
[
Y
0
∣
T
=
1
]
−
E
[
Y
0
∣
T
=
0
]
}
⏟
B
I
A
S
E[Y|T=1] - E[Y|T=0] = \underbrace{E[Y_1 - Y_0|T=1]}_{ATT} + \underbrace{\{ E[Y_0|T=1] - E[Y_0|T=0] \}}_{BIAS}
E[Y∣T=1]−E[Y∣T=0]=ATT
E[Y1−Y0∣T=1]+BIAS
{E[Y0∣T=1]−E[Y0∣T=0]}
如果没有偏差,相关就会成为因果关系。没有偏差,也就是
E
[
Y
0
∣
T
=
0
]
=
E
[
Y
0
∣
T
=
1
]
E[Y_0|T=0]=E[Y_0|T=1]
E[Y0∣T=0]=E[Y0∣T=1] 。
如果实验组和对照组是可比的,差异仅仅体现在(即将要实施的)干预,那么此时相关就成了因果。用更专业的术话来说,对照组的结果等于实验组的反事实结果时。如果实验组没有接受干预,实验组的潜在结果就是其反事实结果。
我们前面在解释如何使数学表达式中的相关等于因果方面做得很好。但这只是理论上的。现在,我们来看第一个消除偏差的工具:随机实验。随机实验将人群中的个体随机分配到实验组和对照组中。当然接受干预的比例不一定非得是50%,当然也可以让10%的样本进入实验组。
随机化通过使潜在结果与干预独立来消除偏差。
(
Y
0
,
Y
1
)
⊥
⊥
T
(Y_0, Y_1) \perp\!\!\!\perp T
(Y0,Y1)⊥⊥T
一开始这可能会让人感到困惑(至少对才接触的我是这样)。但别担心,我勇敢而真诚的伙伴,我会进一步解释的。如果结果与干预无关,这难道不意味着干预没有任何效果吗?嗯,是的!但请注意,我不是在谈论结果。相反,我说的是潜在结果(potential outcomes).
潜在结果的含义是如果干预的结果(
Y
1
Y_1
Y1)或如果不干预的结果((
Y
0
Y_0
Y0)。在随机试验中,我们不希望结果与干预独立,因为我们认为干预会导致不一样的结果。但我们这里其实是希望潜在的结果与干预无关。

我们说潜在结果与干预无关,就是说在预期中,实验组和对照组的结果是相同的,具有可比性。或者说,在干预实施之前,即使我们知道分组信息后,并不能得到哪一组的结果更好或者更差的信息。
因此
(
Y
0
,
Y
1
)
⊥
T
(Y_0, Y_1)\perp T
(Y0,Y1)⊥T意味着干预是在实验组和对照组中产生结果差异的唯一因素。它也与下这个等式是等价的:
E
[
Y
0
∣
T
=
0
]
=
E
[
Y
0
∣
T
=
1
]
=
E
[
Y
0
]
E[Y_0|T=0]=E[Y_0|T=1]=E[Y_0]
E[Y0∣T=0]=E[Y0∣T=1]=E[Y0]
满足这个条件后,就可以消除偏差:
E
[
Y
∣
T
=
1
]
−
E
[
Y
∣
T
=
0
]
=
E
[
Y
1
−
Y
0
]
=
A
T
E
E[Y|T=1] - E[Y|T=0] = E[Y_1 - Y_0]=ATE
E[Y∣T=1]−E[Y∣T=0]=E[Y1−Y0]=ATE
因此,随机化为我们提供了一种方法,可以简单地使用实验组和对照组之间的差异来衡量干预效果。
2.线上教学 vs 线下教学
2020年,新型冠状病毒大流行迫使企业适应社交距离。快递服务普及,大公司工作方式转为远程办公。对于学校来说,情况也没什么不同,许多学校开始线上教学。
危机发生四个月后,许多人怀疑新型冠状病毒大流行所引入的变革能否维持下去。毫无疑问,在线学习有其好处。它更便宜,因为它可以节省房地产和交通费用。它还可以更加数字化,利用来自全球各地的世界级内容,而不仅仅是来自固定的教师。尽管如此,我们仍然需要回答在线学习对学生的学习成绩是负面影响还是正面影响。
解决这个问题的一种方法是,将主要使用线上教学的学校学生与在传统课堂线下教学的学校学生成绩进行比较。正如我们可以想象的到的,这不是最好的方法。这是因为在线学校可能会吸引更自律的学生,他们的表现本就比平均水平要好(不论是线上教学还是线下教学)。在这种情况下,我们的估计中会有正向的偏差,即线上教学对学生的学习成绩是正面影响(即使实际上压根没有影响):
E
[
Y
0
∣
T
=
1
]
>
E
[
Y
0
∣
T
=
0
]
E[Y_0|T=1] > E[Y_0|T=0]
E[Y0∣T=1]>E[Y0∣T=0]。
因此,尽管我们可以进行简单的比较,但它不会令人信服。无论如何,我们永远无法确定是否有任何偏差潜伏在我们周围,掩盖了我们的因果效应。

为了解决这个问题,我们需要使干预和未干预的实验对象具有可比性:
E
[
Y
0
∣
T
=
1
]
=
E
[
Y
0
∣
T
=
0
]
E[Y_0|T=1] = E[Y_0|T=0]
E[Y0∣T=1]=E[Y0∣T=0]。强制这样做的一种方法是将线上教学和线下教学随机分配给学生。如果可以做到这一点,那么除了他们接受的干预外,平均而言,实验组和对照组是同质的,可比的。
幸运的是,一些经济学家为我们做到了这一点。他们将课程随机分给学生,让一些学生进行面对面的授课,另一些学生只进行在线课程,第三组学生则采用在线和面对面的混合形式。他们收集了学期末标准考试的数据,如下所示。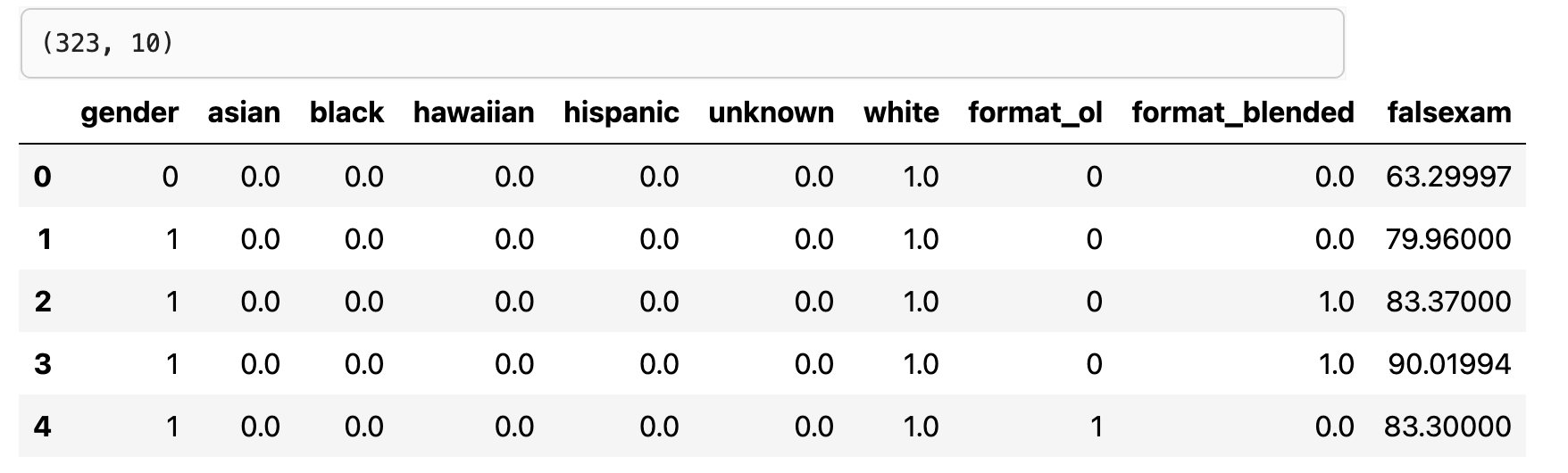
我们可以看到我们有323个样本,虽然数据量不大,但我们可以使用来测试如何计算因果效应。为了估计因果效应,我们可以简单地计算每个实验组的平均得分。
(data
.assign(class_format = np.select(
[data["format_ol"].astype(bool), data["format_blended"].astype(bool)],
["online", "blended"],
default="face_to_face"
))
.groupby(["class_format"])
.mean())
是的,计算就是这么简单。我们可以看到,面对面授课的平均得分为78.54,而在线课程的平均分数为73.63。对于支持在线学习的人来说,这不是一个好消息。线上教学的 A T E ATE ATE仅有-4.91。这意味着线上上课会让学生的平均成绩降低约5分。你不必担心在线课程可能会有更穷的学生负担不起面对面的课程,或者担心接受不同治疗的学生在其他方面都有所不同。随机实验就是通过设计来消除这些差异的。
出于这个原因,一个明智的检查(check随机化是否做得正确)就是检查实验组和对照组在干预前的各个变量(可能跟结果相关的变量)是否可比。我们的数据就有关于性别和种族的信息,让我们康康它们在不同组内是否相似。我们可以说,在性别比例、亚洲人比例、西班牙裔比例和白人比例这几个变量上,他们看起来非常相似。然而,黑色人种比例上似乎有点不同。这引起了人们对小数据集的关注。即使在随机分配的情况下,一个组与另一个组也可能由于偶然性出现不同。这种差异往往随着样本量的增大逐渐消失或者减弱。
3.理想的实验
随机实验或随机对照试验(RCT)是获得因果效应的最可靠方法。这是一种直截了当且令人信服的方法。它是如此强大,以至于大多数国家都将其作为证明新药有效性的要求。做一个可怕的类比,你可以把RCT想象成《阿凡达:最后的气弯者》中的Aang,而其他技术更像Sokka。Sokka很酷,可以在这里和那里耍一些巧妙的把戏,但Aang可以弯曲四个元素,与精神世界联系起来。RCT将是我们揭示因果关系所要做的一切,设计精良的随机对照试验是任何科学家的梦想。
不幸的是,它们往往要么非常昂贵,要么不道德。有时,我们根本无法控制分配机制。想象一下,你自己是一名医生,试图估计怀孕期间吸烟对婴儿出生时体重的影响。你不能直接去强迫一部分妈妈在怀孕期间吸烟把?或者说你在一家大银行工作,你需要估计信贷额度对客户流失的影响,随机给你的客户提供信贷额度的代价太大了。或者你想了解提高最低工资对失业的影响。你不能简单地指定国家有一个或另一个最低工资把?我想,聪明的你应该明白这一点了。
我们稍后将看到如何通过使用条件随机化来降低随机化的成本,但对于不道德或不可行的实验,我们无能为力。尽管如此,每当我们处理因果问题时,都值得思考理想的实验。总是问问自己,如果可以的话,你会做什么样的完美实验来揭示这种因果关系?这往往为我们如何在没有理想实验的情况下发现因果效应提供了一些线索。
4. 分配机制
在随机实验中,将实验单元分配给实验组或者对照组的机制是随机的。正如我们稍后将看到的,所有的因果推断技术都会以某种方式试图确定干预的分配机制。当我们确切地知道这种机制如何起作用时,即使分配机制不是随机的,我们在进行因果推理也会更有信心。
不幸的是,不能通过简单地查看数据来发现分配机制。例如,如果你有一个高等教育与财产相关的数据集,你不能仅仅通过查看数据就确定是哪一个导致了哪一个。你必须利用你对世界如何运作的知识来支持一种合理的分配机制:学校是否通过教育人们,使他们更有生产力,并引导他们找到高薪工作。或者,如果你对教育持悲观态度,你可以说学校对提高生产力毫无帮助,而这只是一种虚假的相关性,因为只有富裕家庭才能负担得起让孩子获得更高的学位。
在因果问题中,我们通常可以用两种方式争论:X导致Y,或者是第三个变量Z同时导致X和Y,因此X和Y的相关性只是虚假的。因此,了解分配机制会得到一个更有说服力的因果答案。这也是因果推断如此令人兴奋的原因。虽然应用ML通常只是按正确的顺序按下一些按钮,但应用因果推断需要您认真思考生成数据的机制。
5.关键点
随机实验如是揭示因果影响的最简单、最有效的方法。它通过使治疗组和对照组具有可比性来做到这一点。不幸的是,我们不可能一直做随机实验,但如果可以的话,思考什么是理想的实验仍然是有帮助的。
熟悉统计学的人现在可能会抗议我在上面的案例中没有考虑因果效应估计的方差:我怎么知道4.91分的下降不是偶然的呢?换句话说,我怎样才能知道这种差异是否具有统计学意义?他们是对的。别担心,接下来我打算复习一些统计学概念。

















 2770
2770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









