







提出背景
- 现有的KG-based的推荐系统仅仅利用了知识图谱的结构化数据,关注于图谱节点和节点关系,忽略了多模态知识图谱信息(图像,文本,视频等)。
- 多模态信息在进行推荐的时候起到至关重要的作用。例如在电影推荐中,用户通常会观看其海报或者预告片,决定是否观看此影片,因此,将多模态信息加入知识图谱中,利用知识图谱进行推荐是有必要的。

多模态知识图谱表示学习
基于特征的表示学习
基于特征的方法将模态信息视为实体的辅助特征。
基于实体的表示学习
基于实体的方法将不同类型的信息(例如文本和图像)视为结构化知识的关系三元组。
本文贡献
- 这是将多模态知识图引入推荐系统的第一项工作,由于多模态知识建模往往是不同模态的辅助信息关系,而非传统图谱中三元组所代表的语义关联关系,故传统的图谱建模方式并不能很好地对多模态知识图谱进行建模。。
- 我们开发了一种新的MKGAT模型,该模型利用多模态知识图上的信息传播来获得更好的实体嵌入以进行推荐。
共现知识图谱Collaborative Knowledge Graph
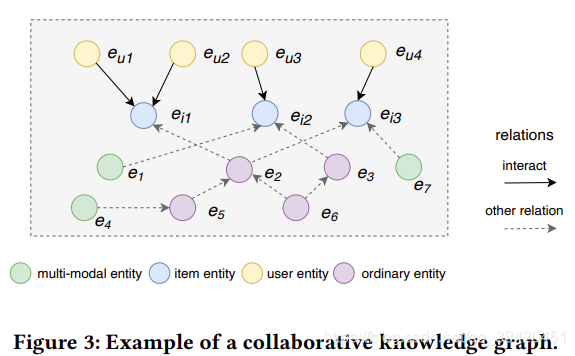
该知识图谱包括用户-项目二部图和原始的多模态知识图谱; 知识图谱中的实体既包括物品,也包括用户 。物品和用户之间的关系只有交互关系,即把共现矩阵的信息补充到知识图谱中。
模型基本架构
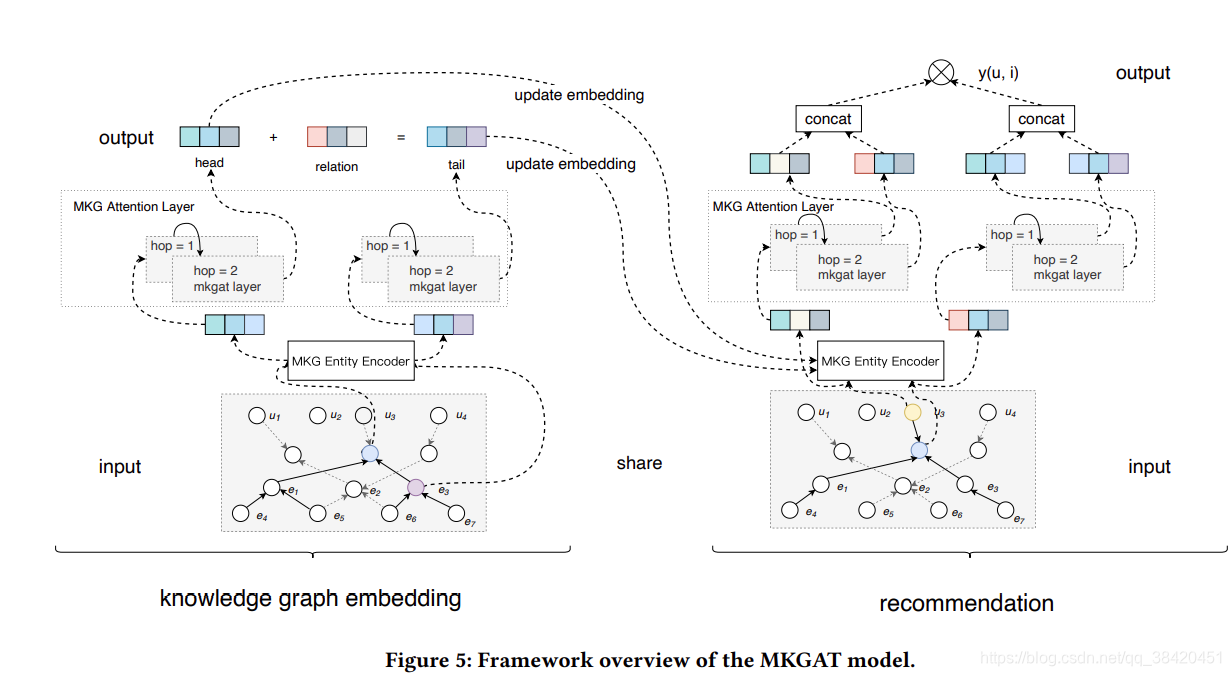
Multi-modal Knowledge Graph Embedding Module
以协作知识图谱作为输入,知识图谱嵌入模块利用多模式知识图(MKG)实体编码器和MKG注意层为每个实体学习新的实体表示。 新的实体表示将汇总其邻居的信息,同时保留有关其自身的信息。 然后,可以使用新的实体表示来学习知识图 嵌入,以表示知识推理关系。
Multi-modal knowledge graph entity encoder
为了将多模态实体整合到模型中,我们提出了对不同模态数据学习不同的嵌入。我们利用深度学习的最新进展为这些实体构造编码器以表示它们,从而为所有实体提供嵌入。
- 结构信息
采用翻译模型获得三元组的头实体,关系,尾实体的嵌入表示。 - 图像信息
为了表示图像的语义信息,采用经过在 Imagenet预训练的ResNet50获取嵌入表示。 - 文本信息
采用Word2Vec获得文本信息的嵌入表示然后应用平滑逆频率(SIF)模型[1]来获取句子的单词向量的加权平均值,将其用作代表文本特征的句子向量。

Multi-modal Knowledge Graph Attention Layer
传播层
给定候选实体 h h h,首先通过transE模型学习知识图的结构化表示,然后把实体ℎ的多模态邻居实体信息汇总到实体 h h h(若 h h h为物品实体,则相邻实体可以是购买过此物品的所有用户,或者是同属于某一类型的其他物品,这些实体信息都有助于增强 h h h的语义表示;若 h h h为用户实体,则相邻实体是该用户购买过的所有物品,体现了该用户的历史购买兴趣)。 N h N_h Nh 表示直接连接到h的三元组的集合,集合了邻居实体信息,是每个三元组的线性组合,计算公式为
e a g g = ∑ ( h , r , t ) ∈ N h π ( h , r , t ) e ( h , r , t ) \mathbf{e}_{a g g}=\sum_{(h, r, t) \in \mathcal{N}_{h}} \pi(h, r, t) \mathbf{e}(h, r, t) eagg=(h,r,t)∈Nh∑π(h,r,t)e(h,r,t)
其中 e ( h , r , t ) e(h, r, t) e(h,r,t)是每个三元组 ( h , r , t ) (h, r, t) (h,r,t) 的嵌入,而 π ( h , r , t ) π(h, r, t) π(h,r,t) 是每个三元组 e ( h , r , t ) e(h, r, t) e(h,r,t) 的注意力得分; e
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2174
2174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









