







OpenCL Reduction操作与group同步
先解释一下什么是reduction操作和barrier操作
- Reduction操作:规约操作就是由多个数生成一个数,如求最大值、最小值、向量点积、求和等操作,都属于这一类操作。
- group同步:OpenCL只提供了工作组内的各线程之间的同步机制,并没有提供所有线程的同步。提供组内item-work同步的方法:
void barrier (cl_mem_fence_flags flags)
参数说明:
cl_mem_fence_flags 可以取CLK_LOCAL_MEM_FENCE、CLK_GLOBAL_MEM_FENCE
函数说明:
一个work-group中所有work-item遇到barrier方法,都要等待其他work-item也到达该语句,才能执行后面的程序;还可以组内的work-item对local or global memory的顺序读写操作。
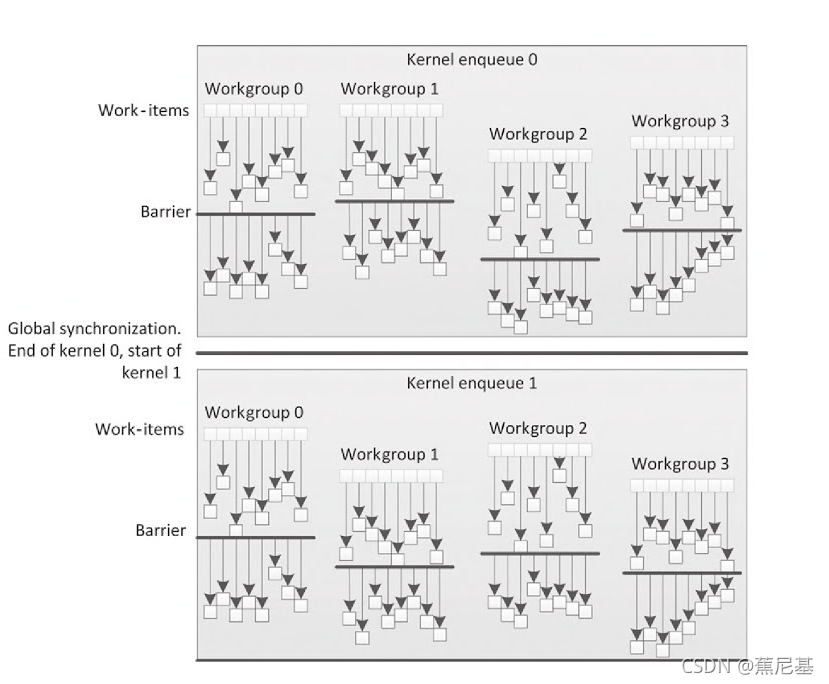
代码示例讲解
__kernel void reduction_scalar(__global float* data,
__local float* partial_sums, __global float* output) {
int lid = get_local_id(0);
int group_size = get_local_size(0);
partial_sums[lid] = data[get_global_id(0)];
barrier(CLK_LOCAL_MEM_FENCE);
for(int i = group_size/2; i>0; i >>= 1) {
if(lid < i) {
partial_sums[lid] += partial_sums[lid + i];
}
barrier(CLK_LOCAL_MEM_FENCE);
}
if(lid == 0) {
output[get_group_id(0)] = partial_sums[0];
}
}
这是一个标准的reduction算法和goup同步的一个kernel 示例,很多的书上或者教程都是一这个示例来讲解的。我这边会详细的,从我的理解上讲解什么是reduction和barrier。
从第一张图片可以清楚的看到barrier 的作用,在组内,每个工作项想要执行下一条指令代码,必须等待同组内所有工作项都完成该操作。
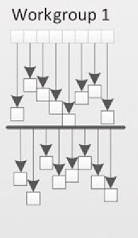
partial_sums[lid] = data[get_global_id(0)];
barrier(CLK_LOCAL_MEM_FENCE);
该行代码是将所有全局工作项数据分配到组内的工作项后,开始下一步操作。实际的数据情况如下图。
for(int i = group_size/2; i>0; i >>= 1) {
if(lid < i) {
partial_sums[lid] += partial_sums[lid + i];
}
barrier(CLK_LOCAL_MEM_FENCE);
}
这段代码就是reduction,每次对半,循环右移一位。
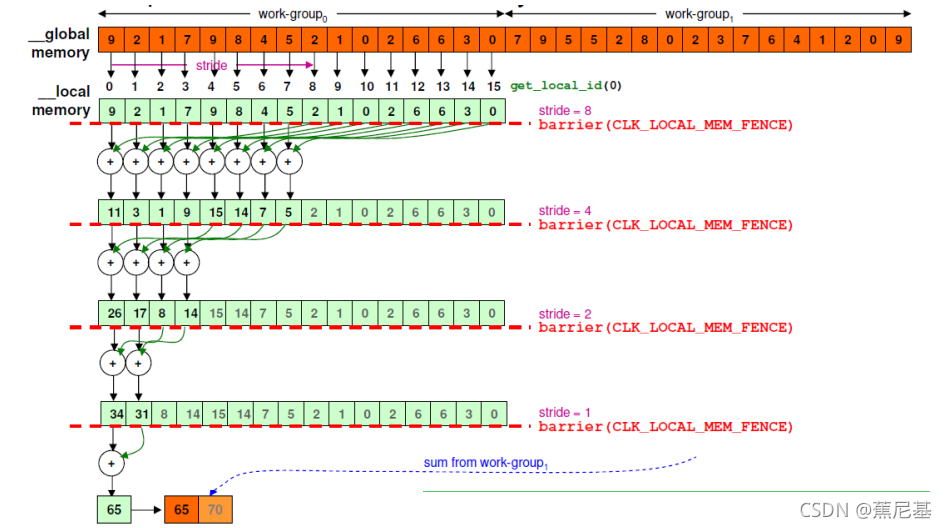
每次循环,都会做一次barrier操作,只到i不满足条件,即突出,那么最后每组数组就会产生一个值。
这个就是典型的reduction. 输入为数组,输出为一个标量。
output[get_group_id(0)] = partial_sums[0];
代码最后,将数据从local memry 赋值到share memry。 cpu即可读到数据。


















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











