







 KPCA(核主成分分析)作为PCA的非线性扩展,适用于处理非线性数据。通过非线性映射将数据映射到高维空间,并利用核函数处理样本之间的关系。本文介绍了KPCA的创新点、公式推导,并提供了一段MATLAB代码实现。
KPCA(核主成分分析)作为PCA的非线性扩展,适用于处理非线性数据。通过非线性映射将数据映射到高维空间,并利用核函数处理样本之间的关系。本文介绍了KPCA的创新点、公式推导,并提供了一段MATLAB代码实现。
KPCA,中文名称”核主成分分析“,是对PCA算法的非线性扩展。PCA是线性的,其对于非线性数据往往显得无能为力(虽然这二者的主要目的是降维,而不是分类,但也可以用于分类),其中很大一部分原因是,KPCA能够挖掘到数据集中蕴含的非线性信息。
一、KPCA较PCA存在的创新点:
1. 为了更好地处理非线性数据,引入非线性映射函数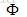
2. 引入了一个定理:空间中的任一向量(哪怕是基向量),都可以由该空间中的所有样本线性表示,这点对KPCA很重要,我想大概当时那个大牛想出KPCA的时候,这点就是它最大的灵感吧。话说这和”稀疏“的思想比较像。
二、公式推导
假设D(D >> d)维向量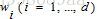
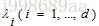
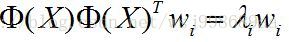
将特征向量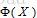
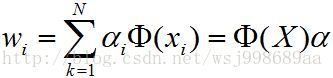
然后,在把

进一步,等式两边同时左乘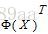
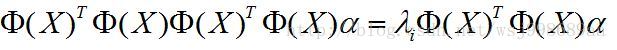
这样做的目的是,构造两个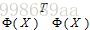
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 567
567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









