






目的:在实际训练中,模型通常对训练数据拟合程度较好,但是对训练数据之外的数据拟合程度差。为了得到可靠稳定的模型,用于评价模型的泛化能力,从而进行模型选择。
基本思想:把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set),首先用训练集对模型进行训练,再利用验证集来测试模型的泛化误差。另外,现实中数据总是有限的,为了对数据形成重用,从而提出k-折叠交叉验证。
对于分类或回归问题,假设可选的模型为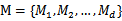 。k-折叠交叉验证就是将训练集的1/k作为测试集,每个模型训练k次,测试k次,错误率为k次的平均,最终选择平均率最小的模型Mi。
。k-折叠交叉验证就是将训练集的1/k作为测试集,每个模型训练k次,测试k次,错误率为k次的平均,最终选择平均率最小的模型Mi。
1、 将全部训练集 S分成 k个不相交的子集,假设 S中的训练样例个数为 m,那么每一个子 集有 m/k 个训练样例,,相应的子集称作 {s1,s2,…,sk}。
2、每次从分好的子集中里面,拿出一个![]() 作为测试集,其它k-1个作为训练集,
作为测试集,其它k-1个作为训练集,




3、由于每次留下一个

4、 选出平均经验错误率最小的

在matlab中部分代码如下:
indices=crossvalind('Kfold',x,k);
//来实现随机分包的操作,其中x为一个N维列向量(N为数据集A的元素个数,与x具体内容无关,只需要能够表示数据集的规模),k为要分成的包的总个数,输出的结果indices是一个N维列向量,每个元素对应的值为该单元所属的包的编号(即该列向量中元素是1~k的整随机数),利用这个向量即可通过循环控制来对数据集进行划分。例:
[M,N]=size(data);//数据集为一个M*N的矩阵,其中每一行代表一个样本
indices=crossvalind('Kfold',data(1:M,N),10);//进行随机分包
for k=1:10//交叉验证k=10,10个包轮流作为测试集
test = (indices == k); //获得test集元素在数据集中对应的单元编号
train = ~test;//train集元素的编号为非test元素的编号
train_data=data(train,:);//从数据集中划分出train样本的数据
train_target=target(:,train);//获得样本集的测试目标,在本例中是实际分类情况
test_data=data(test,:);//test样本集
test_target=target(:,test);
[HammingLoss(1,k),RankingLoss(1,k),OneError(1,k),Coverage(1,k),Average_Precision(1,k),Outputs,Pre_Labels.MLKNN]=MLKNN_algorithm(train_data,train_target,test_data,test_target);//要验证的算法
end














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









