







引言
神经网络的调参十分重要,很多人都说深度学习是一个黑箱模型,有人戏称深度学习为“炼丹”。但是深度学习归根结底是一个数学优化的过程,超参数对于模型的效果影响很大。网上文章也有很多,比如梯度爆炸应该怎么办,学习率怎么调整,选什么样的优化器等等。下面我就说一下自己的一些心得以及借鉴的别人的一些想法。
学习率的调整
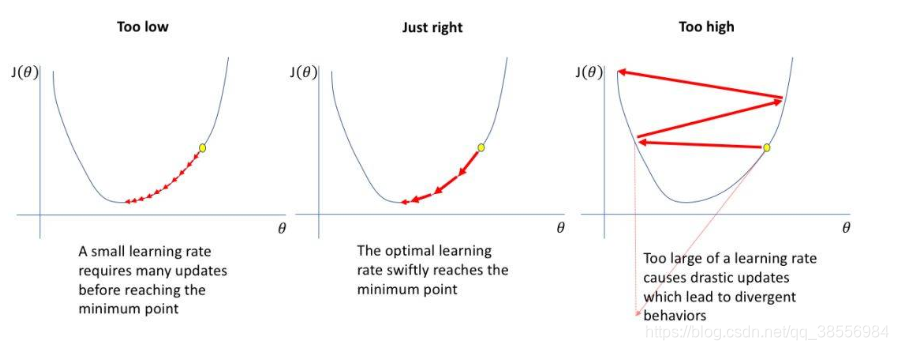
为了训练神经网络,其中一个需要设置的关键超参数是学习率。提醒一下,为了最小化此网络的损失函数,这个参数缩放了权重更新的幅度。如果你把学习率设置太低,训练会进展的很慢:因为你在网络的权重上只做了很少的调整。然而,如果你的学习率被设置的太高,它可能在你的损失函数上带来不理想的后果。我已经可视化了这些案例——如果你发现这些图很难理解,我建议你事先参考一下(至少)我此前发布的关于梯度下降的第一部分。
学习速率退火的最流行方式是「步衰减」(Step Decay),其中学习率经过一定数量的训练 epochs 后下降了一定的百分比。

通用的小技巧
- 激活函数。我们激活函数一般选择ReLU,另一种常见的激活函数是sigmoid,但是它不能再深度网络中很好的传播梯度。另外我们都默认不会在输出层中使用激活函数。
- 初始分布。对于初始化大家都偏爱使用常规的高斯分布、截断的正太分布,这里我们推荐下
variance-scaled初始化,variance scaling初始化根据每一层的输入或输出的数量来调整初始随机权重的方差,从而帮助信号更深入地传播到网络中。 - 梯度裁剪。梯度爆炸是深度学习中十分常见的现象,有时会导致寻优过程不收敛,或者算出来的结果干脆直接溢出,例如在Python里都是Nan,梯度裁剪是一种很好的解决方式。
- 预处理好你的数据。首先要归一化你的数据,。训练时,减去数据集的均值,然后除以其标准差。你的网络学习就会越快、越容易。注意训练数据归一化不要忘了也将测试数据归一化哦,保持一致!
- 不用过于重视滤波器个数。如果你已经有了大量的滤波器,那么添加更多的滤波器可能不会改善性能。
- 池化的意义。池化本质上是让网络学习图像“那部分”的“大意”。例如,最大池可以帮助卷积网络对图像中特征的平移、旋转和缩放变得健壮。
神经网络调试心得
这里我们主要是针对一些结果达不到期望进行调试,寻找BUG。注意我们进行一些调试时要用小规模数据集,小规模数据集,小规模数据集(重要问题说三遍)。
- 首先进行过拟合调试确保神经网络是合理的。首先要做的就是在单个数据样本上让网络过拟合。这样的话,准确度应该是 100%或 99.99%,或者接近于 0 的误差。如果你的神经网络不能对单个数据点进行过拟合,那么可能是体系结构出现严重问题。
- 改变Batch_size。当我们增大batch_size时,减少梯度更新中的方差,使每次迭代更精确,带BN的效果更好;当我们减小batch_size,可以提供与权重更新相关的更细粒度的反馈
- 更改学习率。降低学习率,虽然速度变慢,但它可能会进入一个以前无法进入的最小值,因为之前它的步长太大了。提高学习率,会加快收敛,但可能不稳定。
- BN的坑。在我以前的博客里介绍过了BN的坑。当网络存在一些问题或者梯度爆炸时,BN会掩盖这些问题,不方便你进行调试。
- 慎用reshape。剧烈的 reshaping(比如改变图像的 X、Y 维度)会破坏空间的局部性,使得网络更难学习。
- 可视化。我们可以可视化一些错误的case进行分析,另外loss也可以通过tensorboard等进行可视化。

















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









