









序列化在C#中运用的非常多,由于我是学Unity的,Unity中的序列化特性也比较常用,所以这篇文章我们讲讲序列化的用法。
在编码时,我们的代码中的对象们都是保存在内存中的。
如果我们关闭一个软件,那么里面的内容就随着进程的消失而消失了。我们之前保存一个类,可以使用反射来调用DLL库来生成一个这个类的对象。
但是如果说是代码中的对象的保存,就是需要用序列化相关的API来对代码中的对象进行保存和读取。在C#中它的名字叫Serializeable关键字和它们的特性。同样的,我们让一个对象序列化成了一个文件,那么在代码中也要读取它,所以与序列化相对应的就是反序列化。反序列化将一个数据流转化为一个文件。
序列化是将对象实例的状态存储到存储介质的过程,而反序列化则是序列化的补集。在这个过程中:
- 先将实例对象的公共字段和私有字段以及类的名称(包括类所在的程序集)转换为字节流。
- 将字节流写入为数据流。
- 反序列化时,创建出与原对象完全相同的副本。

序列化的特点:
1.持久存储:
我们如果非常直白的将对象的字段保存到磁盘中并在使用时检索,虽然不使用序列化也可以完成,但是这种方法很容易出错,尤其是目标对象的层次结构比较复杂的情况下。而在C#中,序列化很好的简化了这样的工作。
C#中的对象有CLR来管理在内存中的分布,dotNet框架通过使用反射提供自动的序列化机制。对象实例在序列化后,类的名称、程序集、以及类的所有数据成员都被写入到存储媒体(二进制、XML、JSON)中。对象常常用成员变量来实现对其他实例的引用。
类序列化后,CLR将跟踪所有已序列化的引用对象,以确保同一对象不被序列化多次。
dotNet框架所提供的序列化体系结构可以自动正确处理对象图表和循环引用。
2.按值封送:
一般说来,一个实例对象仅在创建对象的应用程序域中有效。但是如果将一个对象的类标记为Serializeable。通过很简单的代码可以将该类自动序列化,并可以从一个应用程序域传递到另外一个应用程序域,然后再进行反序列化。
这样就可以在另外一个应用程序域中产生出该对象的一个精确副本。这样的过程称为按值封送。
Serializeable与NonSerialized
当我们要标记一个类可以序列化的时候,最基本的方法是使用[Serializable]进行标记。
格式转换器:
然后指定一段逻辑来进行序列化和反序列化操作。当我们指定序列化与反序列化的路径时,要创建格式转换器来进行序列化,在C#中可供选择的格式转换器为:
- 二进制序列化 BinaryFormater:对保存类型保真,适用于不同的应用程序之间保留对象的状态。可以在不同程序之间共享对象。与下面的两个转换器不同的是,它对于对象中的private字段也会进行序列化。
- XML和Soap序列化 SoapFormatter:只会序列化公共属性和字段,并且不会保留类型保真。适用于不限制读取程序的应用程序时非常有用。
- JSON序列化:只序列化公共属性,不会保留类型的保真。
由于XML和JSON是开放式标准,所以用于在Web中数据共享是非常好的选择。
选择性序列化:
我们的代码中并不是所有的字段都需要序列化,我们如果需要有某个字段对象不进行序列化,就可以使用[NonSerialized]关键字来“屏蔽”不要被序列化的字段。
我们在接下来的例子中都使用二进制序列化。
先写一个小例子,我们定义一个类进行序列化里面有ID、姓名、性别,并且设定Sex不能序列化:
class Program
{
static void Main()
{
SerializeClass<ClassToSerialize> serialClass = new SerializeClass<ClassToSerialize>();
ClassToSerialize example1 = new ClassToSerialize()
{
id = 22,
name = "xsy",
Sex = "男"
};
serialClass.SerializeNow(example1);
ClassToSerialize example2 = serialClass.DeSerializeNow();
Console.WriteLine("此时序列化后的ID为:"+example2.id+"序列化后的名字为:"+example2.name);
if(example2.Sex==null)
{
Console.WriteLine("此时Sex没有被序列化");
}
}
}
[Serializable]
public class ClassToSerialize
{
public int id;
public string name;
[NonSerialized]
public string Sex;
}
public class SerializeClass<T>
{
public void SerializeNow(T instance)
{
FileStream stream = new FileStream("C:\\Users\\熊思远\\Desktop\\temp.dat", FileMode.Create);
BinaryFormatter binary = new BinaryFormatter();
binary.Serialize(stream, instance);
stream.Dispose();
stream.Close();
}
public T DeSerializeNow()
{
FileStream fileStream = new FileStream("C:\\Users\\熊思远\\Desktop\\temp.dat", FileMode.Open, FileAccess.Read, FileShare.Read);
BinaryFormatter b = new BinaryFormatter();
T example = (T)b.Deserialize(fileStream);
fileStream.Dispose();
fileStream.Close();
return example;
}
}结果是显而易见的:
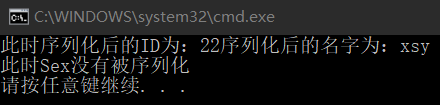
C#中绝大部分的官方类型都可以被序列化,我们可以从微软官方文档查看一个字段类型是否可以序列化。
序列化实现深拷贝
当我们在复制一个值类型字段的时候,例如int a=b,那么b中的值将会复制到a中,在复制之后a与b即毫无关系了,这样复制之后完全克隆的情况称为深拷贝。
当我们复制一个引用类型字段的时候,例如ExampleClass a=b,那么实际上a复制到b中的实际为a所指向的托管堆中的内存地址,此时当我们修改a中的字段,b中的字段也会随之改变,这个在我们之前讲述值类型与引用类型的时候就讲过了。
这种:复制对象仅仅复制一个指向同一个内存地址引用的操作,称为浅拷贝。
那么,我们如果要对引用类型进行深拷贝要如何操作呢,序列化可以帮我们实现这个操作。
C#中,专门有定义一个实现拷贝的接口:ICloneable
使用Object的浅引用表进行浅拷贝
在C#的“老大哥”Object类中,可以通过一个函数来返回该类的浅引用:

我们在使用ICloneable实现Clone函数时,这个时候可以这样书写:
class Program
{
static void Main()
{
TestArray testArray1 = new TestArray()
{
t=111;
array = new int[3] { 44, 33, 22 },
i = "aaa"
};
TestArray testArray2 = (TestArray)testArray1.Clone();
testArray2.array[1] = 456;
testArray2.i = "bbb";
t=12345;
Console.WriteLine("输出的原来的数组是");
foreach (int t in testArray1.array)
{
Console.Write(t.ToString() + " ");
}
Console.WriteLine(" ");
Console.WriteLine(testArray1.i+testArray1.t);
Console.WriteLine("此时的testArray1的哈希码是" + testArray1.GetHashCode() + " 此时testArray2的哈希码是" + testArray2.GetHashCode());
}
}
[Serializable]
class TestArray : ICloneable
{
public int t;
public string i;
public int[] array;
public object Clone()
{
return this.MemberwiseClone();
}
}此时我们输出testArray1的字段,可以看出这里是:
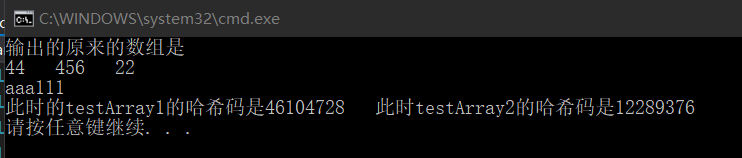
可以看出,复制一个类对象使用Object.MemberwiseClone()时,创建了一个新的实例来存放返回的Object类型的值(二者哈希码不同),对类中除了值类型和字符串类型以外的所有字段进行浅拷贝(数组的值改变了而值类型t和字符串i都没有变化)。
引用类型使用“=”拷贝
这与我们直接进行TestArray testArray2 = testArray1;是不一样的,这样直接的“=”引用复制会将值类型和字符串类型都指向同一个地址。我们将上面的调用克隆函数的指令改为直接等于:
//TestArray testArray2 = (TestArray)testArray1.Clone();
TestArray testArray2 = testArray1;这样的效果就是:
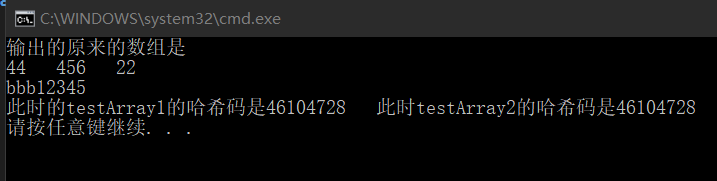
两个哈希码完全一致,说明是指向了同一个内存地址。而类中的引用类型的值也发生了变化。
那么,要在类中实现深拷贝,可以使用序列化的手段进行深拷贝,我们对上文中的例子进行改进:
class Program
{
static void Main()
{
TestArray testArray1 = new TestArray()
{
t = 111,
array = new int[3] { 44, 33, 22 },
i = "aaa"
};
TestArray testArray2 = (TestArray)testArray1.Clone();
testArray2.array[1] = 456;
testArray2.i = "bbb";
testArray2.t = 12345;
Console.WriteLine("输出的原来的数组是");
foreach (int t in testArray1.array)
{
Console.Write(t.ToString() + " ");
}
Console.WriteLine(" ");
Console.WriteLine(testArray1.i + testArray1.t);
Console.WriteLine("此时的testArray1的哈希码是" + testArray1.GetHashCode() + " 此时testArray2的哈希码是" + testArray2.GetHashCode());
}
}
[Serializable]
class TestArray : ICloneable
{
public int t;
public string i;
public int[] array;
public object Clone()
{
return SerializeClass<TestArray>.getDeepClone(this);
}
}
class SerializeClass<T>
{
public static T getDeepClone(T getInstance)
{
using (MemoryStream stream = new MemoryStream())
{
BinaryFormatter binary = new BinaryFormatter();
binary.Serialize(stream, getInstance);
stream.Position = 0;
T returnInstance = (T)binary.Deserialize(stream);
return returnInstance;
}
}
}这样通过序列化一进一出就实现了一个类的深度拷贝,在堆内存中生成了一个与原来的对象完全无关的副本,这个时候我们看结果:
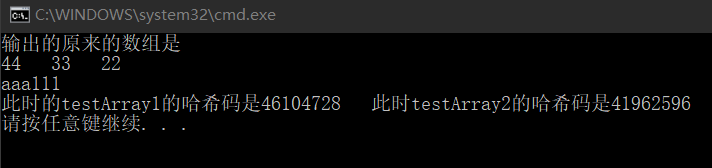
二者的字段完全不同,即使用了序列化实现了深拷贝的功能。
注意:虽然引用类型在平时普通复制时都是浅拷贝,但属于引用类型的字符串string在复制时和值类型的效果一致,这个要当做一个特殊的情况看待。
在上文中使用了using语句对特定的非托管对象进行了生命周期的管理,using语句使被管理对象(在上文中是MemoryStream)的生存周期只存在于花括号内,当花括号内的逻辑执行完毕,将对被管理的对象执行Dispose方法,释放其内存。
自定义序列化 ISerializeable
序列化虽然好用,但是使用它进行版本控制却是不容易,例如,当我们一个对象序列化保存了以后,如果当时序列化前的某些值因为代码逻辑造成了修改,那么需要精确控制执行序列化前和执行序列化后的逻辑操作,为此,C#中引入了ISerializeable。
ISerializeable接口中实现了一个GetObjectData方法,为了形象一点,我们把这个方法称为代理选取器:

在GetObjectData方法中,默认有两个参数:
SerializationInfo:将序列化时所有字段通过它的实例来保存,保存的格式时类似于哈希表。通过关键字实现保存。
StreamingContext:在创建格式化转换器时调用这个参数,表明源和目标序列化数据。
我们尝试写一个序列化字典的方法, 这个例子来源于Unity 的API文档,我自己做了一点点修改:
class Program
{
static void Main()
{
SerialClass<DictionarySerialize> serial = new SerialClass<DictionarySerialize>();
DictionarySerialize dicSet = new DictionarySerialize();
dicSet.myDictionary.Add(11, "A");
dicSet.myDictionary.Add(12, "B");
dicSet.myDictionary.Add(13, "CD");
serial.SerializeFunc(dicSet);
DictionarySerialize dicGet = serial.DeserializeFunc();
foreach (var i in dicGet.myDictionary)
{
Console.WriteLine("当前输出为" + i.Key + i.Value);
}
}
}
public class SerialClass<T>
{
public void SerializeFunc(T dicSet)
{
BinaryFormatter binary = new BinaryFormatter();
FileStream stream = new FileStream("C:\\Users\\熊思远\\Desktop\\\\temp3.dat", FileMode.Create);
binary.Serialize(stream, dicSet);
stream.Close();
}
public T DeserializeFunc()
{
BinaryFormatter binary = new BinaryFormatter();
FileStream stream = new FileStream("C:\\Users\\熊思远\\Desktop\\\\temp3.dat", FileMode.Open, FileAccess.Read, FileShare.Read);
T returnValue = (T)binary.Deserialize(stream);
stream.Dispose();
return returnValue;
}
}
[Serializable]
public class DictionarySerialize : ISerializable
{
public List<int> Savekeys = new List<int>();
[NonSerialized]
public Dictionary<int, string> myDictionary = new Dictionary<int, string>();
public DictionarySerialize()
{ }
public DictionarySerialize(SerializationInfo info, StreamingContext context)
{
Savekeys = (List<int>)info.GetValue("SaveKeys", typeof(List<int>));
for (int t = 0; t < Savekeys.Count; t++)
{
myDictionary.Add(Savekeys[t], info.GetValue(Savekeys[t].ToString(), typeof(string)).ToString());
}
}
public void GetObjectData(SerializationInfo info, StreamingContext context)
{
foreach (KeyValuePair<int,string> i in myDictionary)
{
Savekeys.Add(i.Key);
}
info.AddValue("SaveKeys", Savekeys);
foreach (var i in Savekeys)
{
info.AddValue(i.ToString(), myDictionary[i]);
}
}
}输出的结果为:
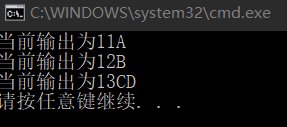
当我们对类引入自定义序列化接口的时候,该类对象在序列化的时候步骤如下:
- 检查对象的类中是否有GetObjectData方法,如果存在该方法,再检查该方法是否处理指定需要序列化类型的对象。如果满足,则将在序列化时调用GetObjectData方法。
- 在反序列化时,将会调用类中与GetObjectData参数列表一致的类构造函数,以便将类中的字段送入新的对象实例中。
由于这里使用了ISerializable接口的原因,即使我们使用了[Serializable]特性,但每个字段的值不会为我们保存,我们需要手动的进行每个需要序列化的值对SerializationInfo进行导入,以此来保证在每个需要序列化的字段都进行了序列化。
我们使用ISerializable时既然会在序列化时调用,所以也必须对应地设置一个反序列化时需要使用的构造函数,为了使对象在通常情况下不会起冲突,最好还在类中加入一个重载的构造函数。如果类中没有指定一个专用于自定义序列化的构造函数,那么在反序列化结束的时候将会出现异常。
在使用自定义序列化时,需要注意在继承链上的序列化产生的问题:
对于类继承, 父类和子类都需要实现ISerializeable接口。而且在这种情况下, 派生类应在其GetObjectData中调用基类的实现,即Base.GetObjectData()。 否则, 基类中的数据将不会序列化。
序列化中的其他可使用特性:
[OnSerializing]:应用OnSerializingAttribute特性的方法,将会在序列化期间自动被调用。
[OnSerializied]:应用OnSerializedAttribute特性的方法,将会在序列化之后自动被调用。
[OnDeserializing]:应用OnDeserializingAttribute特性的方法,将会在被序列化期间自动被调用。
[OnDeserializied]:应用OnDeserializedAttribute特性的方法,将会在被序列化之后自动被调用。
注意,以上四个特性都只能用于方法,并且在类中表示应用特性的方法必须包含一个StreamingContext参数。
Unity中的序列化
在Unity中,序列化是一个很重要的一环,例如在Unity中有一个很便捷的功能,在脚本中以Public形式标注的对象将会暴露在Inspector面板中,这个里面就用到了序列化。
Unity中序列化除了C#的序列化功能以外,还引入了[SerializeFiled]特性和[NonSerialized]特性。
在官方的注释中,[SerializeFiled]的存在意义是:强制序列化私有字段。
与之相对的,[NonSerializeFiled]可以理解成:强制不序列化公有字段。

需要注意的是,我们不能把Unity中的序列化等同于C#中的序列化,二者具有非常大的区别,但是Unity中仍然可以使用C#的序列化方法进行字段的存取,但是C#的序列化方式与Unity内置的序列化并不能看做一样的东西。
Unity序列化使用场景:
保存和加载:Asset和AssetBundle的保存和加载中,对于从硬盘或内存中的对象的存取就用到了序列化,这也包括API中的对象。仅在编辑器或播放测试模式下执行。
热重装:当我们更改并保存脚本时,Unity会及时的重新加载所有当前已加载的脚本数据。它首先将所有可序列化的变量存储在所有已加载的脚本中,并在加载脚本后将其还原。这个过程Unity称为:热重装。当热重装发生后,所有的不可序列化的数据都会丢失。当脚本序列化后Unity将public的字段暴露在Inspector面板中显示。在显示字段的值的时候,并不会与字段的脚本脚本进行通信。这一点很显而易见,若一个脚本的公有的字段带有一个封装它的属性,属性即使是public也不会暴露在Inspector中,并且此时在面板中修改这个公有字段也是不会调用属性的。
Prefab:Unity中的Prefab实际上是Unity经过序列化生成的资源文件,当我们使用Instaniate函数在场景中克隆出一个预制体的时候,实际上的过程是:
- 将指定的GameObject所引用的游戏对象序列化,得到序列化后的序列化流Stream。
- 使用反序列化机制将序列化流反序列化,生成一个新的游戏对象GameObject。
这样的方式即为我们在上文中讲到的使用序列化实现的深拷贝,每次克隆的一个游戏对象都在一个新的内存空间中,而不是一个引用地址中。这样能有效地防止生成多个对象后浅拷贝带来的修改数据和调试的复杂度。
Unity序列化要求:
- 使用public或者使用了[SerializeField]特性。
- 静态static、const、readonly来修饰的都不行。
- 表示为可序列化的类型
其中,可序列化的类型又有:
- 自定义的、使用[Serializeable]修饰的非抽象类(引用类型)。
- 自定义的、使用[Serializeable]修饰的结构体(值类型)。
- 所有派生自UnityEngine.Object的类型。
- C#的基本元素类型(int、float、double、bool、string)等。
- 元素类型为以上四种的Array和List<T>。
- Unity中的一些内置类型:
Vector2,Vector3,Vector4,Rect,Quaternion,Matrix4x4,Color,Color32,LayerMask,AnimationCurve,Gradient,RectOffset,GUIStyle等
Unity中的自定义序列化
同样的,在Unity中遇到了不可序列化的类型,我们同样需要自定义序列化,在C#可以使用ISerializeable接口的基础上,Unity官方也指定了ISerializationCallbackReceiver来在Unity中自定义序列化。

其中包含两个方法:
-
OnAfterDeserialize:实现此方法以在Unity反序列化对象后接收回调。
-
OnBeforeSerialize:实现此方法以在Unity序列化对象之前接收回调。
例如,在Unity中,字典的元素是不能通过Unity序列化[SerializeField]来序列化的(在C#中可以),这个时候可以使用我们写一个Unity自定义序列化的例子:
using System;
using System.Collections.Generic;
using UnityEngine;
public class CSharpTest :MonoBehaviour,ISerializationCallbackReceiver
{
public List<int> keys = new List<int> { 3, 4, 5 };
public List<string> values = new List<string> { "AA", "BB", "CC" };
public Dictionary<int, string> myDictionary = new Dictionary<int, string>();
void Start()
{
foreach(KeyValuePair<int,string> i in myDictionary)
{
Debug.Log("i已经被序列化了" + i.Value);
}
}
public void OnBeforeSerialize()
{
keys.Clear();
values.Clear();
foreach (var kvp in myDictionary)
{
keys.Add(kvp.Key);
values.Add(kvp.Value);
}
Debug.Log("在序列化前被调用,用于装载字典元素");
}
public void OnAfterDeserialize()
{
myDictionary = new Dictionary<int, string>();
for (int i = 0; i != Math.Min(keys.Count, values.Count); i++)
{
myDictionary.Add(keys[i], values[i]);
}
Debug.Log("在序列化后被调用,用于填充字典元素");
}
}我们运行游戏,可以看到有如下情况:

由于Unity中的C#脚本都是在定义脚本后随着脚本参数的变化而变化,而每次变化Unity都会将脚本序列化以显示在Inspector面板上,所以,我们可以看到ISerializationCallbackReceiver的两个方法在游戏运行后被调用了多次。
参考文档:
https://www.cnblogs.com/dazhong/archive/2007/04/09/705465.html
https://docs.microsoft.com/zh-cn/dotnet/csharp/programming-guide/concepts/serialization/
https://docs.unity3d.com/Manual/script-Serialization.html
https://www.cnblogs.com/devhyj/p/4342592.html















 715
715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









