







注意力机制
注意力机制主要分为两块,一块是基于通道的注意力机制,另一种是基于空间的空间注意力机制。结合二者的CBAM等。最近又有人提出Pixel Attention。这种方案我之后来讲。注意力机制的实际原理是通过特征图来计算特征图在通道和空间上的重要性。如果将获取的权重叠加到卷积的kernel上就构成了动态滤波。方便对比理解所以将二者放到一起。
基于通道的注意力机制
基于通道的注意力机制比较经典的如SE-Net上用到的通道加权方式。
1、对特征实现全局平均池化得到一维权重向量。
2、一维权重向量通过全连接和激活层等学习最终的权重向量。
3、将学习的权重向量对原来的特征实现加权。

图1、通道加权的过程
示意代码如下:
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
if __name__=="__main__":
x = torch.randn((1,64,32,32))
CA = ChannelAttention(in_planes=64)
cw = CA(x)
result = cw*x
基于空间的注意力机制
空间注意力机制,强调的是特征在空间分布上比较重要的区域:
1、计算特征的均值map和最大值map。
2、级联均值map和最大值map,将合并的特征送入卷积层学习得到空间权重再经过激活函数得到权重图。
3、空间权重图和特征图逐元素相乘。

图2、空间注意力机制实现流程。我们简单的看看代码:
import torch
import torch.nn as nn
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x,1).unsqueeze(1)
max_out, _ = torch.max(x,1)[0].unsqueeze(1)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
if __name__=="__main__":
x = torch.randn((1,64,32,32))
SA = SpatialAttention(kernel_size=3)
sw = SA(x)
result = sw*x
结合空间和通道的注意机制研究人员提出了CBAM:
CBAM的整体框架如下图3所示:

直接将通道和空间注意力机制级联构成的,网络并没有考虑维度间的信息交互,为了改善这个问题,人们提出了Pixel Attention(像素级注意力机制)triplet Attention等。
Triplet Attention见下图所示。Triplet Attention由3个平行的Branch组成,其中两个负责捕获通道C和空间H或W之间的跨维交互。最后一个Branch类似于CBAM,用于构建Spatial Attention。最终3个Branch的输出使用平均进行聚合。

简单的代码如下所示:
import torch
import torch.nn as nn
#z-pool
class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat((torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=11)
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes,eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1 )
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
kernel_size = 7
self.compress = ChannelPool()
self.spatial = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2, relu=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.spatial(x_compress)
scale = torch.sigmoid_(x_out)
return x * scale
class TripletAttention(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max'], no_spatial=False):
super(TripletAttention, self).__init__()
self.ChannelGateH = SpatialGate()
self.ChannelGateW = SpatialGate()
self.no_spatial=no_spatial
if not no_spatial:
self.SpatialGate = SpatialGate()
def forward(self, x):
x_perm1 = x.permute(0,2,1,3).contiguous()
x_out1 = self.ChannelGateH(x_perm1)
x_out11 = x_out1.permute(0,2,1,3).contiguous()
x_perm2 = x.permute(0,3,2,1).contiguous()
x_out2 = self.ChannelGateW(x_perm2)
x_out21 = x_out2.permute(0,3,2,1).contiguous()
if not self.no_spatial:
x_out = self.SpatialGate(x)
x_out = (1/3)*(x_out + x_out11 + x_out21)
else:
x_out = (1/2)*(x_out11 + x_out21)
return x_out
# 全局注意力机制:
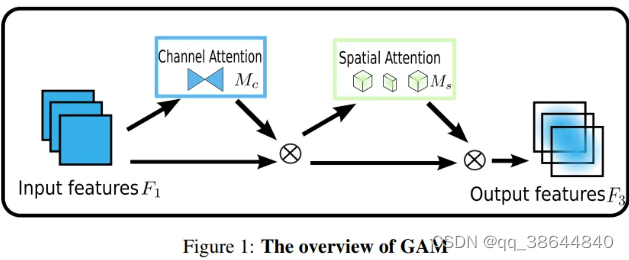
```python
class GAM_Attention(nn.Module):
def __init__(self, in_channels, out_channels, rate=4):
super(GAM_Attention, self).__init__()
self.channel_attention = nn.Sequential(
nn.Linear(in_channels, int(in_channels / rate)),
nn.ReLU(inplace=True),
nn.Linear(int(in_channels / rate), in_channels)
)
self.spatial_attention = nn.Sequential(
nn.Conv2d(in_channels, int(in_channels / rate), kernel_size=7, padding=3),
nn.BatchNorm2d(int(in_channels / rate)),
nn.ReLU(inplace=True),
nn.Conv2d(int(in_channels / rate), out_channels, kernel_size=7, padding=3),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
b, c, h, w = x.shape
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)
x_channel_att = x_att_permute.permute(0, 3, 1, 2)
x = x * x_channel_att
x_spatial_att = self.spatial_attention(x).sigmoid()
out = x * x_spatial_att
return out
动态滤波:
关于动态滤波实际上也将SE-Net的注意力模块的权重作用于用于卷积的卷积核而非特征图。由于权重的信息来自于特征图,这样导致滤波核与输入是相关的。因此,称为动态滤波。在我的另外一篇博客里面有简单的介绍了。这里就不再赘述了。Dynamic Convolution


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









