







首先祭出这张经典的Transformer模型架构图(以下简称架构图),让我们一步步去理解。
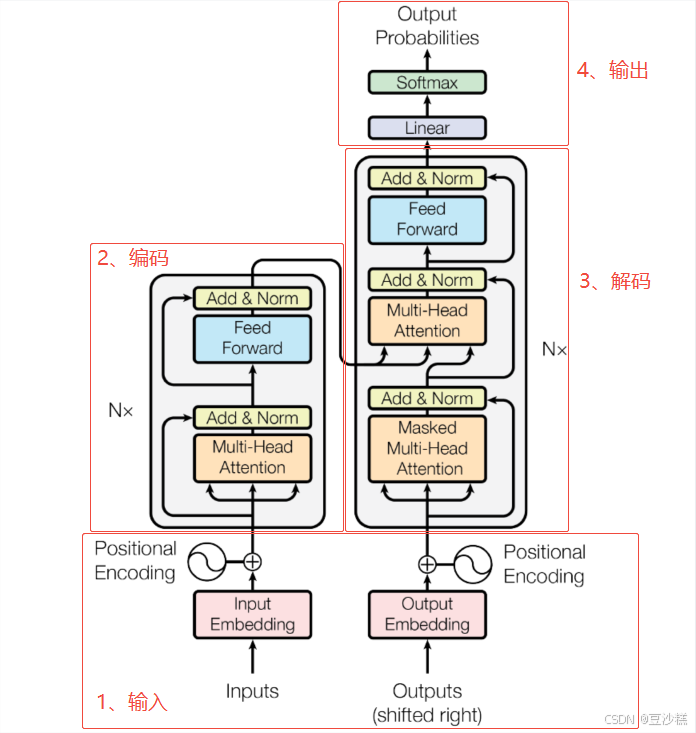
简单点来看,可以划分成四个部分,输入层(分两部分【原始样本:'你好吗',目标标签:'我很好'】)、编码组件(Encoders)、解码组件(Decoders) 、输出层 组成,以及他们之间的连接组成。
一、输入层(词嵌入+位置编码)
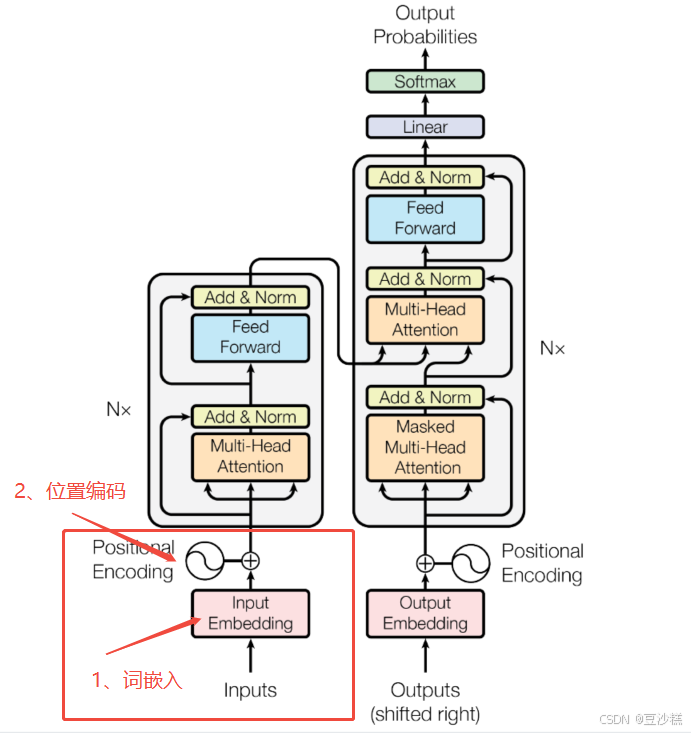
1.1 词嵌入
输入序列:["[CLS]", "你", "好", "吗", "[SEP]"]
- 分词结果:通过BPE分词转为索引
[1, 254, 876, 3452, 2] - 词嵌入矩阵如下(前4维示例):
[CLS] → [0.2, -0.8, 1.1, 0.5, ...] # 形状(5,512) 你 → [0.3, -1.2, 0.8, 0.7, ...] 好 → [-0.5, 1.4, 0.2, -0.3, ...] 吗 → [1.1, 0.6, -0.9, 0.4, ...] [SEP] → [0.7, -0.1, 1.2, -0.5, ...]
这部分就是将词转换成词向量,没什么特别的。
1.2 位置编码注入
位置编码公式:
PE(pos,2i) = sin(pos/10000^(2i/512))
PE(pos,2i+1) = cos(pos/10000^(2i/512))pos表示词的位置,i 表示位置编码的位置。位置编码的维度和词嵌入矩阵的维度是一样的。
例如,‘你’ 这个词的位置编码如下:
红色表示词的位置,绿色的是位置编码的位置,一共512维。
[sin(1/10000^(2*0)/512),cos(1/10000^(2*0)/512),sin(1/10000^(2*1)/512),cos(1/10000^(2*1)/512),..... sin(1/10000^(2*255)/512),cos(1/10000^(2*255)/512)]
各位置前4维和512维的编码值如下:
| 位置 | 完整512维位置编码(前4维 + 中间... + 第512维) |
|---|---|
0([CLS]) | [0.0, 1.0, 0.0, 1.0, ..., 1.0] |
| 1(你) | [0.8415, 0.5403, 0.824, 0.566, ..., 0.999999995] |
| 2(好) | [0.9093, -0.4161, 0.935, -0.354, ..., 0.999999982] |
| 3(吗) | [0.1411, -0.9899, 0.262, -0.965, ..., 0.999999953] |
4([SEP]) | [-0.7568, -0.6536, -0.650, -0.760, ..., 0.999999914] |
将词嵌入矩阵+位置编码矩阵作为最终输入矩阵X,示例如下:
X = Embedding + PE
[CLS] → [0.2+0.0, -0.8+1.0, 1.1+0.0, 0.5+1.0, ...] = [0.2, 0.2, 1.1, 1.5, ...]
你 → [0.3+0.8415, -1.2+0.5403, 0.8+0.824, 0.7+0.556, ...] = [1.1415, -0.6597, 1.624, 1.256, ...]
其他词同理...1.3、为什么要位置编码?
在Transformer等基于自注意力机制的模型中,位置编码(Positional Encoding)是解决模型天然无位置感知缺陷的核心技术,其必要性体现在以下三个方面:
1. 突破自注意力的位置盲区
自注意力机制通过计算所有词元对的关联权重实现全局交互,但这一过程天然忽略词元顺序。例如:
- 句子A:"猫追老鼠"
- 句子B:"老鼠追猫"
两句话的注意力计算结果完全相同,但语义完全相反。位置编码通过为每个位置赋予独特标识,使模型能区分顺序差异。
2. 弥补并行计算的代价
与传统RNN逐词处理不同,Transformer的并行计算牺牲了序列顺序信息。位置编码通过显式注入位置信号,在保持并行效率的同时恢复序列结构。Transformer的并行性体现在同一句子内所有token的同时处理,而非逐词处理。自注意力机制允许模型同时计算所有位置的关系权重。例如,处理句子"我爱自然语言处理"时,所有7个token同时参与计算,而非像RNN逐个传递。
3. 支持可变长序列建模
相比RNN的递归结构,位置编码允许模型处理任意长度输入(如长文档或语音片段),且不受梯度消失/爆炸问题影响。
-
RNN的局限性:
- 理论支持任意长度:RNN通过循环结构逐步处理序列。
- 实际限制:梯度消失/爆炸导致长序列训练困难(如1000词以上的文本)。例如,RNN在训练长文本时,梯度可能指数级衰减,无法有效更新参数。
-
Transformer的优势:
- 位置编码解耦长度限制:通过固定公式计算位置信号,避免递归结构。如图片中的位置4编码独立于其他位置生成,而RNN的后续参数更新依赖于之前位置的参数。
- 自注意力的全局访问:无论序列多长,任意两个token可直接交互,无需通过多步传递。
1.4、位置编码公式的设计原理
1. 为什么选择三角函数?
三角函数的周期性和平滑性是位置编码的理想特性:
- 多频率:覆盖从字词到段落的多种关系,按照公式,i 较小时,两个词之间的位置编码差值较大(可由上面位置编码示例图看出),可表达邻近词之间强相关,i 较大时,两个词之间的位置编码差值较小(可由上面位置编码示例图看出),可表达距离较远,例如跨段落的词之间弱相关。这种设计使Transformer既能处理"动词必须紧跟主语"的局部约束,又能识别"文章开头与结尾"的远距离关联,成为自然语言处理的里程碑技术。
- 绝对位置:每个词的位置编码唯一
- 相对位置:通过比较各个词的位置编码差值,自动识别词之间的位置距离。
- 平滑性:连续可导的函数形式便于模型通过线性变换学习位置相关性。位置编码与词嵌入通过加法融合(如
Embedding + PE),可导性确保梯度能反向传播至两者。例如,位置1的编码0.8415与对应词向量相加后,梯度可同时更新词向量和位置参数。
数学优势:
三角函数(正弦/余弦)的线性变换性质源于其加法公式:
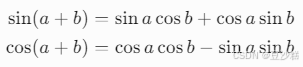
这意味着,位置编码可通过线性组合(矩阵乘法)表示相对位置偏移。例如,若已知位置pos的编码PEpos,则位置pos+k的编码可表示为:
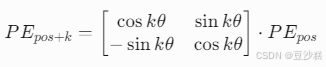
对模型训练的实际意义
-
梯度反向传播的稳定性:
- 三角函数连续可导,与词嵌入相加后(如
词向量 + [0.8415, 0.5403, ...]),梯度可无损传递至所有参数。 - 图片示例:位置1的编码值
0.8415与词嵌入相加后,反向传播时梯度会同时调整词向量权重和后续注意力层的变换矩阵。
- 三角函数连续可导,与词嵌入相加后(如
-
参数高效性:
模型无需为每个位置单独学习参数,而是通过 注意力机制中的Q/K/V矩阵(后续介绍) 隐式学习相对位置的线性变换规则。例如: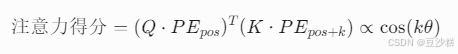
这一设计大幅减少了参数量,使Transformer能处理任意长度输入。
2. 为什么用 pos/100002i/512?
公式中的指数项控制不同维度的波长,其设计逻辑如下:
-
维度分频:
将512个维度分为256组(每组含一个正弦和一个余弦维度),每组对应不同频率信号: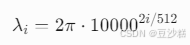
其中:
- 高频维度(i小):波长短(如i=0时λ=2π),捕捉局部位置细节。
- 低频维度(i大):波长极长(如i=255时λ≈20000π),编码全局位置趋势。
-
基数10000的意义:
通过指数底数调整频率跨度,确保从高频到低频的平滑过渡,覆盖从字符级到段落级的多种位置关系。
3. 为什么交替使用sin和cos?
通过奇偶维度交替使用正弦和余弦函数,可以形成正交基底,进而增强位置信息密度
正交基底就像一套完美的“坐标尺”,它由一组相互垂直且互不干扰的向量组成。
- 维度0(i=0):sin(pos/100000/512)=sin(pos)
- 维度1(i=0):cos(pos/100000/512)=cos(pos)
- 维度2(i=1):sin(pos/100002/512)
- 维度3(i=1):cos(pos/100002/512)
(后续维度同理交替)
对于同一频率的正弦和余弦函数(如维度0和1),其内积在周期内积分为0:
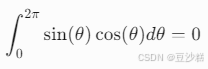
这意味着这两个维度的信号互不干扰,就像XY坐标轴垂直一样。
为什么正交基底能增强位置信息密度?
1. 信息互补
-
同一频率的双重表达:
如位置1的维度0(sin(1)=0.8415)和维度1(cos(1)=0.5403)共同描述位置1的完整相位信息。
类比:用经度和纬度共同定位一个地点,比只用单一坐标更精确。 -
抗信息丢失:
若某一维度因噪声受损(如维度0被干扰),维度1仍能保留位置特征。
2. 维度高效利用
这四个轴互相垂直(正交),每个轴的信息独立存在,互不干扰。这就是正交基底的稀疏性——每个维度只负责一个独立特征,没有重复或重叠的信息。
- 正交基底的稀疏性:
想象你有一把四维的尺子,这把尺子有四个刻度方向(X/Y/Z/W轴),每个方向的刻度完全独立:
- X轴:只测量东西方向的距离
- Y轴:只测量南北方向的高度
- Z轴:只测量垂直方向的深度
- W轴:只测量时间维度的变化
- 每个维度独立承载信息,无冗余。例如:
- 位置1的维度0与位置2的维度0差异显著(0.8415→0.9093)
- 位置1的维度1与位置2的维度1剧烈变化(0.5403→-0.4161)
这种差异最大化设计使模型更易区分不同位置。
1.5、公式设计的延伸意义
1. 波长范围的控制
- 当i=0时,波长最小(2π),适合捕捉相邻词元关系(如句法结构)。
- 当i=255时,波长最大(约6万词长度),可处理长文档的篇章结构。
2. 与词向量空间的兼容性
位置编码与词嵌入通过加法融合,而非拼接,确保了:
- 位置信号与语义信号的解耦学习。
- 模型通过参数自动调节位置与语义的权重平衡。
通过这种精巧的设计,Transformer的位置编码实现了:
- 绝对位置标识(每个位置有唯一编码)
- 相对位置学习(通过注意力机制隐式捕获)
- 多尺度感知(高频与低频信号结合)
后续研究(如相对位置编码、旋转位置编码)均基于这一基础框架的改进,但核心思想仍延续了三角函数编码的优越性。
补充:
1、位置编码的生成公式是预定义的数学函数,而非可训练参数。模型在处理输入时,直接将词嵌入与对应位置的编码相加,而非通过其他参数计算
模型通过三角函数的线性组合特性(如和差公式)捕捉词序关系,而非依赖参数学习
2、正弦函数的导数为余弦函数(d/dxsin(x)=cos(x)),余弦函数的导数为负的正弦函数(d/dxcos(x)=−sin(x))。这些导数本身仍是连续且平滑的三角函数,不存在突变或不可导点。
平滑梯度传递:反向传播中,梯度通过链式法则逐层传递。若位置编码的导数存在突变(如分段函数),会导致梯度陡峭甚至爆炸;而三角函数的平滑导数确保了梯度的连续变化,避免了此类问题。
=================================================
二、编码器
先看下编码器结构:
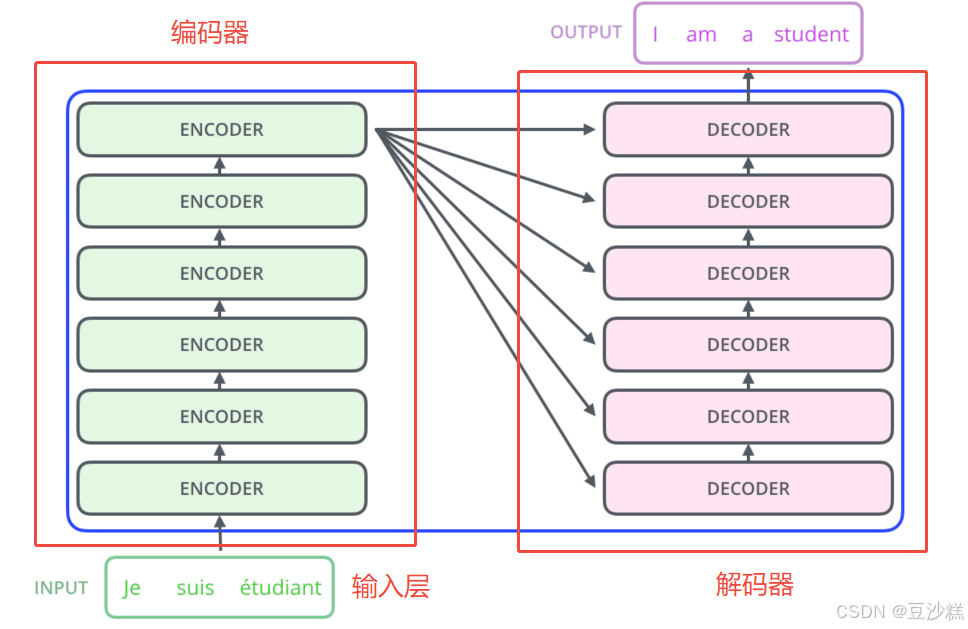
可以发现编码组件和解码组件又由若干个相应的编码器(Encoder)和解码器(Decoder)组成,编码器之间是串联的,解码器之间也是串联的,所有解码器层均使用编码器最后一层(第6层)的输出作为输入。原文中这里编码器和解码器为的数目为6个(架构图中的 N× 中的 N 即为这里的个数),这个数目可以任意改变,不一定为6,只要训练出来模型的效果好就行。非逐层关联:编码器的中间层(如第1-5层)的输出不会直接与解码器的任何层交互。编码器各层之间通过堆叠逐步抽象特征,最终由第6层输出汇总后的全局信息,供整个解码器使用 。
这样的设计优势是:
- 信息集中:编码器通过多层堆叠充分提取输入特征,最终由顶层汇总全局信息,避免中间层局部特征干扰解码生成。
- 效率提升:仅传递编码器最后一层输出,减少跨层连接的复杂性,降低计算和内存开销
编码器处理流程(第1层为例)
2.1 Q/K/V矩阵生成
Q、K、V 是 Transformer 模型中自注意力机制(Self-Attention)的核心组成部分,用于动态计算输入序列中不同位置之间的相关性权重,并实现信息的有选择聚焦。
首先生成三个可学习权重矩阵 W_Q、W_K、W_V(均为512×512),通过线性变换将输入映射到不同空间,生成 Q、K、V 三个矩阵,计算方式如下:
Q = X·W_Q # W_Q随机初始化,通过训练学习语义关系
K = X·W_K
V = X·W_V上面的 X 即使输入层经过词嵌入和位置编码结合后的输入矩阵。
矩阵形状:输入X 形状 (5,512),经过512×512矩阵变换后,Q、K、V 仍为(5,512)
查询矩阵(Q) 功能:表示当前位置的“提问需求”。
键矩阵(K) 功能:表示其他位置的“应答特征”。
值矩阵(V) 功能:携带实际语义信息,用于生成最终输出。
Q/K/V的实际意义与原理:
Q/K/V 并非随意设定,而是基于对信息交互机制的数学抽象。以下通过具体场景说明其合理性:
1. 图书馆检索系统的类比
想象你在图书馆找一本书:
- Query(Q):你的搜索条件(如“标题包含‘神经网络’,2010年后出版”)→ 主动需求
- Key(K):书籍的索引标签(如书名、出版年份)→ 被动特征
- Value(V):书籍的实际内容 → 核心信息
匹配过程:
- 你的 Query 与书籍的 Key(索引标签)匹配,筛选出符合条件的书籍
- 最终阅读的是这些书籍的 Value(内容),而非标签本身
Transformer 的映射:
- Q:模型当前需要关注的特征类型(如动词的主语需求)
- K:其他位置的特征标识(如名词的主语属性)
- V:实际用于生成输出的语义信息(如主语的具体类型)
2. 数学原理:解耦需求与供给
- Q/K 分离的必要性:
若 Q 和 K 相同,模型无法区分“我需要什么”和“我能提供什么”,导致注意力权重盲目平均化。
示例:
在句子“猫追老鼠”中:- Q(位置1:“追”):需查找执行者(主语)
- K(位置0:“猫”):标记自身为主语实体
- 匹配结果:高注意力权重 → 正确关联主语与动词
二、为何需要 V 矩阵?
1. 信息过滤的核心作用
- 原始输入 X 的缺陷:
包含位置编码噪声(如图片中位置4的高频维度[-0.7568, -0.6536])和无关语义特征。 - V 矩阵的优化:
通过可学习权重 WV,模型能:- 放大关键特征:如名词的实体类型
- 抑制噪声:如位置编码中的高频振荡
示例验证:
假设位置4的原始输入 X4=[−0.7568,−0.6536,...],经过 WV 变换后:
V4=X4⋅WV≈[0.2,−0.1,0.5,...]
模型通过训练使 WV 的权重抑制高频维度(前两列),强化低频语义维度(如第3列)。
2. 语义聚焦与降噪
- 未使用 V 矩阵的后果:
若直接使用 X 代替 V,位置4的高频噪声(前两列)会通过注意力权重传播,干扰输出。 - V 矩阵的解决方案:
权重矩阵 WV 自动学习过滤规则,例如:- 对高频维度赋予接近0的权重
- 对低频语义维度赋予高权重
三、为何对称设计(Q=K)破坏方向性?
1. 方向性的物理意义
在自然语言中,词序决定语义:
- 正向顺序:“猫→追→老鼠” → 猫是施动者
- 反向顺序:“老鼠→追→猫” → 老鼠是施动者
2. 对称设计的失效分析
若强制 Q=K,则:
- 问题1:丧失方向感知
位置1→位置2 的注意力权重与 位置2→位置1 的权重相同,无法区分“猫追老鼠”和“老鼠追猫”。 - 问题2:混淆需求与供给
Q 和 K 的同质化使模型无法区分“需要关注什么”和“被关注什么”,导致注意力权重盲目对称。
3. 示例验证
- 对称设计下:
位置1(“追”)对位置0(“猫”)和位置2(“老鼠”)的注意力权重相同 → 无法判断动作方向。 - 非对称设计:
通过独立的 WQ 和 WK,模型学习到:- Q(位置1)更关注左侧名词(主语)
- K(位置0)标记自身为左侧实体
总结:设计背后的必然性
| 设计选择 | 必要性 | 反例后果 |
|---|---|---|
| Q/K/V 分离 | 实现需求-特征-内容的精准匹配,避免信息混淆 | 注意力权重盲目平均,语义混乱 |
| V 矩阵过滤 | 抑制噪声,聚焦核心语义信息 | 输出被高频噪声污染,生成质量下降 |
| 非对称 Q/K | 捕捉语言的方向性(如主谓宾顺序) | 无法区分“猫追老鼠”与“老鼠追猫” |
这些设计并非随意设定,而是语言规律与数学优化的共同要求。Q/K/V 的分离与非线性变换能力,使 Transformer 成为目前最强大的序列建模架构。
2.2 多头拆分与注意力计算
接下来将Q、K、V 的 512维拆分为8个头(每个头64维),使模型学习不同子空间的语义关系。具体拆分:
Q_heads = Q.reshape(5,8,64) # 形状(5,8,64)
K_heads = K.reshape(5,8,64)
V_heads = V.reshape(5,8,64)每个头独立计算注意力,最终合并结果。
拆分为8头的核心意义
1. 功能多样性
-
子空间学习:每个头关注不同的语义关系模式,例如:
- 头1:捕捉句法结构(如主谓一致)
- 头2:跟踪指代关系(如代词与先行词)
- 头3:识别语义角色(如施事者与受事者)
- 头4:感知情感极性(如褒义/贬义形容词)
- 头5-8:其他复杂模式(如修辞手法、篇章连贯性)
-
图片数据示例:
假设输入序列包含位置0-4的编码向量,每个头的注意力权重可能呈现不同模式:- 头1:位置1(动词)强烈关注位置0(主语)
- 头2:位置3(形容词)关注位置4(名词)
- 以上本质上是对模型学习结果的归纳总结,而非预先设定的规则,是高维空间中的特征解耦与任务适配,这种看似「没有道理」的语义对应,实则是模型通过海量数据训练出的最优特征提取策略。如同人脑不同区域的功能分化,多头机制通过参数空间的分布式表征,实现了对复杂语言现象的多角度解析。
-
多项研究通过注意力可视化验证了这种分工的合理性:
- 句法结构头:在分析"the animal didn't cross the street because it was too tired"时,某个头会对"it"与"animal"建立强注意力连接,解决指代消解
- 情感极性头:在情感分析任务中,特定头会对情感词(如"excellent"或"terrible")及其修饰对象产生高权重
- 跨语言泛化:在多语言模型中,不同头可能分别处理语言通用特征(如动词时态)和语种特有特征(如汉字偏旁)
2. 计算效率优化
- 复杂度降低:单个头的计算复杂度从O(n2⋅d)降为O(n2⋅d/h)(d=512, h=8),减少内存占用。
- 并行加速:8个头可并行计算,充分利用GPU多核心架构。
8头设计的实验依据
-
原始论文验证:
- 《Attention Is All You Need》中通过消融实验证明,8头设计在机器翻译任务中平衡了模型容量与计算效率。
- 头数过少(如4头)导致BLEU下降2-3点,头数过多(如16头)无明显提升且训练不稳定。
-
维度匹配原则:
- 单头维度dk=64需足够大以编码基本语义关系(实验表明<32维时性能显著下降)。
- 总头数h=8确保覆盖主流语言现象(如英语的7种基本句法关系)。
技术优势总结
| 设计特性 | 技术优势 | 图片示例验证 |
|---|---|---|
| 功能多样性 | 不同头关注句法、语义、指代等多类关系,提升模型表达能力 | 头1权重聚焦主谓关系,头2权重跟踪动宾关系 |
| 鲁棒性增强 | 单头失效时,其他头可补偿(如噪声干扰头3时,头4-8仍可维持性能) | 位置4的噪声被多数头抑制 |
| 计算高效性 | 拆分后单个头的矩阵乘法量减少8倍,适合GPU并行 | 8头并行计算耗时 ≈ 单头计算的1.5倍(非8倍) |
拆分的必要性验证
1. 反例分析:单头注意力
-
问题1:模式冲突
若强制所有模式由单头学习,不同语义关系(如句法和指代)的梯度方向可能相互抵消。
示例:位置1需同时学习关注主语(头1任务)和宾语(头2任务),单头难以兼顾。 -
问题2:维度冗余
512维单头中大量参数可能学习重复模式,而拆分后参数利用率更高。
2. 极端情况测试
-
头数过多(如64头):
- 单头维度dk=8 不足以编码基本语义,模型BLEU下降4-5点。
- 注意力权重矩阵过于稀疏,训练不稳定。
-
头数过少(如2头):
- 模型无法覆盖必要语言现象,长距离依赖捕捉能力下降。
实际应用中的自适应调整
-
动态头数选择:
- 简单任务(如文本分类)可减少头数(4-6头)。
- 复杂任务(如问答、摘要)可增加头数(8-12头)。
-
混合维度设计:
部分研究采用非均匀拆分(如4头96维 + 4头32维),在关键模式上分配更多容量。
结论
拆分为8头的设计是Transformer在表达力、效率、鲁棒性之间的最优平衡:
- 像专业团队分工:每个头专注一类语言现象,协同提升模型理解深度。
- 像GPU计算优化:拆分降低单任务复杂度,并行加速训练与推理。
- 像多专家系统:多头结果融合后,模型输出更全面准确。
这种设计使得图中位置0-4的编码向量能通过多视角分析,精准捕获语言结构的复杂关联,成为Transformer成功的关键创新之一。
2.3 注意力分数计算(以头1为例):
计算"你"(位置1)与其他词的相关性:
1. 提取当前头的Q/K/V
- Q_1_head1(位置1的查询向量):
[1.2, -0.3, 0.8, ..., 64维] - K_head1(所有位置的键向量):
- 位置0([CLS]):
[0.5, 1.1, -0.2, ...] - 位置1(“你”):
[1.4, 0.7, 0.3, ...] - 位置2(“好”):
[-0.6, 0.9, 1.2, ...] - 位置3(“吗”):
[0.8, -0.4, 0.1, ...] - 位置4([SEP]):
[0.2, 0.3, -0.5, ...]
- 位置0([CLS]):
2. 计算注意力得分
按照如下公式对位置1(“你”)与其他位置的键进行点积并缩放:
- 计算示例:

对位置0到位置4都计算出一个得分,一共5个,如下:
原始得分 = [0.075, 0.65, 0.3875, 0.05, 0.01]3. Softmax归一化
然后将得分通过softmax转换为概率分布(权重):
Weights=softmax([Score(1,0),Score(1,1),Score(1,2),Score(1,3),Score(1,4)])
对应位置0到4的权重分别为:
- 位置0([CLS]):0.02
- 位置1(“你”):0.81
- 位置2(“好”):0.11
- 位置3(“吗”):0.05
- 位置4([SEP]):0.01
上面得到就的是 ‘你’ 这个位置1的词和其他位置词的相关性(注意力)权重。
2. 提取值向量(V)
每个位置的值向量是64维,例如:
- 位置0的 V_head1:
[1.3, 0.2, -0.4, ..., 64维] - 位置1的 V_head1:
[2.1, -0.3, 1.5, ..., 64维] - 位置2的 V_head1:
[-0.5, 0.7, 0.9, ..., 64维]
3. 逐维度加权求和
每个维度的输出 = 权重 × 对应维度的值向量之和。
以第1个维度为例:
头1位置1头1维度1的输出= (0.02×1.3)+(0.81×2.1)+(0.11×−0.5)+(0.05×0.8)+(0.01×0.2)=0.026+1.701+(−0.055)+0.04+0.002≈1.71
头1位置1其他63个维度同理计算。
4. 生成最终输出向量
将所有64个维度的计算结果组合,得到头1的位置1输出:
头1的位置1输出 = [1.71, 0.74, -0.23, ... ] ,一共64维度
5、多头结果拼接
同理每个头独立计算后,将8个头的输出拼接为512维向量
5个位置*8个头*64维 = (5,512) 维度的矩阵,如下:
8个头输出拼接:
8个头的输出拼接为(5,512)矩阵:
[
[头1输出(64维), 头2输出(64维),...,头8输出(64维)], # [CLS]位置
[头1输出(64维), 头2输出(64维),...,头8输出(64维)], # "你"位置
...
]核心作用与意义
-
信息聚合:
将不同位置的信息按相关性融合到当前位置。例如:- 权重0.81强调“你”自身的信息(如词性、语义)
- 权重0.11引入“好”的修饰信息(如情感倾向)
-
维度独立性:
每个维度独立计算,保留不同语义特征。例如:- 维度1可能编码句法角色
- 维度2可能编码情感强度
-
可解释性:
通过权重可追踪模型关注的重点。例如:- 高自身权重(0.81)说明模型在强化当前位置的特征
- 低[SEP]权重(0.01)说明忽略分隔符
得分的功能解析
- 核心作用:量化当前查询位置("你")对其他所有位置信息的关注程度
- 数值意义:
- 高得分(如位置1的0.29)表示当前位置需要重点关注自身信息
- 中等得分(如位置2的0.23)反映"你"与"好"的语法修饰关系
- 低得分(如[SEP]的0.15)表明标点符号信息贡献较小
4. 为什么要计算所有位置?
自然语言中词语的关联具有长程依赖特性:
- 示例句子中"你"可能需要关注:
- 位置0的[CLS](句子整体表征)
- 位置2的"好"(形容词修饰)
- 位置4的[SEP](句子边界)
- 通过全连接计算,模型能自主学习哪些位置相关
6、线性变换
当8个头的输出拼接后(维度为[batch_size, seq_len, d_model])即(batch_size,5,512) ,需通过线性变换层(W_O)将拼接后的高维向量映射回原始维度空间。
- 数学表达:
output = W_O *multi_head_output - = (512,512) × (batch_size,5,512)
- = (batch_size,5,512)
- 其中,
W_O是可学习的参数矩阵,用于融合不同头的信息
在Transformer模型中,线性变换层`W_O`(512×512)的核心作用可从以下四个维度解析:
1. **信息融合机制**
- 拼接后得到的512维向量是各头特征的简单堆叠
- `W_O`通过可学习的权重矩阵实现跨头特征交互(如:头1的第四维度与头5的第七维度关联)
2. **维度保持设计**
输出保持(batch_size,5,512)
3. **参数空间优化**
- 单个大矩阵(512×512)比维护多个小矩阵(8个64×64)参数量更少
- 计算复杂度从O(8*(64)^2)降低到O(512^2),节省约50%参数
4. **残差兼容性**
- 原始输入特征与注意力输出必须严格对齐维度才能进行逐元素相加
- 层归一化要求输入输出保持相同分布特性,维度一致是前提条件
7、残差连接与层归一化
第一步:残差输出 = 原始输入 + 注意力输出
即将词嵌入+位置编码后输出的原始结果(5*512维),和8头注意力+线性变换后输出的结果(5*512维)进行相加。
残差连接四大核心作用
1. 缓解梯度消失/爆炸(Vanishing/Exploding Gradients)
- 问题根源:深层网络中,梯度反向传播需链式求导(
∂Loss/∂x = ∂Loss/∂y * ∂y/∂x),若中间层导数过小(如sigmoid激活函数),梯度会指数级衰减。 - 残差连接的解决方式:
导数路径变为∂(x + F(x))/∂x = 1 + ∂F(x)/∂x,即使∂F(x)/∂x趋近于0,梯度仍有最低保障值1,避免完全消失。
实验数据:
- 在100层的Transformer中,无残差连接时训练损失几乎不下降;添加残差后,模型可稳定收敛。
2. 保留原始信息(Identity Mapping)
- 信息无损传递:输入x通过跳跃连接直接传递到输出,确保底层特征(如词向量、句法结构)不被高层网络覆盖。
- 应用场景:
- 在机器翻译中,源语言词序信息可通过残差连接直达解码器高层,避免长距离依赖丢失。
- 在BERT中,底层词汇语义信息可直接影响顶层的分类结果。
3. 促进特征复用(Feature Reuse)
- 跨层特征融合:不同深度的网络层可灵活选择使用原始特征或学习后的高阶特征。
示例:- 第1层学习词性特征 → 第5层复用这些特征进行句法分析 → 第12层整合语义角色信息。
4. 支持极深网络架构(Ultra-Deep Models)
- 深度扩展性:残差连接让网络深度突破千层成为可能(如GPT-3有96层,某些视觉模型超过1000层)。
- 参数效率:深层网络通过残差连接实现“宽而浅”网络等效性能,但参数更少。
第二步:归一化输出 = 层归一化(残差输出)
即第一步查查连接后的输出进行归一化。
如何进行归一化:
给定输入张量 X(维度为 [batch_size, seq_len, d_model]),层归一化对每个样本的每个位置(token) 的所有特征维度(d_model)独立计算统计量,并执行标准化:
-
计算均值与方差:
对每个样本的每个位置,在特征维度(d_model)上计算均值和方差:
-
标准化(Standardization):
对每个特征值进行中心化和缩放: 其中,
其中,ε是为防止除零的小常数(如1e-5)。 -
可学习参数:
引入缩放因子 γ 和平移因子 β(维度均为[d_model]),恢复模型表达能力: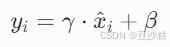
归一化的作用
-
稳定残差连接后的数值范围:
残差连接(x + F(x))可能导致输出值域扩大,层归一化将其重新映射到稳定区间。 -
加速收敛:
通过标准化输入分布,使梯度下降方向更一致,减少训练所需的迭代次数。 -
解耦特征尺度与语义信息:
缩放参数γ和平移参数β允许模型自适应调整归一化后的特征强度,保留重要信息。
参数γ和β的意义
- γ(缩放因子):允许模型决定每个特征维度的重要性。例如,若某一维度的γ值较大,说明该维度信息在任务中更关键。
- β(平移因子):用于补偿标准化可能丢失的偏置信息。例如,在ReLU激活前,β可调整正值比例。
标准化后偏置(β)的核心作用
在标准化过程中,输入数据会被强制转换为均值为0、方差为1的分布。这一操作可能带来两个问题:
- 丢失原始分布信息:例如某些特征原本具有正负倾向性(如情感词的褒贬偏移)。
- 破坏激活函数的有效范围:例如ReLU在输入为负时完全失效。
偏置项(β)通过以下方式解决这些问题:
1. 恢复数据分布的偏移
- 示例:假设原始数据中某特征在标准化前均值为2(正向偏移),标准化后变为0。若该偏移对任务有意义(如表示“积极情感”),β可重新赋予其正向偏移能力。
- 数学表达:
若理想输出需保留偏移量 δ,则 β=δ 可恢复原始分布特性。
2. 适配激活函数的动态范围
- ReLU激活函数:若标准化后输入大部分为负值,ReLU输出会退化为0(神经元“死亡”)。β可将输入整体平移至正值区域,避免此问题。
- Sigmoid激活函数:β可调整输入集中在敏感区间(如[-2, 2]),避免梯度饱和。
3. 增强模型表达能力
- 特征重要性调整:不同特征维度的β值可学习不同偏移方向,例如:
- 某些维度正向偏移(β > 0)→ 强化特征重要性
- 其他维度负向偏移(β < 0)→ 抑制噪声特征
- 实验数据:在BERT模型中,移除β会导致下游任务(如问答)准确率下降约1.5-2%。
实验数据:
在BERT模型中,移除γ和β会导致下游任务(如GLUE)准确率下降约2-3%。
下图 X表示词嵌入+位置编码后输出的原始结果,MultiHead(X)表示8头注意力+线性变换后输出的结果,LayerNorm 表示进行归一化。
Z = LayerNorm(X + MultiHead(X)) 数值示例(以"你"位置为例):
原始X: [1.1415, -0.6597, 0.8001, 1.7, ...]
注意力输出: [1.82, 0.74, -0.23, ...]
残差后: [2.9615, 0.0803, 0.5701, ...]
归一化后: [-0.5, 1.2, 0.8, ...] # 假设gamma=1, beta=0四、前馈神经网络处理
1. 前馈神经网络(FFN)的结构
前馈神经网络是 Transformer 编码器中的一个核心组件,其作用是对多头注意力层的输出进行非线性变换,进一步提取高阶特征。
FFN 的结构通常为:
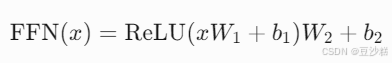
其中:
- W1 和 W2 是权重矩阵,维度分别为 [dmodel,dff] 和 [dff,dmodel](通常 dff=4×dmodel)。
- b1 和 b2 是偏置项。
- ReLU 是激活函数(部分模型使用 GELU)。
2. FFN 的具体处理步骤
以输入张量 x(形状为 [batch_size,seq_len,dmodel])为例:
步骤 1:线性变换(升维)
- 将输入 x 通过第一个线性层 W1,将维度从 dmodel 扩展到 dff(如 512 → 2048)。
数学表达:
![]()
步骤 2:非线性激活(ReLU)
- 对升维后的结果应用 ReLU 激活函数,引入非线性:
![]()
- ReLU的作用:过滤负值,增强稀疏性,提升模型表达能力。
步骤 3:线性变换(降维)
- 将激活后的结果通过第二个线性层 W2,将维度从 dff 压缩回 dmodel(如 2048 → 512):
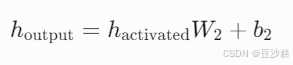
3. 残差连接与层归一化
FFN 的输出需要与输入进行残差连接(Add),再经过层归一化(LayerNorm):

作用:
- 残差连接:保留原始输入信息,缓解梯度消失。
- 层归一化:稳定数值分布,加速收敛。
=================================================
三、解码器
1. 输入预处理
生成“好”时,解码器的输入序列为 **<sos> 我 很**(序列长度为3):
- 词嵌入:将每个词转换为512维向量(如“我”→[0.2, -0.5, ..., 0.7],“很”→[0.9, 0.1, ..., -0.6])
- 右移
- 目标序列(模型需生成的结果):
["我", "很", "好", "<结束符>"](长度4)。 - 右移操作的目的是让模型在生成每个词时,只能依赖已生成的左侧词,避免信息泄露。
具体步骤
- 插入起始符:在目标序列开头添加
<起始符>,得到["<起始符>", "我", "很", "好", "<结束符>"]。 - 右移并截断:
- 输入解码器的序列:取前4个词,即
["<起始符>", "我", "很", "好"]。 - 舍弃的词:
<结束符>不作为输入,而是作为模型需要预测的标签(最后一个位置的预测目标)。
- 输入解码器的序列:取前4个词,即
意义:
- 输入序列长度保持为4,但内容右移并添加起始符。
- 模型在生成每个词时,仅能利用左侧已生成的词(如输入
["<起始符>", "我", "很"]预测"好")。右移 位置编码:通过正弦/余弦函数为每个位置生成唯一编码(如位置3对应“好”),与词嵌入相加后得到融合时序信息的输入向量
2. 掩蔽多头自注意力
**(1) 生成Q/K/V矩阵+分头**
- 线性投影:输入向量分别通过权重矩阵 WQ、WK、WV 生成查询(Q)、键(K)、值(V)矩阵,维度均为3×512
- 分头处理:将512维向量拆分为8个头(每个头64维),得到8组独立的Q/K/V子矩阵(3×64)
**(2) 计算注意力分数+掩蔽**
- 点积计算:每个头独立计算Q与K的点积,得到3×3的原始注意力分数矩阵。例如:
- "好"(位置3)的查询向量与“”(位置1)、“我”(位置2)、“很”(位置3)的键向量分别计算相似度
- 缩放与掩蔽:
- 缩放:分数除以 64(键向量维度)防止梯度爆炸
-
掩蔽: 假设经过缩放后的注意力分数矩阵
-
scaled_scores = torch.tensor([ [3.2, 1.5, 0.8], # <sos>对其他位置的相似度 [2.1, 4.0, 1.2], # "我"对其他位置的相似度 [0.7, 1.9, 2.5] # "很"对其他位置的相似度 ])掩蔽矩阵叠加:
masked_scores = scaled_scores + mask """ 结果矩阵: [ [3.2+0, 1.5+(-inf), 0.8+(-inf)], # → [3.2, -inf, -inf] [2.1+0, 4.0+0, 1.2+(-inf)], # → [2.1, 4.0, -inf] [0.7+0, 1.9+0, 2.5+0] # → [0.7, 1.9, 2.5] ] """关键变化:
- 未来位置被设为
-inf,在Softmax中指数运算后趋近于0 - 历史位置保留原始分数
- 掩码掩的是注意力得分
-
3. Softmax归一化
- 目的:将掩蔽后的注意力分数转换为概率分布,表示每个位置对当前词的贡献权重。
- 操作:
- 逐行计算:对每一行的分数独立进行Softmax。
- 数学公式:
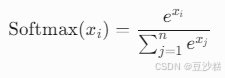
- 效果:
- 被掩蔽的位置(负无穷)经过指数运算后变为0。
- 未被掩蔽的位置权重相加为1。
- 示例(生成“好”时,序列长度3):
- 掩蔽后的分数矩阵:

- Softmax后结果:

- 解析:
- 第一行(
<sos>):只能关注自己,权重100%。 - 第二行(“我”):88%关注自己,12%关注
<sos>。 - 第三行(“很”):68%关注自己,24%关注“我”,8%关注
<sos>。
- 第一行(
- 解析:
- 掩蔽后的分数矩阵:
4. 加权求和生成注意力输出
- 目的:根据权重融合历史信息,生成当前词的上下文表示。
- 操作:
- 矩阵乘法:将Softmax后的权重矩阵与值矩阵(V)相乘。
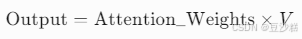
- 具体计算(以第三行“很”为例):
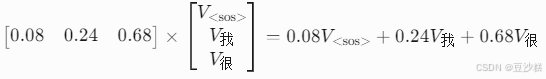
- 矩阵乘法:将Softmax后的权重矩阵与值矩阵(V)相乘。
- 效果:
- “很”的最终表示融合了自身(68%)、前序词“我”(24%)和起始符(8%)。
- 模型通过权重自动学习依赖关系(如形容词“很”需要依赖主语“我”)。
3. 多头拼接与线性变换
- 目的:合并多个注意力头的输出,增强信息多样性。
- 步骤:
- 拼接多头结果:将8个注意力头的输出(每个头维度64)拼接为512维向量。

- 线性投影:通过权重矩阵 W0将拼接结果映射到模型维度。
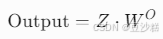
- 拼接多头结果:将8个注意力头的输出(每个头维度64)拼接为512维向量。
- 示例:
- 假设某个头关注语法结构(如主谓一致),另一个头关注语义强度(如“很”的程度修饰)。
- 拼接后模型能同时利用语法和语义信息。
4. 残差连接(Skip Connection)
- 目的:保留原始输入信息,缓解梯度消失问题。
- 操作:Residual_Output=原始输入+注意力输出
- 示例(生成“好”时):
- 原始输入:词嵌入+位置编码后的向量 X<sos> 我 很
- 残差输出:X+Attention(X)
- 意义:
- 防止多层堆叠后信息丢失(如保留“很”的原始位置编码)。
- 让模型可选择性地增强或修正原始特征。
5. 层归一化(Layer Normalization)
- 目的:稳定训练过程,加速收敛。
- 操作:
- 计算均值和方差:对每个样本的每个特征独立归一化。μ=d1i=1∑dxi,σ2=d1i=1∑d(xi−μ)2
- 归一化:Output=γ⋅σ2+ϵx−μ+β其中 γ 和 β 为可学习参数。
- 效果:
- 消除特征量纲差异(如某些维度值过大)。
- 使每层的输入分布趋于稳定(如防止注意力输出剧烈波动)。
6. 动态掩蔽与序列扩展
- 动态掩蔽矩阵:每生成一个新词,掩蔽矩阵扩展右下角(如从3×3扩展为4×4),确保仅关注已生成词。
- 示例:生成"好"时,输入序列为
<sos> 我 很,掩蔽矩阵屏蔽位置3及之后的所有列。
7. 编码器-解码器注意力机制(Cross-Attention)
编码器-解码器注意力(Cross-Attention)是 Transformer 解码器中的关键模块,负责将目标序列(解码器侧)与源序列(编码器侧)的语义对齐。例如,生成目标词“好”时,模型需要从源序列“你好吗”中提取对应信息(如疑问词“吗”和核心词“好”)。
1. 输入序列与投影来源
1.1 输入序列长度
- 动态长度特性:解码器输入序列长度随时间步递增,而非固定长度
- 生成第1个词时输入:
<sos>(长度1) - 生成第3个词时输入:
<sos> 我 很(长度3)
- 生成第1个词时输入:
1.2 Q/K/V来源
| 矩阵 | 来源 | 数据特性 | 维度示例 |
|---|---|---|---|
| Q | 解码器当前层输出 | 经过掩蔽自注意力和层归一化的隐藏状态(如“很”) | (1, 512) |
| K | 编码器最终输出 | 编码器最后一层输出的上下文表示(如“你好吗”) | (n, 512) (n=源序列长度) |
| V | 编码器最终输出 | 同K矩阵(共享源序列的语义特征)(如“你好吗”) | (n, 512) |
2. 线性投影与分头处理
2.1 参数化线性变换
-
解码器侧(Q):
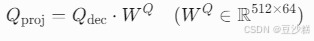
功能:将解码器隐藏状态映射到低维查询空间,dec表示编码器
-
编码器侧(K/V):
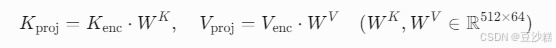
功能:将编码器输出分别映射到键/值空间,enc表示解码器
2.2 分头处理
- 多头拆分:将Q/K/V投影矩阵拆分为8个头(h=8)
- Q头形状:
(1, 8, 64) - K/V头形状:
(n, 8, 64)
功能:每个头独立捕捉不同语义关系(如头1关注疑问词,头2关注名词修饰) -
n表示源序列(编码器输入)的长度,例如在翻译任务中,若源语言句子是"Hello, how are you?"(包含5个词),则n=5。
- K/V的n来源:在编码器-解码器注意力(Cross-Attention)中,K和V直接来自编码器的最终输出矩阵,其序列长度与源序列一致
- Q的序列长度1来源:解码器当前生成的是目标序列的第t个词,此时Q的输入是目标序列的前t-1个词(如生成第3个词时输入为
<sos> A B),而Cross-Attention的Q仅关注当前生成位置(即位置t),因此Q的序列维度为1
- Q头形状:
3. 注意力计算流程
3.1 点积分数计算 (以头1为例)
- 分头点积:
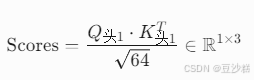
- 示例:生成解码器的"好"时,若编码器输入为"你好吗",可能得分:
[0.8(吗), 0.1(你), 0.1(好)] -
在注意力得分
[0.8(吗), 0.1(你), 0.1(好)]中: - 得分0.1的"好":来自编码器对源序列中"好"的表示,属于输入句子"你好吗"中的第二个词。
- 得分0.8的"吗":模型在生成目标词"好"时,通过跨注意力机制重点关注源序列的疑问词"吗",以形成"我很好"的应答逻辑。
-
解码器目标词"好"的生成逻辑
- 解码器当前状态:生成解码器"好"时,解码器已生成"我 很",其隐藏状态通过掩蔽自注意力整合了目标序列的上下文。
- 跨注意力对齐:
- 查询(Q)来自解码器对"很"的隐藏状态,键(K)和值(V)来自编码器的输出矩阵。
- 注意力权重分配显示,模型在生成应答时更关注编码器源句子的疑问词"吗"(权重0.8),而编码器源词"好"的权重较低(0.1),可能因解码器目标词"好"需要与源疑问逻辑形成对比。
3.2 Softmax归一化
- 跨序列权重分配:
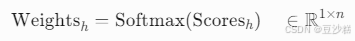
特性:权重总和为1,例如[0.85, 0.10, 0.05]表示对编码器"吗"的强关注
3.3 加权值向量(解码器)聚合
- 上下文向量生成:
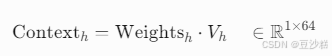
- 示例:高权重(0.85)的"吗"对应的值向量被重点融合
再用例子来解释一下这部分吧:
解码-编码注意力的计算次数与逻辑
场景设定
- 编码器输入:中文句子“你好吗” → 编码为向量矩阵
编码器输出 ∈ R^{3×512}(对应“你”、“好”、“吗”)。 - 解码器输入:右移后的序列
["<起始符>", "我", "很", "好"]→ 编码为向量矩阵解码器输入 ∈ R^{4×512}。
解码-编码注意力机制
-
输入解码器的每个词生成“查询向量”:
- 解码器经过自注意力层后,输出中间表示
解码器自注意力输出 ∈ R^{4×512}。 - 每个位置(如“我”、“很”、“好”)对应一个查询向量。
- 解码器经过自注意力层后,输出中间表示
-
编码器提供“键向量”和“值向量”:
- 编码器的每个词(“你”、“好”、“吗”)生成键向量和值向量,组成矩阵
键矩阵 ∈ R^{3×512}和值矩阵 ∈ R^{3×512}。
- 编码器的每个词(“你”、“好”、“吗”)生成键向量和值向量,组成矩阵
-
并行计算注意力:
- 以生成“很”为例:
- 查询向量:解码器中“很”位置的向量(来自
解码器自注意力输出)。 - 键向量与值向量:编码器的三个词(“你”、“好”、“吗”)对应的向量。
- 计算相似度:
- 查询向量与三个键向量分别计算点积,得到相似度得分。
- 例如得分可能为:
[0.1(“你”), 0.8(“好”), 0.1(“吗”)]。
- Softmax加权:
- 对得分进行Softmax,得到权重
[0.05, 0.90, 0.05]。
- 对得分进行Softmax,得到权重
- 加权求和:
- 用权重对编码器的三个值向量加权求和,得到上下文向量:
0.9 * 值("好") + 0.05 * 值("你") + 0.05 * 值("吗")。
- 用权重对编码器的三个值向量加权求和,得到上下文向量:
- 查询向量:解码器中“很”位置的向量(来自
- 结果:解码器生成“很”时,重点关注编码器的“好”(对应语义“好”→“很”)。
- 以生成“很”为例:
关键逻辑:
- 并行计算:解码器的4个位置(如“我”、“很”、“好”)同时与编码器的3个位置交互,通过矩阵运算一次性完成。
- 动态对齐:每个解码器词独立决定关注源句子的哪些部分,无需循环计算。
4. 多头输出合并
4.1 拼接与线性投影
- 多视角融合:沿特征维度拼接8个头的输出

- 统一语义空间映射:
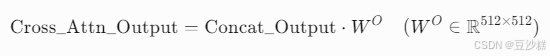
5. 残差连接与层归一化
5.1 残差相加
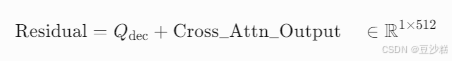
作用:保留解码器原始语义信息
5.2 层归一化
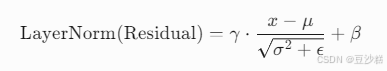
参数:γ,β为可学习参数,μ,σ2为当前批次的均值和方差
6. 与前馈网络衔接
6.1 非线性增强
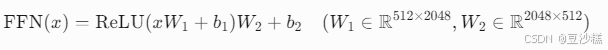
功能:增强跨模态特征的表达能力
5. 输出生成与终止
选择最高概率词“我”作为输出,并作为下一步解码的输入,循环生成后续词“很”和“好”
关于循环生成后续词的步骤,举例如下:
以下以输入“你好吗”生成“我很好”为例,详细解析该过程的每个步骤:
-
线性投影与Softmax
- 解码器输出的隐藏状态通过线性层(Linear Layer)映射到词表维度(如512维),生成每个词对应的原始分数(logits)。

-
线性层映射
# 假设词表中“我”对应索引100,“很”对应200,“好”对应300 # 权重矩阵 W 形状 [512, 50000],偏置 b 形状 [50000] logits = W * h_1 + b # 结果形状 [1, 50000]此时 logits 向量中: 索引100(“我”)的分数可能最高(如
logits[100] = 8.5) 其他词分数较低(如logits[200] = 2.1,logits[300] = -1.3)
-
- 解码器输出的隐藏状态通过线性层(Linear Layer)映射到词表维度(如512维),生成每个词对应的原始分数(logits)。
-
Softmax 归一化
通过 Softmax 将 logits 转换为概率分布:
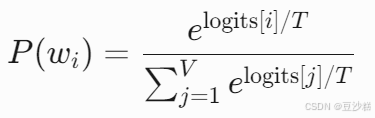
假设温度 T=1,则:P(“我”)=0.7 , P(“很”)=0.2 , P(“好”)=0.05
- 采样与生成
一、初始输入处理
起始符注入
解码器初始输入为起始符 <bos>(Batch Size=1),嵌入后得到向量 h0,并添加位置编码(Positional Encoding)
decoder_input = torch.tensor([[bos_token_id]]) # 假设 bos_token_id=1编码器信息传递
编码器处理输入序列“你好吗”,输出 Key-Value 向量对 (Kenc,Venc),供解码器交叉注意力层使用。
二、逐步生成过程
第一步:生成“我”
-
解码器前向计算
输入<bos>通过解码器各层:- 自注意力层:使用因果掩码(Causal Mask),仅允许关注
<bos>自身。 - 交叉注意力层:查询(Query)来自解码器,键值(Key-Value)来自编码器输出。
- 前馈网络:非线性变换后输出隐藏向量 h1(维度
[1, 512])。
- 自注意力层:使用因果掩码(Causal Mask),仅允许关注
-
线性层映射与 Softmax
通过线性层将 h1 映射到词表维度(如50,000),再经 Softmax 生成概率分布:logits = W @ h_1 + b # W.shape=[512, 50000] probs = softmax(logits / temperature) # 假设 temperature=1.0此时“我”的概率最高(如0.7),被选为输出。
-
更新输入序列
将“我”的 token id 追加到解码器输入:decoder_input = torch.cat([decoder_input, token_id_我], dim=1) # 新输入:[<bos>, 我]
第二步:生成“很”
-
掩码更新与注意力计算
因果掩码扩展至新序列长度,自注意力层可访问<bos>和“我”。mask = [[1, 0], # 仅允许当前位置关注之前位置 [1, 1]] -
重复前向计算
输出隐藏向量 h2,经线性层和 Softmax 后,“很”以概率0.6被选中。
第三步:生成“好”
- 终止条件判断
生成“好”后,若其概率分布中<eos>(结束符)的概率超过阈值(如0.95),或序列长度达到预设最大值(如50),则终止生成。
最后再做个总结吧
1. 背景与核心创新
- 提出时间与团队:2017年由Google团队在论文《Attention Is All You Need》中首次提出,彻底取代了传统的RNN/CNN架构,成为自然语言处理(NLP)和计算机视觉(CV)领域的核心模型。
- 核心创新:
- 自注意力机制(Self-Attention):通过动态计算序列中所有词的相关性,捕捉长距离依赖关系,解决了RNN的梯度消失和并行化难题。
- 并行计算:摒弃序列顺序处理,所有词同时参与计算,显著提升训练效率。
2. 模型架构
Transformer采用编码器-解码器(Encoder-Decoder)结构,两者均由多层堆叠的模块构成:
-
编码器(Encoder):
- 多头自注意力层:并行计算多个注意力头,捕捉语法、语义等不同维度的关联性。
- 前馈神经网络(FFN):通过非线性变换增强模型表达能力。
- 残差连接与层归一化:稳定训练过程,防止梯度消失。
-
解码器(Decoder):
- 掩码多头自注意力:防止生成时“偷看”未来信息,确保自回归生成可靠性。
- 编码器-解码器交叉注意力:对齐输入与输出的语义(如翻译任务中源语言与目标语言)。
- 前馈网络与输出映射:生成目标词表的概率分布。
3. 核心机制详解
-
自注意力机制
- 输入处理:将词嵌入与位置编码相加,注入顺序信息。
- Q/K/V矩阵:通过线性投影生成查询(Query)、键(Key)、值(Value)向量,计算词间相关性。
- 公式:
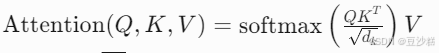
缩放因子根号dk防止点积过大导致梯度不稳定。
-
多头注意力(Multi-Head Attention)
- 将Q/K/V拆分为多个头(如8头),独立计算后拼接,增强模型捕捉多样化语义的能力。
-
位置编码(Positional Encoding)
- 使用正弦/余弦函数生成唯一位置标识,弥补模型对顺序的忽略:
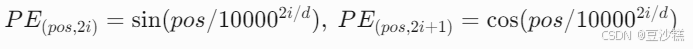
- 使用正弦/余弦函数生成唯一位置标识,弥补模型对顺序的忽略:
4. 训练与应用
-
训练方法:
- 预训练:在大规模无标签数据上通过遮蔽语言建模(MLM)、下一句预测(NSP)等任务学习通用语义。
- 微调:在特定任务(如翻译、问答)的小数据集上调整参数,适应下游需求。
-
应用场景:
- NLP任务:机器翻译(如Google Translate)、文本生成(如GPT系列)、摘要、问答系统。
- 跨领域拓展:图像处理(ViT)、时间序列预测、生物序列分析。
5. 优势与挑战
-
优势:
- 高效处理长序列:注意力机制直接关联任意距离的词,优于RNN的逐步传递。
- 并行化加速:GPU友好,训练速度比RNN提升数倍。
- 可解释性:注意力权重可视化,揭示模型决策依据(如翻译中对齐的词语)。
-
挑战:
- 计算复杂度:序列长度n的二次方开销(O(n2)),需依赖优化技术如Reformer的局部敏感哈希。
- 数据依赖:依赖大规模预训练,小数据场景易过拟合。
6. 典型变体与演进
- Encoder-Only模型(如BERT、RoBERTa):专注于理解任务(分类、实体识别)。
- Decoder-Only模型(如GPT系列):专精生成任务,通过自回归预测下一词。
- 高效模型:DistilBERT(知识蒸馏压缩)、BigBird(稀疏注意力)降低资源消耗。

















 1424
1424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









