







https://blog.csdn.net/qq_18870127/article/details/79097735
https://blog.csdn.net/xiaoweidz9/article/details/79895489
出发点
一旦判别函数的形式确定下来,不管它是线性的还是非线性的,剩下的问题就是如何确定它的系数。
在模式识别中,系数确定的一个主要方法就是通过对已知样本的训练和学习来得到。
感知器算法就是通过训练样本模式的迭代和学习,产生线性(或广义线性)可分的模式判别函数。
基本思想
采用感知器算法(Perception Approach)能通过对训练模式样本集的“学习”得到判别函数的系数。
说明
这里采用的算法不需要对各类别中模式的统计性质做任何假设,因此称为确定性的方法。
感知器算法实质上是一种赏罚过程
对正确分类的模式则“赏”,实际上是“不罚”,即权向量不变。
对错误分类的模式则“罚”,使w(k)加上一个正比于xk的分量。
当用全部模式样本训练过一轮以后,只要有一个模式是判别错误的,则需要进行下一轮迭代,即用全部模式样本再训练一次。
如此不断反复直到全部模式样本进行训练都能得到正确的分类结果为止。
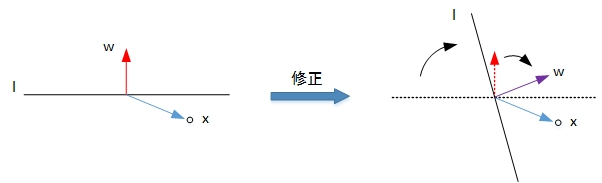
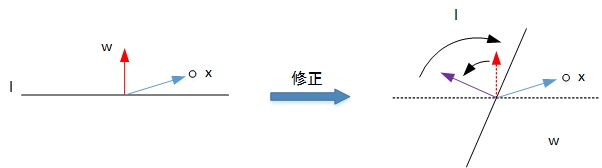
图片来源



讨论
这里的分类算法都是通过模式样本来确定判别函数的系数,但一个分类器的判断性能最终要受并未用于训练的那些未知样本来检验。
要使一个分类器设计完善,必须采用有代表性的训练数据,它能够合理反映模式数据的整体。
讨论
要获得一个判别性能好的线性分类器,究竟需要多少训练样本?
直观上是越多越好,但实际上能收集到的样本数目会受到客观条件的限制;
过多的训练样本在训练阶段会使计算机需要较长的运算时间;
一般来说,合适的样本数目可如下估计:
若k是模式的维数,令C=2(k+1),则通常选用的训练样本数目约为C的10~20倍
感知器算法存在许多解?
初值的选择
迭代过程中误分类点的选择顺序
不能唯一确定,这就是支撑向量机的作用



最小平方误差(LMSE)算法
出发点
感知器算法只是当被分模式可用一个特定的判别界面分开时才收敛,在不可分情况下,只要计算程序不终止,它就始终不收敛。
即使在模式可分的情况下,也很难事先算出达到收敛时所需要的迭代次数。
这样,在模式分类过程中,有时候会出现一次又一次迭代却不见收敛的情况,白白浪费时间。
为此需要知道:发生迟迟不见收敛的情况时,到底是由于收敛速度过慢造成的呢,还是由于所给的训练样本集不是线性可分造成的呢?
最小平方误差(LMSE)算法,除了对可分模式是收敛的以外,对于类别不可分的情况也能指出来。





















 5006
5006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









