







 本文概览了机器翻译的主要方法,包括直接转换、基于规则、基于中间语言、基于语料库的翻译方法,重点介绍了基于规则和统计机器翻译的原理与评价。基于规则的翻译能较好保持原文结构,但规则编写工作量大且主观性强;统计机器翻译利用噪声信道模型,解决翻译概率计算问题。
本文概览了机器翻译的主要方法,包括直接转换、基于规则、基于中间语言、基于语料库的翻译方法,重点介绍了基于规则和统计机器翻译的原理与评价。基于规则的翻译能较好保持原文结构,但规则编写工作量大且主观性强;统计机器翻译利用噪声信道模型,解决翻译概率计算问题。
机器翻译方法概述
- 直接转换法
- 基于规则的翻译方法
- 基于中间语言的翻译方法
- 基于语料库的翻译方法
- 基于事例的翻译方法
- 统计翻译方法
- 神经网络机器翻译
基于规则的翻译过程分成6个步骤:
(a) 对源语言句子进行词法分析
(b) 对源语言句子进行句法/语义分析
© 源语言句子结构到译文结构的转换
(d) 译文句法结构生成
(e) 源语言词汇到译文词汇的转换
(f ) 译文词法选择与生成

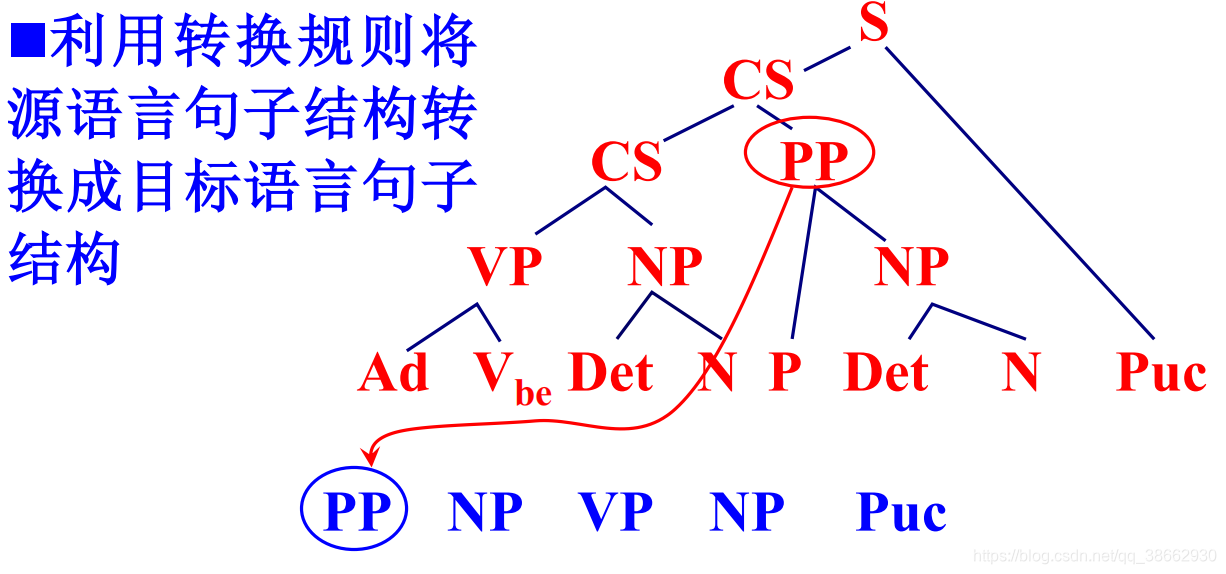
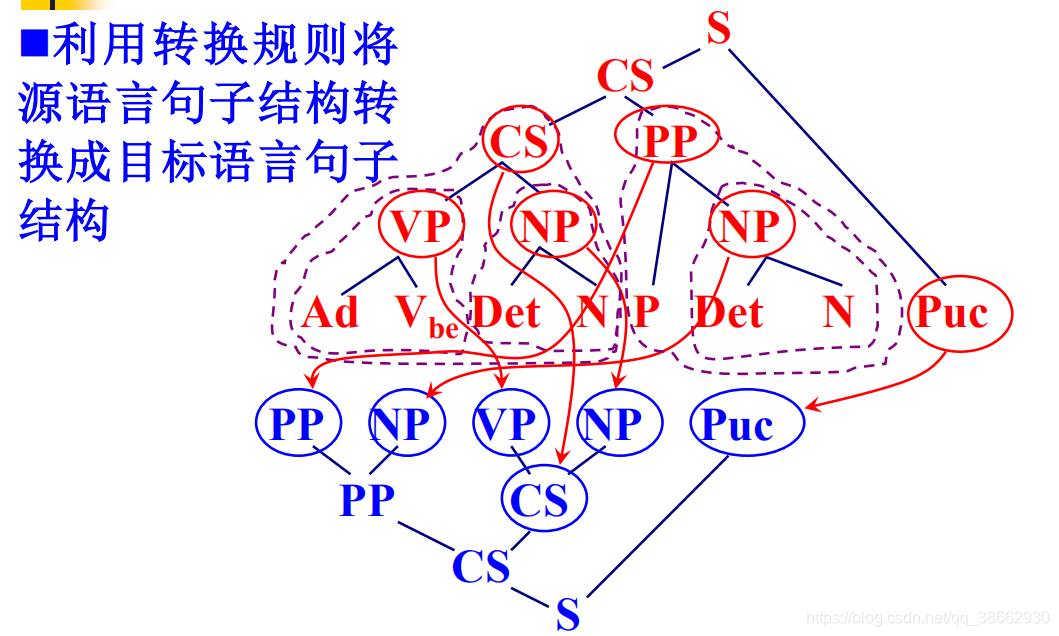

对基于规则的翻译方法的评价:
优点:
可以较好地保持原文的结构,产生的译文结构与源文的结构关系密切,尤其对于语言现象已知的或句法结构规范的源语言语句具有较强的处理能力和较
好的翻译效果。
弱点:
规则一般由人工编写,工作量大,主观性强,一致性难以保障,不利于系统扩充,对非规范语言现象缺乏相应的处理能力
统计机器翻译
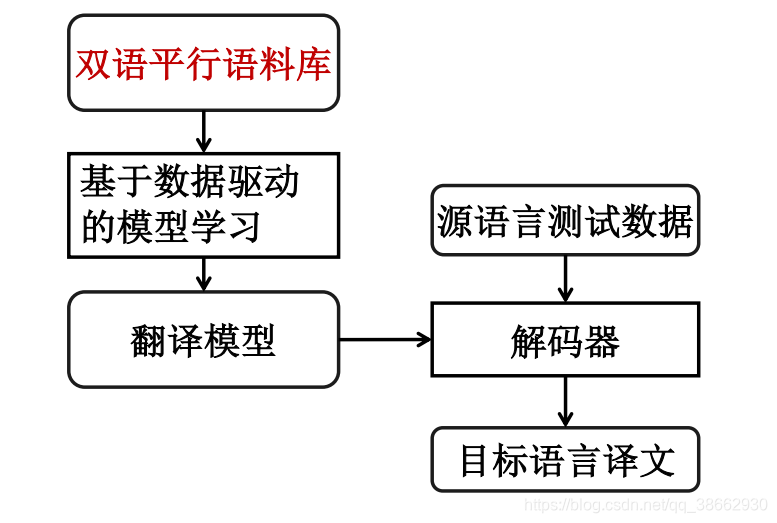
噪声信道模型
一种语言T 由于经过一个噪声信道而发生变形,从而在信道的另一端呈现为另一种语言 S (信道意义上的输出,翻译意义上的源语言)。翻译问题实际上就是如何根据观察到的 S,恢复最为可能的T 问题。这种观点认为,任何一种语言的任何一个句子都有可能是另外一种语言中的某个句子的译文,只是可能有大有小[Brown et. al, 1990]。

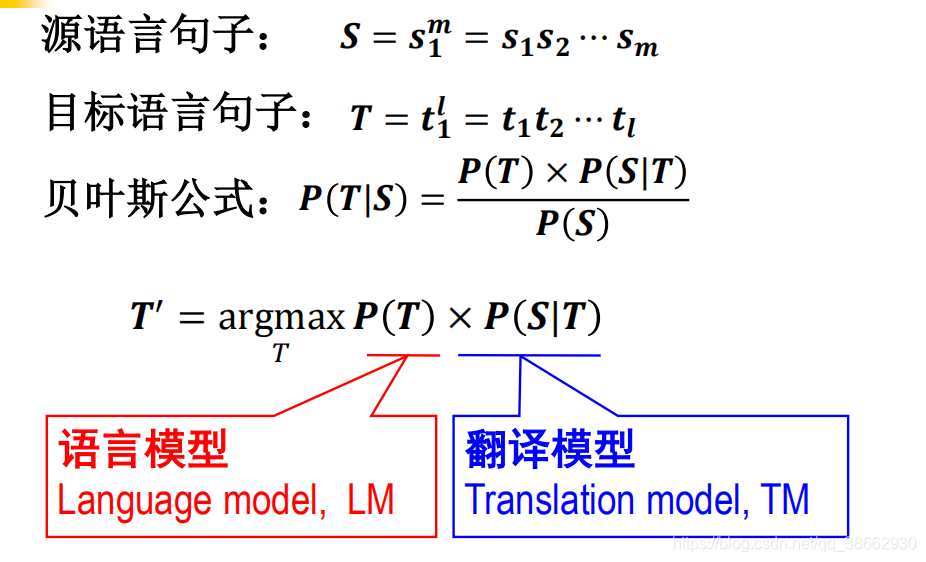
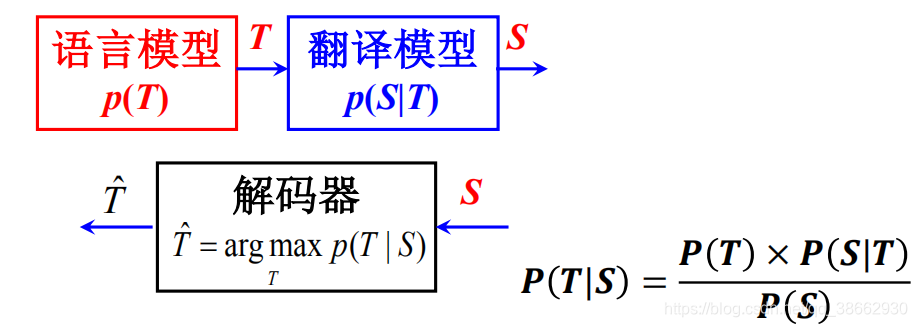
统计翻译中的三个关键问题:
(1)估计语言模型概率 p(T);
(2)估计翻译概率 p(S|T);
(3)快速有效地搜索T 使得 p(T)×p(S | T) 最大





翻译概率计算

实际上,p(S, A|T) 可以写成多种形式的条件概率的乘积,上式只是其中的一种。在上式的基础上,IBM 的研究人员通过采用不同的假设条件得到了5个翻译模型,分别称作 IBM 翻译模型1、2、3、4 和 5。



最大熵模型(生成式)
最大熵方法的基本思想
任务:
对于一个随机事件,假设已经有了一组样例,我们希望建立一个统计模型来模拟这个随机事件的分布
目标:
对于一组特征,使得统计模型在这一组特征上的模型分布与样例中的经验分布完全一致,同时不对未知事件作任何假设,即保证这个模型尽可能的“均匀”(也就是要求模型的熵值达到最大)



















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









