






一、MobileNetV1 网络
- 这篇论文是 Google 针对手机等嵌入式设备提出的一个小网络模型,主要侧重于简单有效,描述了一个有效的网络架构和两个超参数来建立非常小的、低延迟的模型,以便轻松匹配移动和嵌入式视觉应用的设计要求。

Mobilenet v1核心是把卷积拆分为Depthwise+Pointwise两部分。

- 深度卷积在每个通道上应用一个卷积核。逐点卷积接着应用1*1卷积把输出和深度卷积结合起来。标准卷积在一个步骤把卷积核和输入结合为新的输出。深度可分离卷积将其分为两层,一层用于滤波,一层用于结合。这个分解过程极大地减少了计算量和模型的大小。具体如下:

- 其中分母为原来标准卷积的模型参数,分子为将标准卷积分为Depthwise+Pointwise两部分后的参数量,可以看到明显模型参数降低。
- 代码部分:

![]()
二、MobileNetV2 网络
- MobileNetV2 主要提出两方面的改进:
- Linear Bottlenecks:在维度较小的 1x1 卷积之后不再采用ReLU操作,避免对特征的破坏。作者去掉了第二个pointwise convolution的激活函数ReLU,作者认为激活函数在高维空间能够有效增加非线性,但在低维空间则会破坏特征。
- Inverted Residuals:与传统resnet结构中先对bottlenecks降维再复原不同,这里先用一个expand layer进行升维,然后再depthwise convolution最后再1x1降维复原。


三、HybridSN 高光谱分类网络
补充代码段
class_num = 16
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
self.conv1=nn.Conv3d(in_channels=1,out_channels=8,kernel_size=(7,3,3))
self.conv2=nn.Conv3d(in_channels=8,out_channels=16,kernel_size=(5,3,3))
self.conv3=nn.Conv3d(in_channels=16,out_channels=32,kernel_size=(3,3,3))
self.conv4=nn.Conv2d(576, 64, 3)
self.fc1=nn.Linear(18496,256)
self.fc2=nn.Linear(256,128)
self.fc3=nn.Linear(128,class_num)
self.dropout=nn.Dropout(p=0.4)
def forward(self, x):
x=F.relu(self.conv1(x))
x=F.relu(self.conv2(x))
x=F.relu(self.conv3(x))
x=torch.reshape(x,[x.shape[0],576,19,19])
x=F.relu(self.conv4(x))
x=torch.flatten(x,start_dim=1)
x=F.relu(self.fc1(x))
x=F.dropout(x,p=0.4,training=self.training)
x=F.relu(self.fc2(x))
x=F.dropout(x,p=0.4,training=self.training)
x=self.fc3(x)
return x
1、3D卷积和2D卷积的区别
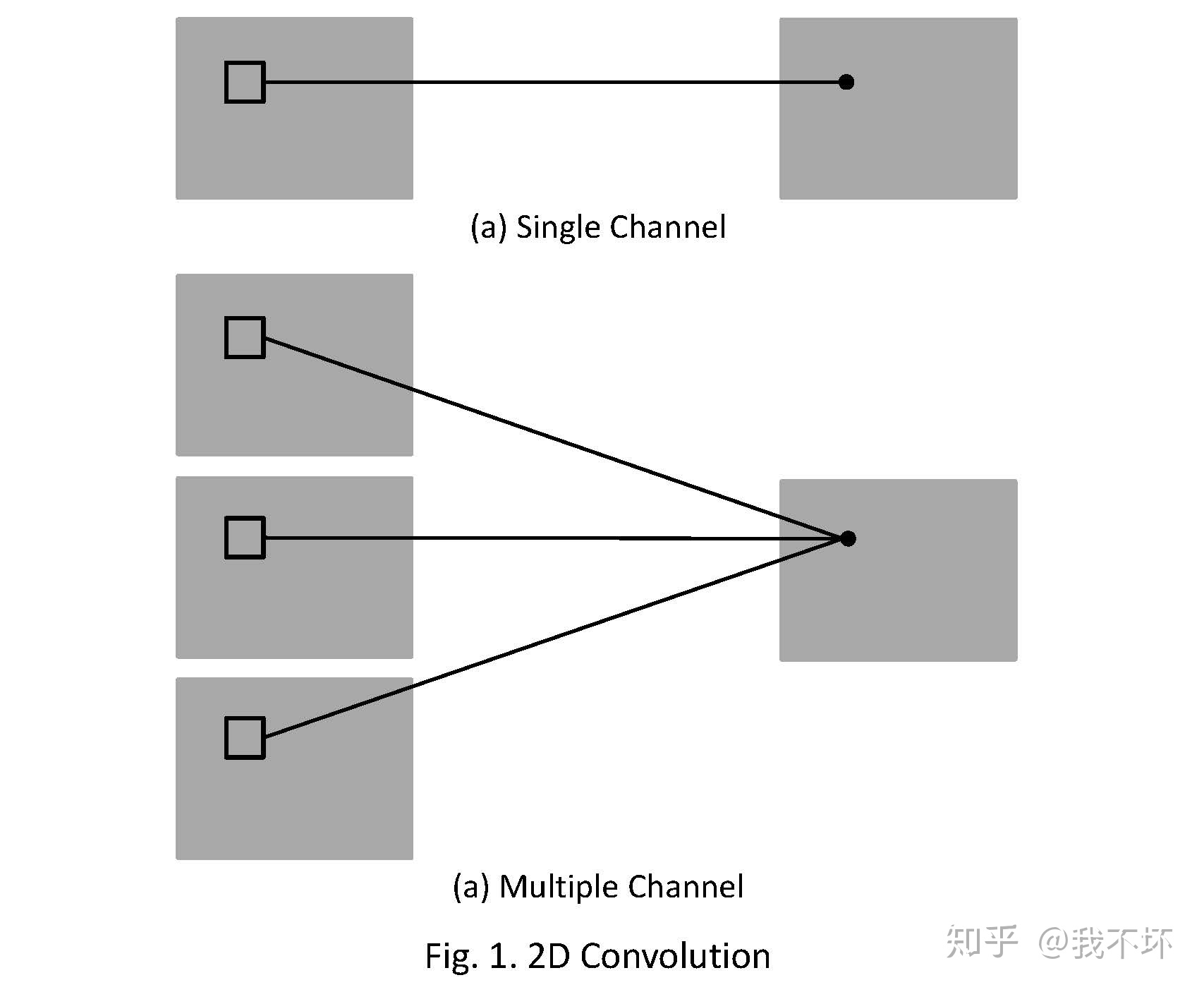
2D卷积操作如图1所示,为了解释的更清楚,分别展示了单通道和多通道的操作。且为了画图方便,假定只有1个filter,即输出图像只有一个chanel。
其中,针对单通道,输入图像的channel为1,即输入大小为(1, height, weight),卷积核尺寸为 (1, k_h, k_w),卷积核在输入图像上的的空间维度(即(height, width)两维)上进行进行滑窗操作,每次滑窗和 (k_h, k_w) 窗口内的values进行卷积操作(现在都用相关操作取代),得到输出图像中的一个value。
针对多通道,假定输入图像的channel为3,即输入大小为(3, height, weight),卷积核尺寸为 (3, k_h, k_w), 卷积核在输入图像上的的空间维度(即(height, width)两维)上进行进行滑窗操作,每次滑窗与3个channels上的 (k_h, k_w) 窗口内的所有的values进行相关操作,得到输出图像中的一个value。
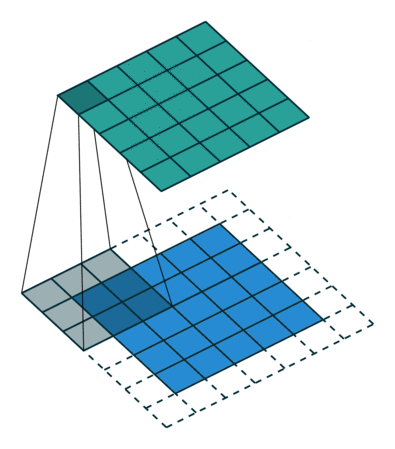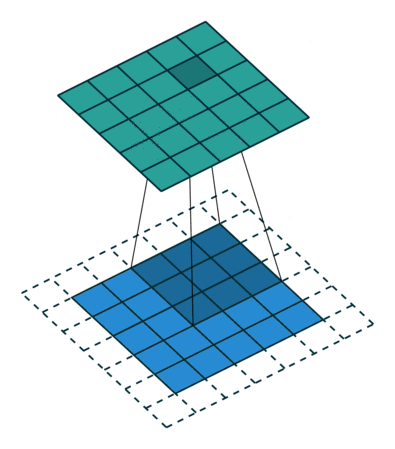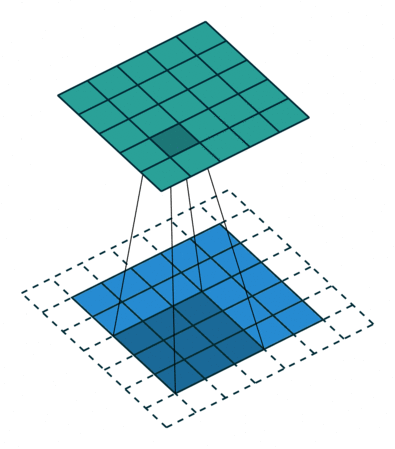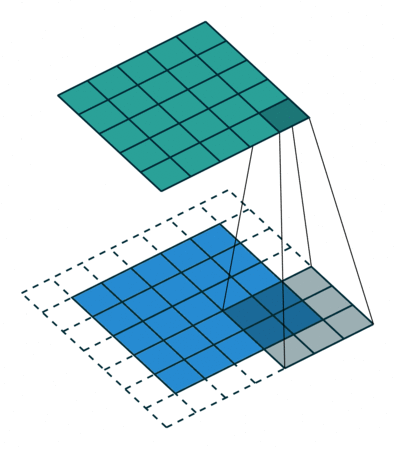
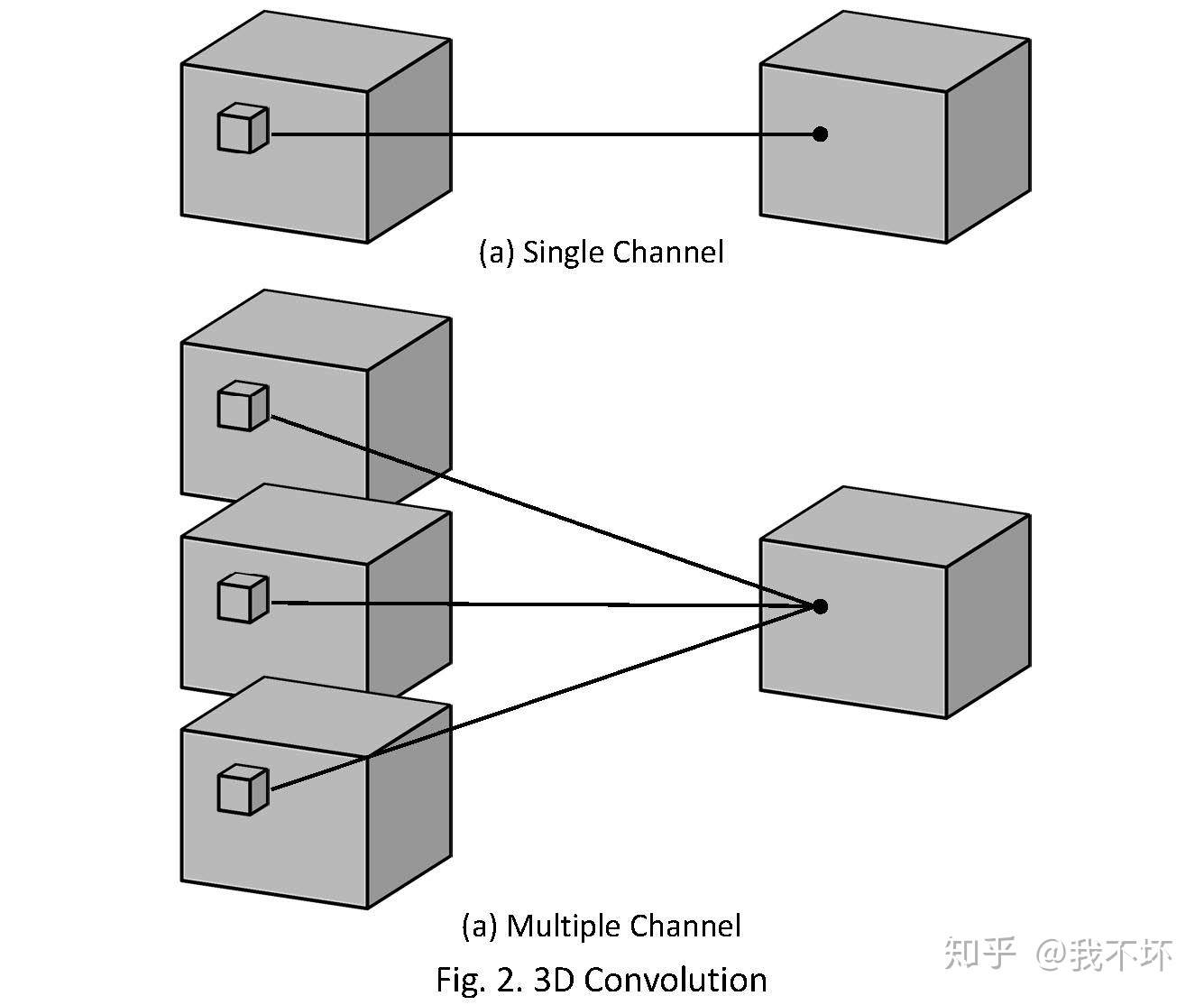
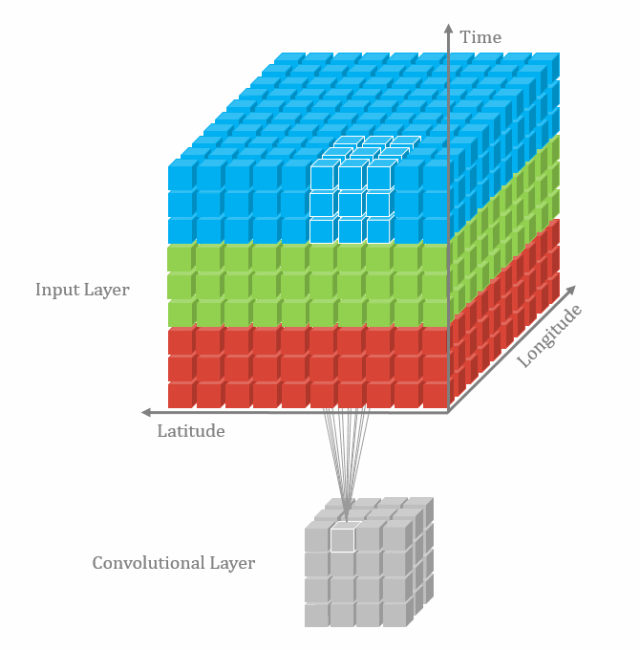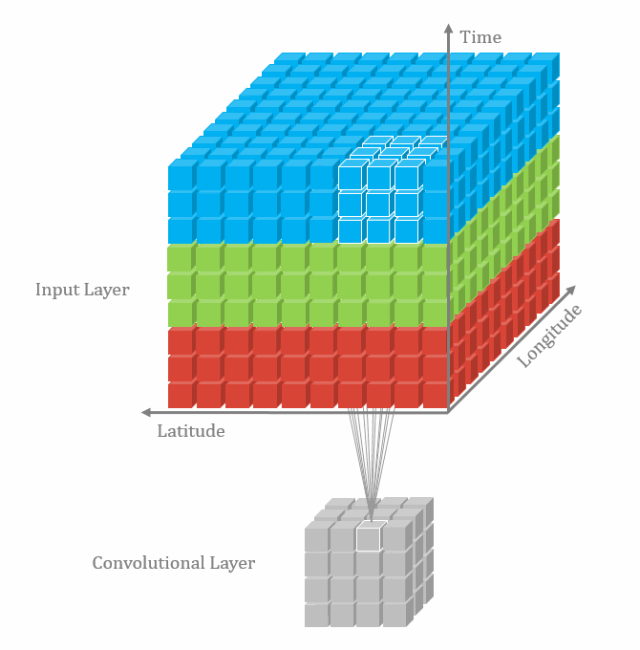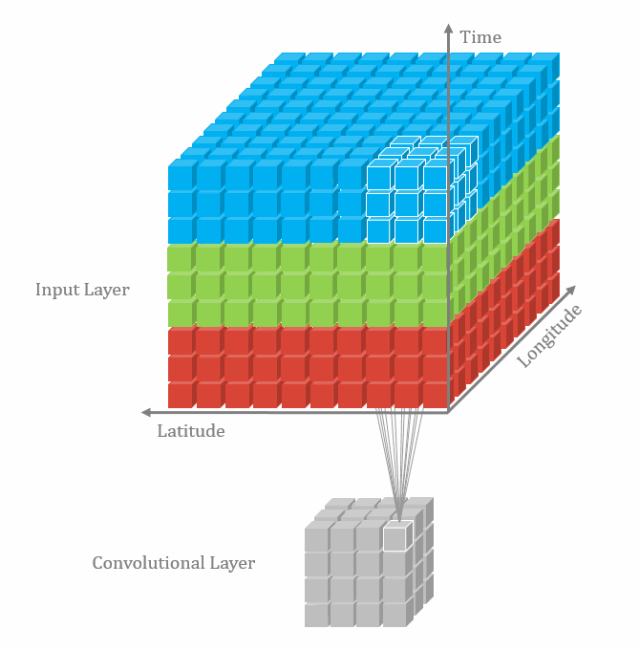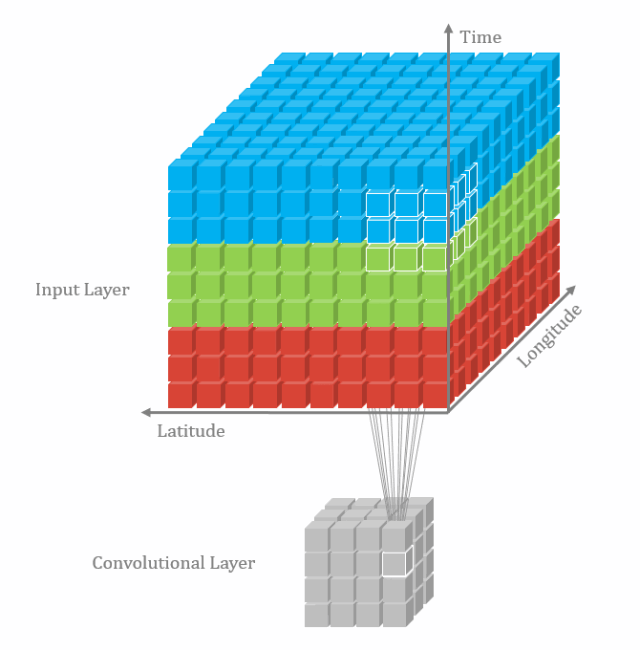
3D卷积操作如图2所示,同样分为单通道和多通道,且只使用一个filter,输出一个channel。
其中,针对单通道,与2D卷积不同之处在于,输入图像多了一个 depth 维度,故输入大小为(1, depth, height, width),卷积核也多了一个k_d维度,因此卷积核在输入3D图像的空间维度(height和width维)和depth维度上均进行滑窗操作,每次滑窗与 (k_d, k_h, k_w) 窗口内的values进行相关操作,得到输出3D图像中的一个value.
针对多通道,输入大小为(3, depth, height, width),则与2D卷积的操作一样,每次滑窗与3个channels上的 (k_d, k_h, k_w) 窗口内的所有values进行相关操作,得到输出3D图像中的一个value。
参考文章:
2、每次分类的结果为何不同
在神经网络中,采用了Dropout防止过拟合,本网络中以概率p=0.4进行了Dropout,导致有些神经元被丢弃,所以每次的结果会显得不同。
3、进一步提升高光谱图像的分类性能,可以如何改进
通过注意力机制改善网络性能
参考文章:
class_num = 16
# 通道注意力机制
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
# 空间注意力机制
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class HybridSN(nn.Module):
def __init__(self, num_classes, self_attention=False):
super(HybridSN, self).__init__()
self.conv3d_1 = nn.Sequential(
nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(8),
nn.ReLU(inplace = True),
)
self.self_attention = self_attention #默认
self.conv3d_2 = nn.Sequential(
nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(16),
nn.ReLU(inplace = True),
)
self.conv3d_3 = nn.Sequential(
nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU(inplace = True)
)
if self_attention:
self.channel_attention_1 = ChannelAttention(576)
self.spatial_attention_1 = SpatialAttention(kernel_size=7)
self.conv2d_4 = nn.Sequential(
nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0),
nn.BatchNorm2d(64),
nn.ReLU(inplace = True),
)
if self_attention:
self.channel_attention_1 = ChannelAttention(576)
self.spatial_attention_1 = SpatialAttention(kernel_size=7)
self.fc1 = nn.Linear(18496,256)
self.fc2 = nn.Linear(256,128)
self.fc3 = nn.Linear(128,16)
self.dropout = nn.Dropout(p = 0.4)
def forward(self,x):
out = self.conv3d_1(x)
out = self.conv3d_2(out)
out = self.conv3d_3(out)
out = self.conv2d_4(out.reshape(out.shape[0],-1,19,19))
out = out.reshape(out.shape[0],-1)
out = F.relu(self.dropout(self.fc1(out)))
out = F.relu(self.dropout(self.fc2(out)))
out = self.fc3(out)
return out
# 随机输入,测试网络结构是否通
# x = torch.randn(1, 1, 30, 25, 25)
# net = HybridSN()
# y = net(x)
# print(y.shape)















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









