







ti_vig
def pvig_ti_224_gelu(pretrained=False, **kwargs):
class OptInit:
def __init__(self, num_classes=1000, drop_path_rate=0.0, **kwargs):
self.k = 9 # 邻域的数目,默认为9
self.conv = 'mr' # 图卷积层=mr
self.act = 'gelu' # 激活层=gelu
self.norm = 'batch' # batch or instance normalization {batch, instance}
self.bias = True # bias of conv layer True or False
self.dropout = 0.0 # dropout rate
self.use_dilation = True # use dilated knn or not
self.epsilon = 0.2 # stochastic epsilon for gcn
self.use_stochastic = False # stochastic for gcn, True or False
self.drop_path = drop_path_rate
self.blocks = [2,2,6,2] # number of basic blocks in the backbone
self.channels = [48, 96, 240, 384] # number of channels of deep features
self.n_classes = num_classes # Dimension of out_channels
self.emb_dims = 1024 # Dimension of embeddings
opt = OptInit(**kwargs)
model = DeepGCN(opt)
model.default_cfg = default_cfgs['vig_224_gelu']
return model
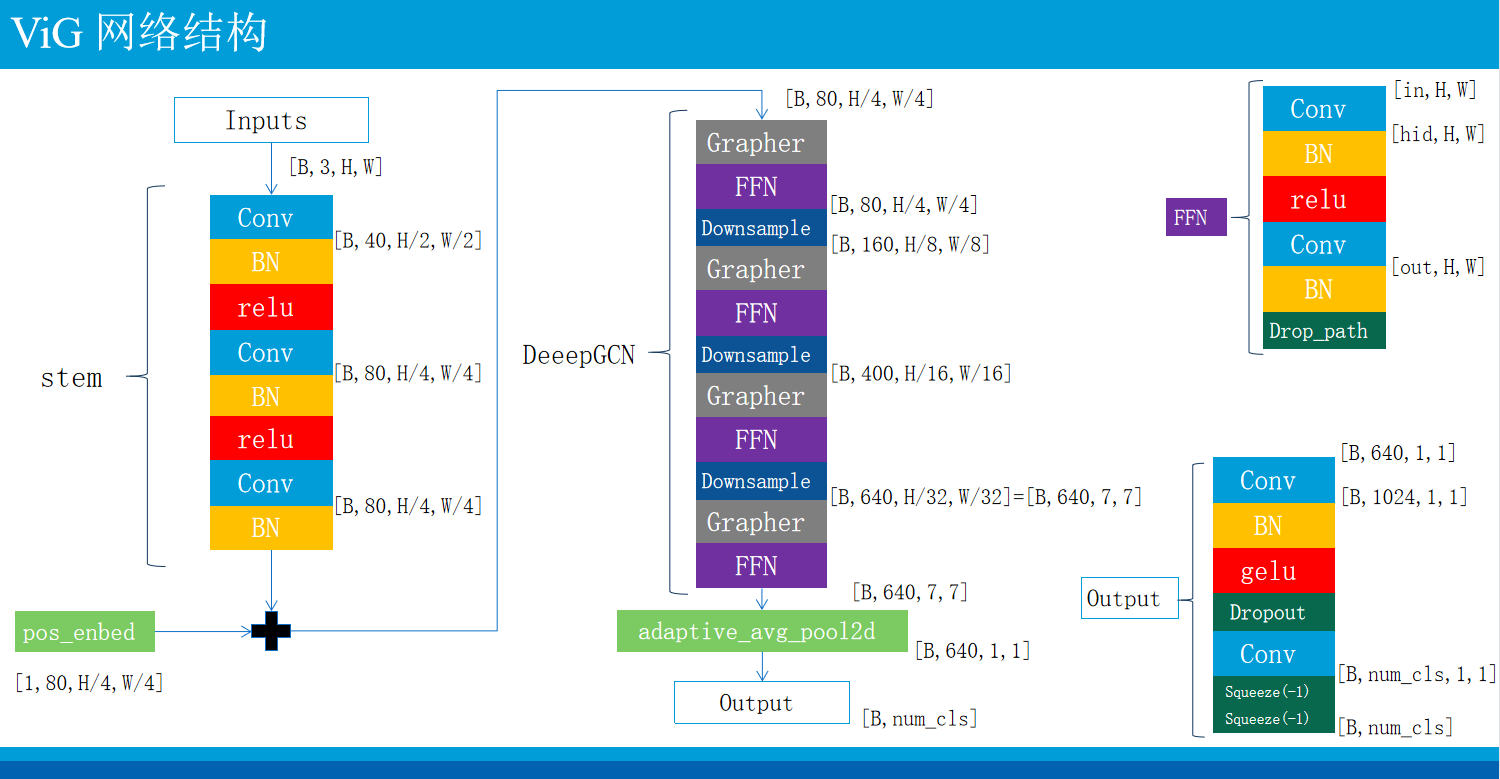
DeepGCN
class DeepGCN(torch.nn.Module):
def __init__(self, opt):
super(DeepGCN, self).__init__()
print(opt)
k = opt.k # k=9
act = opt.act # active method = gelu
norm = opt.norm # norm = batch
bias = opt.bias # bias = true
epsilon = opt.epsilon # epsilon = 0.2
stochastic = opt.use_stochastic # use_stochastic = False
conv = opt.conv # conv = mr
emb_dims = opt.emb_dims # emb_dims = 1024
drop_path = opt.drop_path # drop_path = drop_path_rate = 0.0
blocks = opt.blocks # blocks = [2, 2, 6, 2]
self.n_blocks = sum(blocks) # n_blocks = 12
channels = opt.channels # channels = [80, 160, 400, 640]
reduce_ratios = [4, 2, 1, 1]
# stochastic depth decay rule
# dpr = 0.0 x 12
dpr = [x.item() for x in torch.linspace(0, drop_path, self.n_blocks)]
# num_knn = 9 x 12
num_knn = [int(x.item()) for x in torch.linspace(k, k, self.n_blocks)]
# 最大扩张 max_dilation = 49//9 = 5
max_dilation = 49 // max(num_knn)
# Stem(out_dim=80, act=gelu), output size = [h/4, w/4, 80]
self.stem = Stem(out_dim=channels[0], act=act)
# pos_embed = [1, 80, 56, 56]
self.pos_embed = nn.Parameter(torch.zeros(1, channels[0], 224//4, 224//4))
HW = 224 // 4 * 224 // 4 # 3136
self.backbone = nn.ModuleList([])
idx = 0
for i in range(len(blocks)): # [2, 2, 6, 2], i = 0 1 2 3
if i > 0:
self.backbone.append(Downsample(channels[i-1], channels[i]))
HW = HW // 4 # 784
for j in range(blocks[i]):
self.backbone += [
Seq(Grapher(channels[i], num_knn[idx], min(idx // 4 + 1, max_dilation), conv, act, norm,
bias, stochastic, epsilon, reduce_ratios[i], n=HW, drop_path=dpr[idx],
relative_pos=True),
FFN(channels[i], channels[i] * 4, act=act, drop_path=dpr[idx])
)]
idx += 1
self.backbone = Seq(*self.backbone)
## ----- this part x2 -----
## Grapher(channel=80, num_knn=9, 1, conv=mr, act=gelu, norm=batch, bias=true, stochastic=false, epsilon=0.2,
## reduce_ratios=4, n=3136, drop_path=0.0, relative_pos=True),
## FFN(80, 320, act=gelu, drop_path=0.0)
## ------------------------
## Downsample(80, 160)
## HW = 784
## ----- this part x2 -----
## Grapher(channel=160, num_knn=9, 1, conv=mr, act=gelu, norm=batch, bias=true, stochastic=false, epsilon=0.2,
## reduce_ratios=4, n=784, drop_path=0.0, relative_pos=True),
## FFN(160, 640, act=gelu, drop_path=0.0)
## ------------------------
## Downsample(160, 400)
## HW = 196
## ----- this part x6 -----
## Grapher(channel=400, num_knn=9, 1, conv=mr, act=gelu, norm=batch, bias=true, stochastic=false, epsilon=0.2,
## reduce_ratios=4, n=196, drop_path=0.0, relative_pos=True),
## FFN(400, 1600, act=gelu, drop_path=0.0)
## ------------------------
## Downsample(400, 640)
## HW = 49
## ----- this part x2 -----
## Grapher(channel=640, num_knn=9, 1, conv=mr, act=gelu, norm=batch, bias=true, stochastic=false, epsilon=0.2,
## reduce_ratios=4, n=196, drop_path=0.0, relative_pos=True),
## FFN(640, 2560, act=gelu, drop_path=0.0)
## ------------------------
self.prediction = Seq(nn.Conv2d(channels[-1], 1024, 1, bias=True),
nn.BatchNorm2d(1024),
act_layer(act),
nn.Dropout(opt.dropout),
nn.Conv2d(1024, opt.n_classes, 1, bias=True))
self.model_init()
def model_init(self):
for m in self.modules():
if isinstance(m, torch.nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight)
m.weight.requires_grad = True
if m.bias is not None:
m.bias.data.zero_()
m.bias.requires_grad = True
def forward(self, inputs):
x = self.stem(inputs) + self.pos_embed
B, C, H, W = x.shape
for i in range(len(self.backbone)):
x = self.backbone[i](x)
x = F.adaptive_avg_pool2d(x, 1)
return self.prediction(x).squeeze(-1).squeeze(-1)
Stem
class Stem(nn.Module):
""" Image to Visual Embedding
Overlap: https://arxiv.org/pdf/2106.13797.pdf
"""
def __init__(self, img_size=224, in_dim=3, out_dim=768, act='relu'):
super().__init__()
self.convs = nn.Sequential(
nn.Conv2d(in_dim, out_dim//2, 3, stride=2, padding=1), # in_ch=3, out_ch=40, outputsize=[h/2,w/2,40]
nn.BatchNorm2d(out_dim//2), # 40
act_layer(act), # relu
nn.Conv2d(out_dim//2, out_dim, 3, stride=2, padding=1), # in_ch=40, out_ch=80, outputsize=[h/4,w/4,80]
nn.BatchNorm2d(out_dim), # 80
act_layer(act), # relu
nn.Conv2d(out_dim, out_dim, 3, stride=1, padding=1), # in_ch=80, out_ch=80, outputsize=[h/4,w/4,80]
nn.BatchNorm2d(out_dim),
)
def forward(self, x):
x = self.convs(x)
return x















 163
163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









