









关于特征处理
吴恩达老师的方法
吴恩达老师的视频中所提到的特征处理的一个原因是为了能够更好的进行梯度下降,我们试想一下,有一个多元的目标函数表达式,这个表达式里有很多特征,如果这些特征取值范围不一样,有的是0~1之间的小数,有的是几百几千的大数,那么如果我们进行梯度下降,则损失函数的等高线映射到平面上就是一个很扁的椭圆,如下图所示:
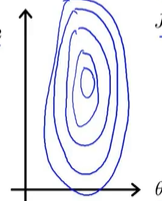
然后就会梯度下降的困难:(1)下降时不稳定 (2)下降速率特别慢,需要比较长的时间才可以达到最优解。
吴恩达老师建议是不需要把特征放缩到同一个范围,只是需要不同特征之间的范围很接近就可以了。
项目中的方法总结
在项目中,不同特征之间的取值相差很大,有些特征0.几,也有些特征能够达到几千的数值,选择的特征处理方法为标准化。
关于训练集测试集的划分
训练集和测试集的划分,一般划分有8:2,7:3 这就不多说了。主要的一个问题是在整个项目代码中,什么时候开始进行训练集和测试集的划分?
在平时的网课视频和资料中,都是将scikit-learn或者datasets里面自带的数据包里的数据调出来,然后标准化 /归一化处理,接下来进行训练集和测试集的划分。
但是考虑到实际项目中,我们最终需要得到一个在面对全新的数据集依旧表现非常好的模型,所以为了提升模型的泛化能力,我们需要在项目代码开始前,即在归一化/标准化之前进行训练集和测试集的划分。然后测试集使用训练集的信息进行数据处理。
关于模型评估
由于项目是分类问题,所以用到了分类问题中最长用的指标:accuracy, precision, recall, f1-score,和ROC曲线AUC值(这俩不仅仅是在二分类中可以用,在多分类也可以绘制,详情请见大佬博客:python实现二分类和多分类的ROC曲线)。
关于假设检验
西瓜书中提到“假设检验中的 ‘假设’ 是对学习器泛化错误率分布的某种判断或猜想,现实任务中我们并不知道学习器的泛化错误率,只能获取其测试错误率,但直观上,二者接近的可能性应比比较大,二者相差很远的可能性比较小。因此,可以通过测试错误率估推出泛化错误率的分布”。
Delong test
二分类中比较不同方法的显著性差异。
这里的不同方法有两种情况:
(1)同一个数据集使用不同的模型
(2)不同的数据集使用同一个模型
Friedman test 和 Nemenyi后续检验
Delong test只能是判断二分类任务,但是对于多分类任务,项目选择使用Friedman test and Nemenyi后续检验。Friedman检验可以比较在多个数据集上,不同算法性能是否有显著性差异,一般设置的P为0.05,如果小于0.05则认为具有显著性差异,这个时候需要Nemenyi后续检验,画出Critical Difference 图(CD图)。
关于Friedman test 在周志华西瓜书上有详细介绍。个人使用体会:这个检验只针对小的数据集数量和少的算法模型有用,猜测如果用较多的算法那么同一个算法在不同数据集上的排名等级就会有前几名和后几名的情况出现,用F检验可能会更好些。
















 3175
3175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











