







朴素的串匹配算法
评价:简单易懂,但效率低下。算法时间复杂度O(m*n)
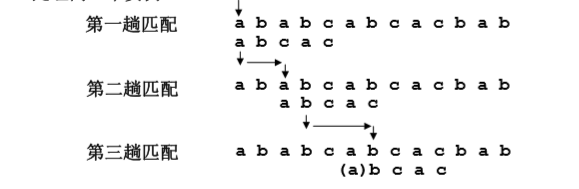
朴素算法的执行过程,设目标串 t: ababcabcacbab,模式串 p: abcac

'''
朴素的串匹配算法
'''
def naive_matching(t,p):
m,n = len(p),len(t)
i,j = 0,0
while i < m and j < n:
if p[i] == t[j]:
i,j = i+1,j+1
else:
i,j = 0,j-i+1
if i == m:
return j-i
return -1
'''
时间复杂度: O(m*n)
缺陷:可能出现回溯,匹配中遇到一对字符串不同时,模式串p将右移一个字符串位置,随后的匹配
回到模式串的开始(重置j=0)
'''
无回溯串匹配算法(KMP算法)
解读:关键在于充分利用了模式串中的信息。
在 pi 匹配失败时,所有 pk(0 ≤ k< i)都已匹配成功(否则 不会考虑 pi 的匹配)。也就是说: tj 之前的 i-1 个字符就是 p 的前 i-1 个字符 。原本应该根据 t 的情况确定前移方式,但实际上可以根据 p 本身的情况确定,可以通过对模式串本身的分析在匹配之前做好 。
结论:对 p 中的每个 i,有一个唯一确定的 ki,与被匹配的串无关。通 过对模式串 p 的预分析,可以得到每个 i 对应的 ki 值
#pnext表构造方法
def gen_pnext(p):
'''生成针对p中各位置i的下一个检查位置表,用于KMP算法'''
i, k, m = 0, -1, len(p)
pnext = [-1] * m
while i < m-1:
if k==-1 or p[i]==p[k]:
i, k=i+1,k+1
pnext[i]=k
else:
k=pnext[k]
return pnext
pnext=gen_pnext('abbcabcaabbcaa')
#KMP算法
def matching_KMP(t,p,pnext):
'''KMP串匹配,主函数'''
j,i=0,0
n,m=len(t),len(p)
while j<n and i<m:
if i==-1 and t[j]==p[i]:
j,i=j+1,i+1
else:
i=pnext[i]
if i==m:
return j-i
return -1















 6497
6497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









