







看了CSDN的一些博客感觉讲的都不是很清晰,这里简单分析一下:
首先基于热重启的学习率衰减策略可以说是余弦退火衰减策略的进化。余弦退火学习率衰减策略在整个训练过程持续衰减直到学习率为0,那么当损失函数的值陷入局部最优值的时候,越来越小的学习率显然难以跳出局部最优值。而热重启很好地解决了这个问题,先摆上公式和图像:
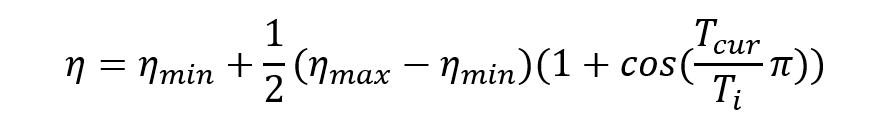

首先利用大白话讲一下为什么叫“热重启”,“重启”指的是每间隔
T
i
T_i
Ti次迭代学习率重启一次,并且每次重启后的状态与之前相同(就好比电脑重启一个道理,暂且我们认定电脑只含有一个操作系统,电脑在运行状态后重新启动是windows系统重启后还是windows,不可能原来是windows系统重启后变为Linux),“热”指的是学习率重启后模型参数仍然是前一次运行状态下更新得到的参数。这样分析就很好理解该方法的原理了,那么
η
m
i
n
\eta_{min}
ηmin指的是每个运行状态下学习率所能衰减到的最小值,
η
m
a
x
\eta_{max}
ηmax即为最大值也是每个重启时刻的初始学习率,
T
i
T_i
Ti则为重启周期,
T
c
u
r
T_{cur}
Tcur为迭代次数,pytorch官网的描述为:When
T
c
u
r
T_{cur}
Tcur
=
=
=
T
i
T_{i}
Ti, set
η
t
\eta_t
ηt
=
=
=
η
m
i
n
\eta_{min}
ηmin. When
T
c
u
r
T_{cur}
Tcur
=
=
=
0
0
0 after restart, set
η
t
\eta_t
ηt
=
=
=
η
m
a
x
\eta_{max}
ηmax. 当
T
c
u
r
T_{cur}
Tcur
=
=
=
T
i
T_{i}
Ti,代入上述公式得到学习率即为
η
m
i
n
\eta_{min}
ηmin;重启后令
T
c
u
r
T_{cur}
Tcur
=
=
=
0
0
0,代入上述公式得到学习率即为
η
m
a
x
\eta_{max}
ηmax,然后每个周期内学习率是余弦式衰减。
另外pytorch封装的方法与上述所讲有所不同:torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0, last_epoch=-1, verbose=False)
optimizer:选择的优化器
T_0(重点):即上述所说的
T
i
T_i
Ti,但是pytorch中指的是累加批次,而不是训练次数,是每T_0个批次训练热重启一次。
T_mult:周期扩大因子,默认为1。如果不为1,则每次热重启周期都会扩大为前一次的T_mult倍,使得学习率衰减的越来越缓慢。
eta_min:即
η
m
i
n
\eta_{min}
ηmin。















09-18
 572
572
572
10-24
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









