







点击【原文】阅读原文,效果更佳!
惩罚和障碍函数
为了简化表示,讨论如下等式约束问题:
min
x
∈
R
n
f
(
x
)
s.t.
c
(
x
)
=
0
\begin{aligned} \min_{{\pmb x} \in \mathbb{R}^n} ~~& f({\pmb x})\\ \text{s.t.} ~~& c({\pmb x}) = \pmb{0} \end{aligned}
xxx∈Rnmin s.t. f(xxx)c(xxx)=000
其中,
c
(
x
)
:
R
n
→
R
m
c({\pmb x}): ~ \mathbb{R}^n \to \mathbb{R}^m
c(xxx): Rn→Rm,或不等式约束问题
min
x
∈
R
n
f
(
x
)
s.t.
c
(
x
)
≤
0
\begin{aligned} \min_{{\pmb x} \in \mathbb{R}^n} ~~& f({\pmb x})\\ \text{s.t.} ~~& c({\pmb x}) \leq \pmb{0} \end{aligned}
xxx∈Rnmin s.t. f(xxx)c(xxx)≤000
罚函数法
动机
在求解约束不容易消去的非线性规划问题时,为了保证大范围收敛(即从任意的初始近似解都能收敛于一个局部解),必须在"减小目标值"和"保留在可行域内或临近可行域"这两个目标之间进行折衷,这就不可避免地引入了罚函数的思想。
定义
罚函数是目标 f f f 和约束 c c c 之间的某种组合,它通过惩罚控项制违反约束来极小化 f f f。
Courant 罚函数
最早的罚函数由 Courant 于 1943 年提出,其采用约束违反量的平方作为惩罚项,因此也称为 Courant 二次罚函数。
例 考虑问题
min
x
s.t.
1
−
x
=
0
\begin{aligned} \min ~~& x\\ \text{s.t.} ~~& 1 - x = 0 \end{aligned}
min s.t. x1−x=0
的罚函数
ϕ
(
x
,
σ
)
=
x
+
1
2
σ
(
1
−
x
)
2
\phi(x,\sigma) = x + \frac{1}{2}\sigma(1 - x)^2
ϕ(x,σ)=x+21σ(1−x)2
如下图所示:
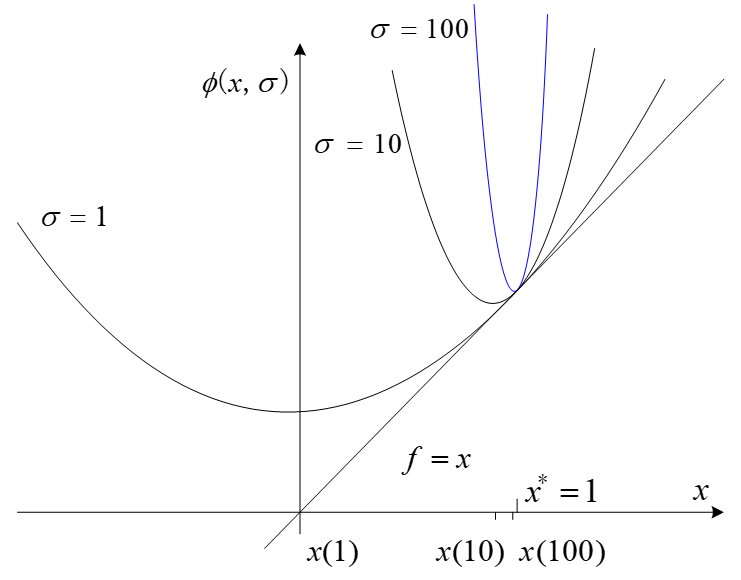
易得当 σ → ∞ \sigma \to \infty σ→∞ 时, ϕ ( x , σ ) \phi(x,\sigma) ϕ(x,σ) 的极小点趋近于原问题的最优解 x ∗ = 1 x^* = 1 x∗=1。
由此,人们提出了求解一系列极小化问题的技术,成为序列最小化技术。
算法 1 序列极小化技术算法
-
选择一个固定的序列 { σ i : i = 1 , 2 , 3 , … } = { 10 , 1 0 2 , 1 0 3 , 1 0 4 , … } \{\sigma_i : i = 1, 2, 3, \dots\} = \{10,10^2,10^3,10^4,\dots\} {σi:i=1,2,3,…}={10,102,103,104,…},使得 σ k → ∞ \sigma_k \to \infty σk→∞;
-
do 对于 ∀ σ i \forall \sigma_i ∀σi,求解
min x ϕ ( x , σ i ) \min_{\pmb x} ~~ \phi({\pmb x}, \sigma_i) xxxmin ϕ(xxx,σi)
的一个局部最优解 x ( σ i ) {\pmb x}(\sigma_i) xxx(σi)while c ( x ( σ i ) ) c({\pmb x}(\sigma_i)) c(xxx(σi)) 充分小。
事实上,算法 1 不能在有限步内求得全局解,仅是一个理想化的算法。尽管适当放松精度可以保证收敛,但还需假设
- 局部极小点 x ( σ i ) {\pmb x}(\sigma_i) xxx(σi) 存在;
- 得到的 x ( σ i ) {\pmb x}(\sigma_i) xxx(σi) 尽可能精确。
在实际应用中,无论是非线性问题无界还是存在局部解,该假设都是不成立的。
定理 1 假设每次得到无约束极小化问题地全局极小点,若 σ k ↿ ∞ \sigma_k \upharpoonleft \infty σk↿∞,则
- { ϕ ( x , σ k ) } \{\phi({\pmb x}, \sigma_k)\} {ϕ(xxx,σk)} 单调递增;
- { c ( k ) T c ( k ) } \{{c^{(k)}}^Tc^{(k)}\} {c(k)Tc(k)} 单调递减;
- { f ( k ) } \{f^{(k)}\} {f(k)} 单调递增,
同时 c ( k ) → 0 c^{(k)} \to 0 c(k)→0,且 { x ( k ) } \{{\pmb x}^{(k)}\} {xxx(k)} 的任何据点是原始问题的解。
证明 略。
注意 结论 2 表明 { x ( k ) } \{{\pmb x}^{(k)}\} {xxx(k)} 是从可行域外接近原问题的解,因此也是外部罚函数。
Lagrange 乘子估计
定义向量 λ i ( k ) = σ k c i ( k ) , i = 1 , 2 , … , m \lambda_i^{(k)} = \sigma_k c_i^{(k)}, i = 1,2,\dots, m λi(k)=σkci(k),i=1,2,…,m 为 Language 乘子的估计,有如下收敛性性质。
定理 2 假设每次得到无约束问题的局部解,若
σ
k
↿
∞
\sigma_k \upharpoonleft \infty
σk↿∞,
x
∗
{\pmb x}^*
xxx∗ 是序列的一个聚点,且
r
a
n
k
(
A
∗
)
=
m
\mathrm{rank}({\pmb A}^*) = m
rank(AAA∗)=m,则
x
∗
{\pmb x}^*
xxx∗ 是原问题的KKT点,有
λ
(
k
)
=
λ
∗
+
o
(
1
)
c
(
k
)
=
λ
∗
σ
k
+
o
(
1
σ
)
σ
k
c
(
k
)
T
c
(
k
)
=
λ
∗
T
λ
∗
σ
k
+
o
(
1
σ
)
\begin{aligned} \lambda^{(k)} & = & \lambda^* + o(1)\\ c^{(k)} & = & \frac{\lambda^*}{\sigma_k} + o(\frac{1}{\sigma}) \\ \sigma_k {c^{(k)}}^Tc^{(k)} & = & \frac{{\lambda^*}^T \lambda^*}{\sigma_k} + o(\frac{1}{\sigma}) \end{aligned}
λ(k)c(k)σkc(k)Tc(k)===λ∗+o(1)σkλ∗+o(σ1)σkλ∗Tλ∗+o(σ1)
若在
x
∗
,
λ
∗
{\pmb x}^*, \lambda^*
xxx∗,λ∗ 处二阶充分条件成立,则
f
∗
=
ϕ
∗
=
ϕ
(
k
)
+
1
2
σ
k
c
(
k
)
T
c
(
k
)
+
o
(
1
σ
)
h
(
k
)
=
T
∗
λ
∗
σ
k
+
o
(
1
σ
)
\begin{aligned} f^* & = & \phi^* = \phi^{(k)} + \frac{1}{2}\sigma_k {c^{(k)}}^Tc^{(k)} + o(\frac{1}{\sigma})\\ h^{(k)} & = & \frac{T^* \lambda^*}{\sigma_k} + o(\frac{1}{\sigma}) \end{aligned}
f∗h(k)==ϕ∗=ϕ(k)+21σkc(k)Tc(k)+o(σ1)σkT∗λ∗+o(σ1)
其中,
h
(
k
)
=
x
(
k
)
−
x
∗
h^{(k)} = {\pmb x}^{( k)} - {\pmb x}^*
h(k)=xxx(k)−xxx∗,
T
∗
T^*
T∗ 定义为
[ W ∗ A ∗ A ∗ T 0 ] = [ H ∗ T ∗ T ∗ T U ∗ ] \begin{bmatrix} W^* & A^*\\ {A^*}^T & 0 \end{bmatrix} = \begin{bmatrix} H^* & T^*\\ {T^*}^T & U^* \end{bmatrix} [W∗A∗TA∗0]=[H∗T∗TT∗U∗]
事实上,对于二次罚函数,有
∇
2
ϕ
(
x
(
k
)
,
σ
k
)
=
W
(
k
)
+
σ
k
A
(
k
)
A
(
k
)
T
\nabla^2 \phi({\pmb x}^{(k)},\sigma_k) = W^{(k)} + \sigma_k A^{(k)} {A^{(k)}}^T
∇2ϕ(xxx(k),σk)=W(k)+σkA(k)A(k)T
其中,
W
(
k
)
=
∇
x
2
L
(
x
(
k
)
,
λ
(
k
)
)
W^{(k)} = \nabla^2_{\pmb x} \mathcal{L}({\pmb x}^{(k)},\lambda^{(k)})
W(k)=∇xxx2L(xxx(k),λ(k)),
λ
i
(
k
)
=
σ
k
c
i
(
k
)
,
i
=
1
,
2
,
…
,
m
\lambda_i^{(k)} = \sigma_k c_i^{(k)}, i = 1,2,\dots,m
λi(k)=σkci(k),i=1,2,…,m。其特点是一阶可微,但需要满足
σ
k
→
∞
\sigma_k \to \infty
σk→∞。
不等式约束罚函数
不等式约束问题,可以等价地转化为等式约束
c
(
x
)
≤
0
⟺
max
{
c
(
x
)
,
0
}
=
0
c({\pmb x}) \leq 0 \iff \max\{c({\pmb x}),0\} = 0
c(xxx)≤0⟺max{c(xxx),0}=0
从而,不等式约束问题地罚函数为
ϕ
(
x
,
σ
)
=
f
(
x
)
+
1
2
σ
∑
i
∈
I
max
{
c
i
(
x
)
,
0
}
\phi({\pmb x}, \sigma) = f({\pmb x}) + \frac{1}{2}\sigma\sum_{i \in \mathcal{I}} \max\{c_i({\pmb x}),0\}
ϕ(xxx,σ)=f(xxx)+21σi∈I∑max{ci(xxx),0}
障碍函数
由于该方法适合可行域外无定义的约束问题,因为得到的序列极小化问题也是可行的,因此该方法也被成为内点法。
定义
障碍函数法是一种求解不等式约束问题的序列极小化方法,其旨在障碍项在边界上取值为无穷大,从而在任何时候都能满足约束。
对数障碍函数
1955 年,Frisch 提出对数障碍函数
ϕ
(
x
,
μ
)
=
f
(
x
)
−
μ
∑
i
log
(
−
c
i
(
x
)
)
\phi({\pmb x}, \mu) = f({\pmb x}) - \mu \sum_i \log(-c_i({\pmb x}))
ϕ(xxx,μ)=f(xxx)−μi∑log(−ci(xxx))
例 对于不等式约束问题
min
x
s.t.
1
−
x
≤
0
\begin{aligned} \min ~~& x\\ \text{s.t.} ~~& 1 - x \leq 0 \end{aligned}
min s.t. x1−x≤0
其对数障碍函数
ϕ
(
x
,
μ
)
=
x
−
μ
log
(
x
−
1
)
\phi({ x},\mu) = { x} - \mu \log ({ x - 1})
ϕ(x,μ)=x−μlog(x−1) 图像如下,可以看出当
μ
k
→
0
\mu_k \to 0
μk→0 时,
x
(
μ
k
)
→
x
∗
x(\mu_k) \to x^*
x(μk)→x∗。
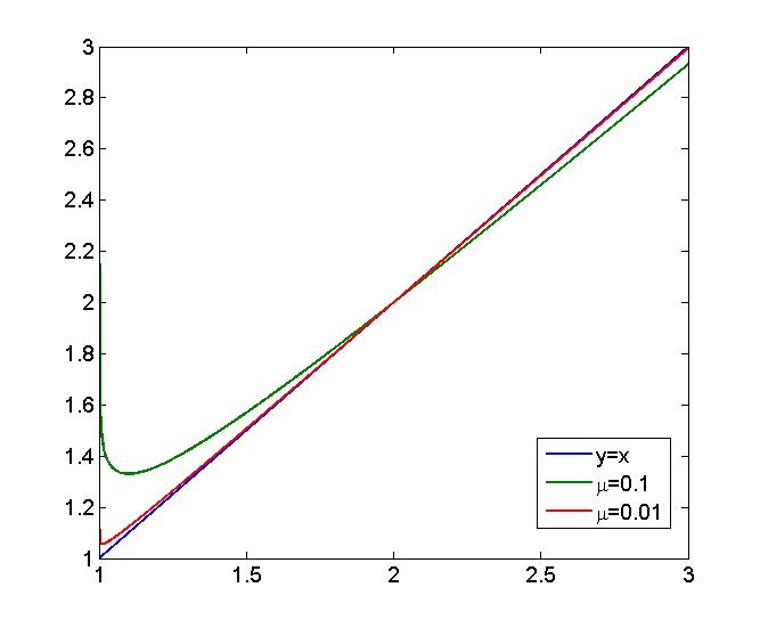
特点:原问题是凸规划时,障碍函数时凸函数。一阶可微,需要满足 μ → 0 \mu \to 0 μ→0。
倒数障碍函数
1961 年,Carroll 提出倒数障碍函数
ϕ
(
x
,
μ
)
=
f
(
x
)
−
μ
∑
i
=
1
m
[
c
i
(
x
)
]
−
1
\phi({\pmb x}, \mu) = f({\pmb x}) - \mu \sum_{i = 1}^m [c_i({\pmb x})]^{-1}
ϕ(xxx,μ)=f(xxx)−μi=1∑m[ci(xxx)]−1
一般来说,倒数障碍函数比二次罚函数和对数障碍函数要差。
内点法(路径跟踪法)
对数障碍函数法也称为原始内点法,其中乘子由原始变量确定。
令 C ( x ) = d i a g ( c 1 ( x ) , c 2 ( x ) , ⋯ , c m ( x ) ) C(x) = \mathrm{diag} (c_1(x), c_2(x),\cdots,c_m(x)) C(x)=diag(c1(x),c2(x),⋯,cm(x)), A ( x ) = [ a 1 ( x ) , a 2 ( x ) , … , a m ( x ) ] A(x) = [a_1(x), a_2(x),\dots,a_m(x)] A(x)=[a1(x),a2(x),…,am(x)],则
KKT 条件
g ( x ) + A ( x ) λ = 0 C ( x ) λ = 0 c ( x ) ≤ 0 λ ≥ 0 \begin{aligned} g(x) + A(x) \lambda &=& 0 \\ C(x) \lambda & = & 0\\ c(x) & \leq & 0 \\ \lambda & \geq & 0 \end{aligned} g(x)+A(x)λC(x)λc(x)λ==≤≥0000
扰动的 KKT 条件
g ( x ) + A ( x ) λ = 0 C ( x ) λ = − μ c ( x ) < 0 λ > 0 \begin{aligned} g(x) + A(x) \lambda &=& 0 \\ C(x) \lambda & = & \color{blue}{- \mu}\\ c(x) & \color{blue}{<} & 0 \\ \lambda & \color{blue}{>} & 0 \end{aligned} g(x)+A(x)λC(x)λc(x)λ==<>0−μ00
动机
令
μ
→
0
\mu \to 0
μ→0,跟踪方程组
g
(
x
)
+
A
(
x
)
λ
=
0
C
(
x
)
+
μ
=
0
\begin{aligned} g(x) + A(x) \lambda & = & 0 \\ C(x) + \mu & = & 0 \end{aligned}
g(x)+A(x)λC(x)+μ==00
保存
c
(
x
)
<
0
,
λ
>
0
c(x) < 0,\lambda>0
c(x)<0,λ>0 的解,直至
μ
\mu
μ 逐渐递减至零。
参考资料
[1] 刘红英,夏勇,周永生. 数学规划基础,北京,北京航空航天大学出版社,2012.















 2100
2100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









