






 文章介绍了如何使用L5Kit库处理Lyft数据集,特别是通过visualisation_config.yaml设置概率阈值和使用agent_mask进行数据筛选。agent_mask包含每个agent的历史和未来出现次数,用于确保选取的agent在训练中有足够的上下文信息。筛选目的是关注更重要的agent,数据存储结构包括zarr文件和meta.json等元数据。
文章介绍了如何使用L5Kit库处理Lyft数据集,特别是通过visualisation_config.yaml设置概率阈值和使用agent_mask进行数据筛选。agent_mask包含每个agent的历史和未来出现次数,用于确保选取的agent在训练中有足够的上下文信息。筛选目的是关注更重要的agent,数据存储结构包括zarr文件和meta.json等元数据。
lyft
schma
https://woven-planet.github.io/l5kit/data_format.html
lyft数据筛选说明
有两个文件可以进行设置
1.visualisation_config.yaml
设置方法:filter_agents_threshold: #识别出来的概率
=0.0 ->all ;
=1 ->none;
2.dataset中含有的agent_mask
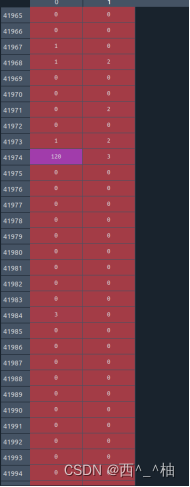
这个是2.agent_mask打印出来的数据
past/future | 0 | 10 | 30 | 50 |
±------------±--------±-------±------±------+
| 0 | 1893736 | 116054 | 64972 | 42984 |
| 10 | 116054 | 83760 | 52277 | 36140 |
| 30 | 64972 | 52277 | 36140 | 26364 |
| 50 | 42984 | 36140 | 26364 | 19560 |
解释:agent有10历史数据和30的未来数据的数量有:52277 个
这个是数据集已经定义好的,而且官方推荐在训练时,使用agent_mask进行筛选
具体实现过程:
agent_mask含有两列,行数与总的scensor×frame相同。
第一列记录了为该时刻agent 之前出现了多少次,
第二列记录了为该时刻agent 之后出现了多少次,
当前的配置是只有agent存在了至少10次且未来还存在一次才会被保留
举个例子:
agnet从1s出现,第20s离开。1s为1帧。
当t=5时,agent共出现5次,筛掉
当t=11时,agnet共出现11次,入选
当t=20时,agent未来次数为0,晒掉。
agent——mask 数据截图
在这里插入图片描述
参考文档:https://woven-planet.github.io/l5kit/data_format.html#short-introduction-to-zarr 里面的AgentDataset小节
总结:agent筛选是为了把筛选出我们更需要关心的agent。
dataset 文件存放:
meta.json需要从semantic_map剪切出来放到上层目录的l5kit_data里面
yaml文件:
prediction-dataset/
+- scenes/
+- sample.zarr
+- train.zarr
+- train_full.zarr
+- aerial_map/
+- aerial_map.png
+- semantic_map/
+- semantic_map.pb
+- meta.json
调用agent_dataset = AgentDataset(cfg, zarr_dataset, rast)得到agent没有分类(category)
需要在AgentDataset添加下面的函数:
tmp = self.get_frame(scene_index, state_index, track_id=track_id)
tmp["label_probabilities"] =self.dataset.agents[index]["label_probabilities"]
在这里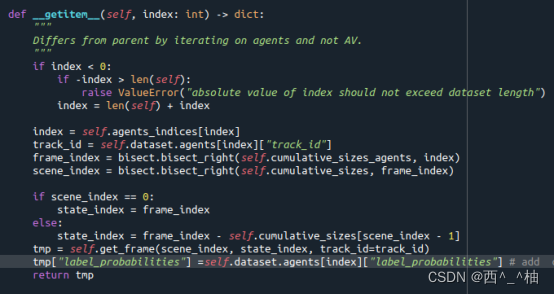
图片描述
















 371
371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











