







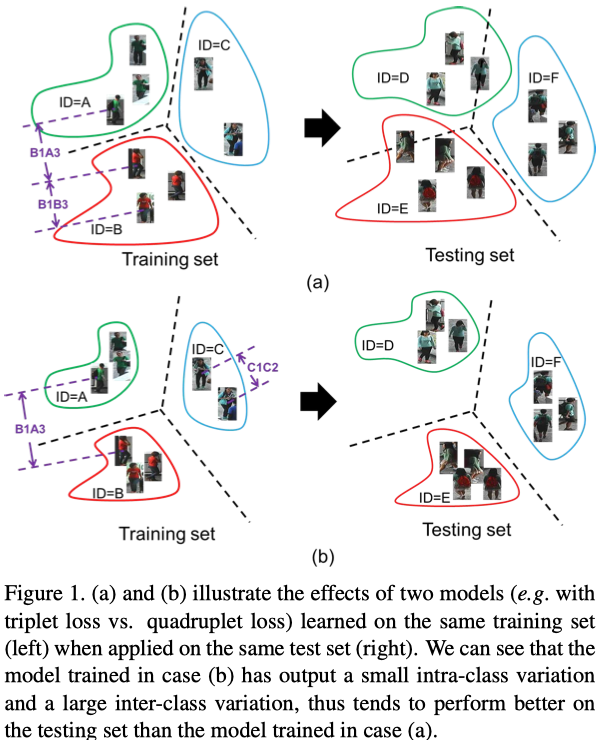
之前的工作通常将person ReID作为一个ranking task,并且使用triplet loss,triplet loss主要是为了在映射空间中获得一个图像和identities的正确顺序,但是基于这种方法的模型,泛化能力不好,作者认为这潜在的原因是由于triplet loss会导致一个相对较大的类内差异,通过缩小类内差异并且增加类间差异可以进行改善
针对上述问题,作者基于triplet loss进行修改,提出了一个quadruplet ranking loss, 实现了缩小类内差异以及增加类间差异
之前的工作通常将person ReID作为一个ranking task,并且使用triplet loss,triplet loss主要是为了在映射空间中获得一个图像和identities的正确顺序,但是基于这种方法的模型,泛化能力不好,作者认为这潜在的原因是由于triplet loss会导致一个相对较大的类内差异,通过缩小类内差异并且增加类间差异可以进行改善
针对上述问题,作者基于triplet loss进行修改,提出了一个quadruplet ranking loss, 实现了缩小类内差异以及增加类间差异
该loss是基于两方面进行设计的:1)获得正确的对顺序 2)推远负样本
作者并且提到,第二方面对于模型训练时的性能提升可能没有很大的必要,但是对于在测试集上的泛化能力的增强帮助很大
作者基于quadruplet loss提出了一个quadruplet deep network,引入了一个margin-based 在线难负样本挖掘来选择难负样本来训练模型,并且自适应的调整margin
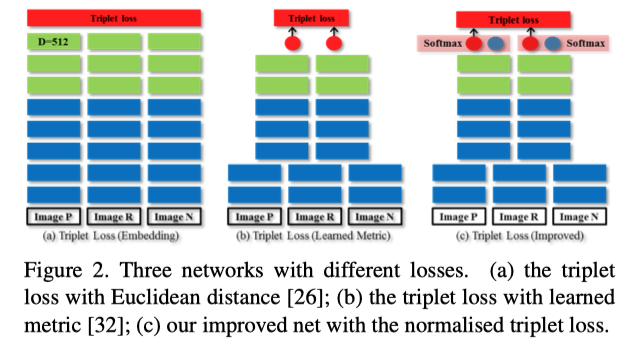
The triplet loss
使得xj相比于xk更接近xi

采用欧氏距离来衡量两个图像特征之间的相似度
作者使用一个可学习矩阵g(xi, xj)来替换欧式距离,这样可以有效的建模查询图像和图像集的复杂关系,如图2(b)
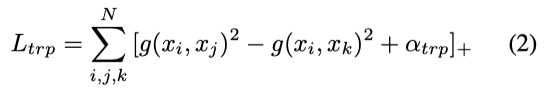
在公式(1)中,由于经过了正则化,因此欧氏距离的输出在[0,1]之间,但是在(2)中,g(xi, xj)是一个值而不是一个向量,因此不能在[0,1]之间,并且可能使得margin无效
The quadruplet loss
作者首先提出对于图2(b)缺乏正则化的优化方法,使用一个带有两个维度输出的全连接层,如图2(c),由于g(x i, x j)表示两个图像之间的距离,越大表示两个图像越不相似,因此g(x i, x j)的值和两个图像不相似的概率成正比
因此作者认为全连接层两个输出之一在一定程度上可以被视为两个图像不相似的概率,作者使用了一个softmax layer对这两个输出进行正则化,可以将输出范围控制在[0,1],然后将其中一个输出维度作为两个图像不相似个概率,送到loss中进行训练
Triplet loss训练仅基于正负样本对,作者在quadruplet loss中引入了一个新的约束,在不同的负样本对中推远正负样本对间的距离

该损失的第一项和triplet loss 相同,关注于正负样本对之间的相对距离,第二项是一个新的约束,考虑了正样本对与不同负样本对与负样本之间的距离,通过这损失使得最小类间距离大于最大类内距离
由于第二项仅做为一个辅助项,因此它不应该主导训练过程,和第一项有着不等的重要性
作者采用了margin阈值来决定这两项的权重,具体为,是的a1>a2
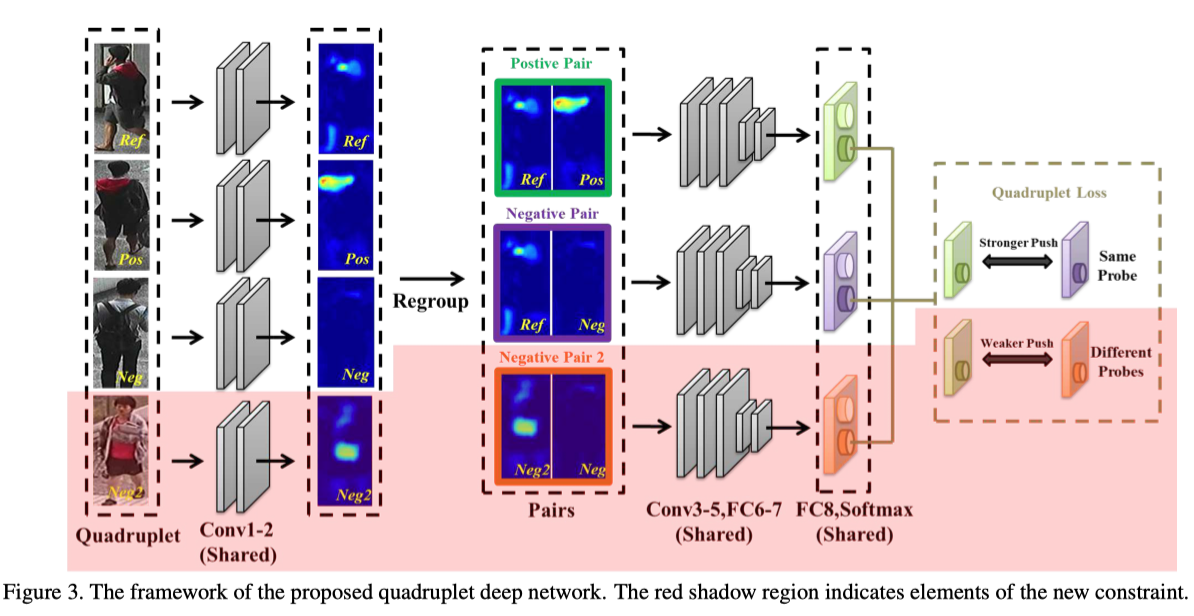
作者使用正样本对和负样本对距离分布的平均值来自适应的调整margin
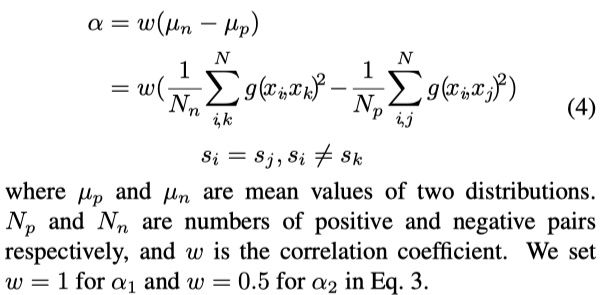

在训练过程中,只有样本距离小于平均距离的样本才通过反向传播,作为难样本
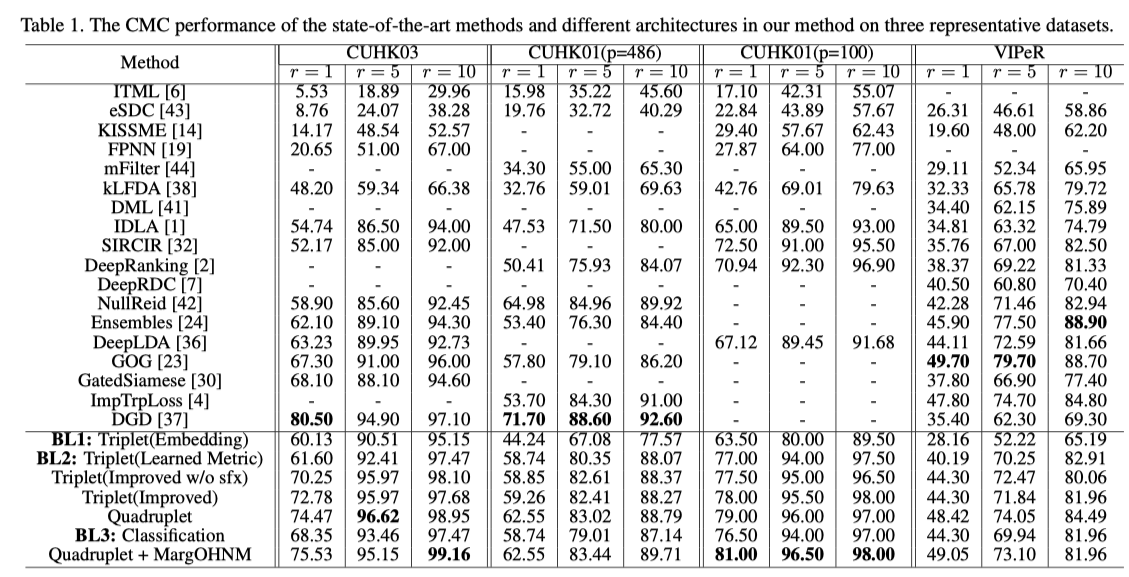
Experiments















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









