







Consistent-Teacher:
Towards Reducing Inconsistent Pseudo-targets in Semi-supervised Object Detection
一致性教师模型:减少一致性为标签的半监督目标检测
引用:
Xinjiang Wang, Xingyi Yang, Shilong Zhang, Yijiang Li, Litong Feng, Shijie Fang, Chengqi Lyu, Kai Chen, Wayne Zhang
; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 3240-3249
出处:

摘要:
在这项研究中,我们深入探讨了半监督目标检测(SSOD)中伪标签的不一致性。核心观察是,振荡的伪目标削弱了准确性检测器的训练。它向学生网络注入噪声,导致严重的过拟合问题。因此,本文提出了一种系统性的解决方案,
称为"Consistent-Teacher"模型,以减少这种不一致性。
首先,使用自适应锚点分配(
ASA)替代静态的基于
IoU 的策略,这使得学生网络对噪声的伪边界框更加抵抗。
然后,通过设计一个
3D特征对齐模块
(FAM-3D)来校准子任务的预测。它允许每个分类特征以自适应的方式查询在任意尺度和位置上适合回归任务的最佳特征向量。
最后,采用高斯混合模型(GMM)动态修正伪边界框的得分阈值,
从而在早期阶段稳定ground truth的数量并在训练过程中弥补不可靠的监督信号。
"Consistent-Teacher"模型 在大范围的 SSOD 评估中表现出强大的结果。在只有 MS-COCO 数据集10%有注释的情况下,使用 ResNet-50 骨干网络,它的平均精度(mAP)达到了40.0,超过了之前使用伪标签的基线结果约3个 mAP。当在完全有注释的 MS-COCO 数据集上进行训练,并使用额外的无标签数据时,性能进一步提高到 47.7 mAP。
1 引言
(1)半监督目标检测的相关定义:半监督目标检测(SSOD)[3、5、12、12、13、17、24、25、30、36、43、44]的目标是借助大量未标记数据来辅助训练目标检测器。常见的做法是首先在带有标签的数据上训练一个教师模型,然后在未标记数据上生成伪标签和伪边界框,作为学生模型的Ground Truth(GT)。相反,学生检测器预期在网络随机性[35]或数据增强[12、30]的情况下做出一致的预测。此外,为了提高伪标签的质量,教师模型会通过学生参数的移动平均[24、36、44]来更新。
(2)目前半监督学习中存在的问题:
在这项研究中,我们指出半监督检测器的性能仍然受到伪目标的不一致性的阻碍。
不一致(Inconsistency)意味着伪框可能高度不准确,并且在不同的训练阶段差异很大。因此,不一致的振荡边界框 (bbox) 将 SSOD 预测与累积误差的偏差。与半监督分类不同,
SSOD 有一个额外的步骤,可以将一组伪框分配给每个 RoI/anchor 作为密集监督。
SSOD常见的网络分类:常见的两阶段[24,30,36]和单阶段[4,42] SSOD网络采用静态标准进行锚点分配,如IoU评分或中心度。我们观察到静态分配对教师预测的边界框中的噪声敏感,因为伪框中的小扰动可能会极大地影响分配结果。因此,它会导致对未标记图像的严重过度拟合。
为了验证这种现象,本文在
MS-COCO 10% 数据上使用标准的基于
IoU 的分配训练了一个单阶段检测器。如图 (1) 所示,教师输出的微小变化导致伪边界框边界中的强噪声(stong noise in the boundaries of pseudo-bboxes),导致错误目标与基于静态
IoU 的分配下附近的对象相关联。这是因为一些
inactivated anchors在学生网络中被错误地分配了积极性。因此,网络过度拟合,因为它为相邻对象生成不一致的标签。在未标记图像的分类损失曲线中也观察到过度拟合。

Figure 1. SSOD 在 COCO 10% evaluation上的不一致问题说明。
(左)图中比较了Mean-Teacher和本文提出的Consistency-Teacher之间的训练损失。
在Mean-Teacher中,不一致的伪目标会导致分类分支的过拟合,而回归损失难以收敛。
相比之下,本文的方法为学生设置了一致的优化目标,有效地平衡了这两个任务并防止过度拟合。
(右)快照用于动态的伪标签和赋值。
Green 和 Red bbox 分别指极地熊的真实和伪 bbox。
红点是伪标签分配的anchor。
热图表示教师预测的密集置信度分数(越大越亮)。附近的board最终被错误地归类为基线中的极地熊(polar),
而本文的自适应分配(adaptive assignment)可以防止过度拟合
。(创新)
标签飘移问题:通过专门的调查,作者发现导致drifting pseuda-label(为标签飘移)的重要因素是分类和回归任务之间的不匹配。通常,仅使用分类分数来过滤 SSOD 中的伪框。然而,置信度并不总是表明 bbox 的质量。因此,两个具有相似分数的锚点可以具有显着不同的预测伪框,从而导致更多的错误预测和标签漂移。这种现象如图(1)所示,MeanTeacher 在 T = 104K 周围具有不同的伪框。因此,bbox 的质量与其置信度分数之间的不匹配将导致嘈杂的伪 bbox,这反过来又会加剧label drifting。
广泛使用的硬阈值(hard threshold)方案也会导致伪标签中的阈值不一致。传统的 SSOD 方法利用静态阈值进行学生训练。然而,阈值是一个超参数,它不仅需要仔细调整,而且还应该根据模型在不同时间步的能力动态调整。在 Mean-Teacher 范式中,在硬阈值方案下,伪bbox 的数量可能从太少增加到太多,这会导致学生效率低下和有偏见的监督。
一、
半监督目标检测任务中面临的挑战: (伪标签的不一致性问题或伪标签飘移
)
i) 导致伪标签漂移的重要因素是分类和回归任务之间的不匹配。通常,只使用分类分数来过滤伪边界框。然而,置信度不总是准确反映边界框的质量,导致错误预测和标签漂移。
ii) 使用硬阈值方案也会导致伪标签的阈值不一致,进一步加剧了标签漂移问题。
二、本文的研究动机:
因此,作者旨在提出一种新的教师模型,即提出了 Consistency-Teacher 来解决上述问题,即伪标签的不一致性问题。
三、解决思路:
首先,通过成本感知自适应样本分配 (ASA)简单地替换基于静态 IoU 的锚点分配极大地缓解了密集伪目标不一致的影响。在每个训练步骤中,计算每个伪bbox 与学生网络预测之间的匹配成本。只有成本最低的特征点被分配为正。它减少了教师的高响应特征(high-response features)与学生分配的正伪目标之间的不匹配,抑制了过拟合。
然后,校准分类和回归任务,以便教师的分类置信度更好地代表 bbox 质量。它为相似置信度分数的锚点生成一致的伪 bbox,从而减少伪bbox 边界的振荡。受 TOOD的启发,
作者提出了一个 3D 特征对齐模块 (FAM-3D),它允许分类特征的意义并在其邻域中采用最佳特征进行回归。与单尺度搜索不同,FAM-3D 也重新排序了用于跨尺度回归的特征金字塔。通过这种方式,统一的置信度分数通过改进的对齐模块准确地衡量分类和回归的质量,并最终为 SSOD 的学生带来一致的伪目标。(有些难理解)
最后,针对pseudo-bboxes中阈值不一致的问题,采用高斯混合模型(Gaussian Mixture Model, GMM)在训练过程中为每个类别生成自适应阈值。将每个类别的置信度分数视为正分布和负分布的加权和,并使用最大似然估计预测每个高斯分布的参数。预计该模型将能够在不同的训练步骤中自适应地推断最佳阈值,以稳定正样本的数量。
四、创新:
所提出的Consistent-Teacher 大大超越了当前的 SSOD 方法。文中的方法达到了 40.0 mAP,在 MS-COCO 上有 10% 的标记数据,这是比最先进的还高.3 mAP。当使用 100% 标签以及额外的未标记 MS-COCO 数据时,性能进一步提高到 47.7 mAP。Consistent-Teacher 的有效性也针对标记数据和其他数据集的其他比率进行了测试。具体来说,本文在以下几个方面做出了贡献。
作者对SDRS 中inconsistent target problem的首次深入研究,造成严重的过拟合问题。
文中引入了一个自适应样本分配来稳定噪声伪框和锚点之间的匹配,从而对学生进行稳健训练。
开发了一个 3D 特征对齐模块 (FAM3D) 来校准分类置信度和回归质量,从而提高伪 bbox 的质量。
采用 GMM 在训练过程中灵活地确定每个类的阈值。自适应阈值随着时间的推移而演变,减少了 SSOD 的阈值不一致。
Consistent-Teacher 在广泛的评估上取得了令人信服的改进,并作为 SSOD 的new solid baseline。
五
、方法
Consistent-Teacher
:
在本节中,我们将详细说明我们的“一致性教师”是如何解决伪标签的不一致性问题的。它由三个关键模块组成,即自适应样本分配、3D特征对齐模块和基于高斯混合的阈值分割。完整的示意图如图2所示。

图2。我们设计了三个模块来解决SSOD中的不一致性,其中GMM动态确定阈值;三维特征对齐校准回归质量;自适应分配基于匹配成本来分配锚点
5
.1 基线半监督检测器
我们采用一般的半监督目标检测(SSOD)范例作为基线,即使用RetinaNet检测器的Mean-Teacher[24, 32, 36]管道。教师模型是学生检测器的指数移动平均值[32]。未标记的图像首先经过弱增强处理,然后输入到教师检测器中生成伪边界框(pseudo-bboxes)。伪边界框然后被用作学生网络的监督,学生网络的未标记图像被强烈抖动。同时,学生检测器以标记的图像作为输入,学习分类和回归的判别式表示。给定一个标记集D_L = {x_li, y_li}N,其中x_li是第i个标记图像,y_li是其对应的标签
。


5.2 一致性自适应样本分配
原始的缺点:在RetinaNet中,每个锚点只有在其与真实边界框(GT bbox)的 IoU 大于一个阈值时才被分配为正样本。这种静态标签分配方式破坏了半监督学习中的一个重要性质。以分类为例,实例级别的伪标签应满足

即伪标签c_hat应与其自身的预测相一致。然而,当采用静态锚点分配到SSOD时,这个规则被打破了。也就是说,锚点的分配标签有时会与它们自己的预测相矛盾,这是图1中伪标签漂移现象的根源。
文章想法:
因此,我们建议将伪边界框分配给最小化其损失的锚点。即:

对于Eq. 3,一个简单的解决方案是将损失最小的锚点指定为伪bbox的正锚点。在实践中,计算每个锚点和伪bbox之间的匹配成本,并将成本最低的锚点视为正锚点。给定锚点n,每个伪bbox yl与来自锚点的预测pn之间的代价计算为

通过每个伪边界框的匹配成本,将具有前K个最低成本的锚点分配为正样本。由于分配是根据模型的检测质量进行的,因此伪边界框中的噪声对特征点分配的影响可以忽略不计。
我们知道,监督目标检测中采用了类似的锚点分配方法[2, 10, 11],因此我们采用了统一的分配方式,适用于有标签和无标签的图像。尽管它们的形式相似,但我们的ASA模块解决了独特的伪标签漂移问题,而不是为监督设置中的物体变化提供服务。
在监督目标检测中,通常采用类似的锚点分配方法[2, 10, 11]。因此,我们在半监督目标检测中使用了统一的分配方式,适用于有标签和无标签的图像。尽管这些方法在形式上相似,但我们的自适应锚点分配(ASA)模块解决了独特的伪标签漂移问题,而不是为监督设置中的物体变化提供服务。换句话说,ASA模块专门应对了伪标签在半监督目标检测中的不一致性问题,而不是用于传统的有监督目标检测中处理物体变化的情况。
5.3
通过3-D特征对齐的BBox一致性
在常见的
SSOD
框架中,伪盒是完全根据分类分数生成的。然而,高置信度预测并不总是保证准确的bbox定位[36]。这又造成了伪bbox中的噪声。因此,受ood[9]的启发,我们引入了一个
3-D Feature Alignment Module (FAM-3D)
来标定具有分类置信度的bbox定位。它允许每个分类特征自适应地定位回归任务的最优特征.
假设特征金字塔是P,其中P(i; j; l)表示第l级金字塔中的空间位置(i; j),我们希望构建一个重新采样函数
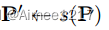 ,以重新排列
特征映射
以进行回归任务,使得
与分类特征更好地对齐。与[9]中的单尺度特征重新采样不同,我们将该过程扩展到多尺度特征空间,考虑到分类和回归的最佳特征可能在不同的尺度上[22]。
,以重新排列
特征映射
以进行回归任务,使得
与分类特征更好地对齐。与[9]中的单尺度特征重新采样不同,我们将该过程扩展到多尺度特征空间,考虑到分类和回归的最佳特征可能在不同的尺度上[22]。
我们的特征对齐是通过检测头中的子分支实现的,该子分支使用特征金字塔预测3D偏移量进行回归。如图2所示,我们在不同的FPN级别上添加了一个额外的CONV3×3(RELU(CONV1×1))层,并为每个预测估计一个偏移向量d =(d0; d1; d2)∈ R3。然后使用两个步骤中预测的偏移量重新排序P。

在公式(5)中,进行的是2D空间中的特征偏移,而公式(6)是跨不同尺度的偏移。在公式
(6)
中,
是在不同FPN级别上重新缩放的i和j的坐标。公式5通过双线性插值实现,公式6通过对
进行调整大小,
然后取
表示十进制数
,是
向下取整的
底函数。
值得注意的是,额外的CONV层会略微增加计算成本(约1%),但显着提高性能。
5.4
高斯混合模型的阈值分割
之前的研究[24,30]需要一个静态的超参数τ来进行伪边界框的过滤。然而,这种方法未考虑到模型对于不同类别和迭代中的预测置信度的变化,导致不一致的目标标
签,并对性能产生深远影响[4]。此外,在不同数据集上调整阈值是一项繁琐的任务。
我们的目标是找到一种自动区分正负伪边界框的方法。具体而言,我们假设对于类别 c的预测分数
来自一个具有两个模态(正和负)的高斯混合模型(GMM)分布
,该模型在所有未标记数据上进行采样。(请参见图2子图中的分数分布)
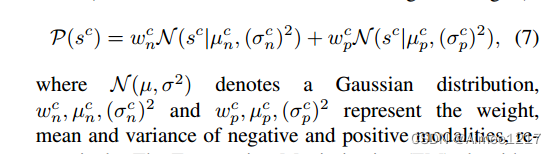
其中,N(µ; σ^2)表示高斯分布,分别表示负模态的权重、均值和方差,正模态的权重、均值和方差。然后使用期望最大化(EM)算法推断后验概率,它表示将检测设定为学生模型的伪目标的概率。最后,通过自适应的分数阈值确定:
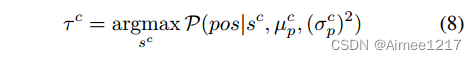
在实践中,我们为每个类别维护大小为N(N∼100)的预测队列以适应GMM。考虑到单级检测器的分数分布非常不平衡,因为大多数预测是负面的,因此只有前K = ∑k(sk)个预测结果存储在队列中。EM算法仅占约10%的训练时间增加。然后可以根据模型在不同训练阶段的性能自适应确定阈值。
六、分析
半监督目标检测的现状总结
半监督学习SSL是一种利用少量有标签数据和大量无标签数据进行训练以提高模型性能的机器学习方法。在图像分类、目标检测等领域,SSL 已经被广泛应用。在目标检测领域,半监督目标检测SSOD能够有效利用大量无标注数据进行训练,具有重要的应用价值。SSOD 的基本模式是Teacher-Student模式 [4][5][6][7]。该方法首先利用少量已标注数据对初始模型进行训练,同时使用教师模型对大量未标注数据进行推断,并将推断结果作为伪标签加入训练集。期望学生模型能够准确检测这些伪标签,并对增强后的输入样本做出一致的预测。首先介绍这篇论文的基线模型Mean-Teacher

如图所示,Mean-Teacher[1] 是一种半监督目标检测框架。它利用有标签数据和无标签数据进行训练,
其中Teacher模型生成伪标签,并给Student模型作为监督信号。
Teacher 模型的参数由是 Student 模型参数的指数滑动平均Exponential Moving Average得到。
相对应,Student 模型在进行过增强的未标注样本上进行训练,利用 Teacher 模型推断得到的伪标签进行监督。通过这种方式,Mean-teacher 实现多视图一致的自监督训练。
在 Mean-Teacher 的基础上,现有半监督目标检测方法通过各种方法提高伪标签的准确性,但由于缺乏足够的标注数据,训练过程中常常出现伪标签边界框质量较差的问题,这会导致模型的不稳定性和性能的下降。本文对伪标签质量较差的原因进行系统性的分析,发现关键问题在于伪标签的不稳定性与不一致性,从而给予 student 模型不稳定以及不一致的伪监督信号。
伪标签的不稳定性:SSOD
在半监督目标检测中,生成的伪标签存在不稳定(Inconsistency)的问题,这不仅影响伪标签的准确性,也会导致模型训练的不稳定和性能下降。主流的半监督目标检测器生成伪标签时是基于当前时刻的Teacher模型的预测。与全监督训练时的静态标签(在训练过程中不会变化)不同,一个无标签图像中一个物体的伪标签可能在训练过程中某个时间点出现,不断变化,直至最后稳定或消失。在使用这种极不稳定的伪标签监督下进行训练会导致一系列问题,如模型性能下降,难以达到理想效果等。本文列举了三种不稳定性产生的原因如下:

分配不一致: 当前主流的两阶段(Two-stage)或者单阶段(Single-stage)目标检测网络都使用基于IoU阈值的静态anchor分配方法,这种方法对于伪标签框中的噪声非常敏感。即使伪标签框中只有微小的噪声,伪标签的不稳定性也会导致anchor分配的不同。
本文通过下图来说明在Mean-Teacher框架下RetinaNet[2]检测器中,伪标签不稳定性会导致的问题。绿色和红色的边界框是北极熊的实际边界框和伪边界框。红点是伪标签的锚定框。热图显示了教师模型预测的密集置信度得分。在Mean-Teacher中,由于Teacher生成伪标签的不稳定性,在利用伪标签对Student进行伪监督训练时,Student会不时的将anchor assign到旁边的木板上。由于这种不一致的标签,Student模型最终会过拟合噪声并导致附近的木板被检测到并错误地分类为北极熊。

本文同时展示了一个 anchor box 在训练过程中动态变化的动图。如下图1为 Mean-Teacher,使用基于 IOU 阈值的静态 anchor 分配方法,可以看到随着训练进行,由于 Teacher 生成伪标签的不稳定性,在利用伪标签对 Student 进行伪监督训练时,Student 会不时的将 anchor assign 到旁边的木板上。而本文提出的 Consistent-Teacher,如下图2则可以稳定持续的定位到正确的前景物体并分配正确的分配 anchor。

这种对噪声的过拟合同样可以在分类损失图中看到,不一致的伪目标会导致分类分支过拟合,而回归损失则难以收敛(如下图)。

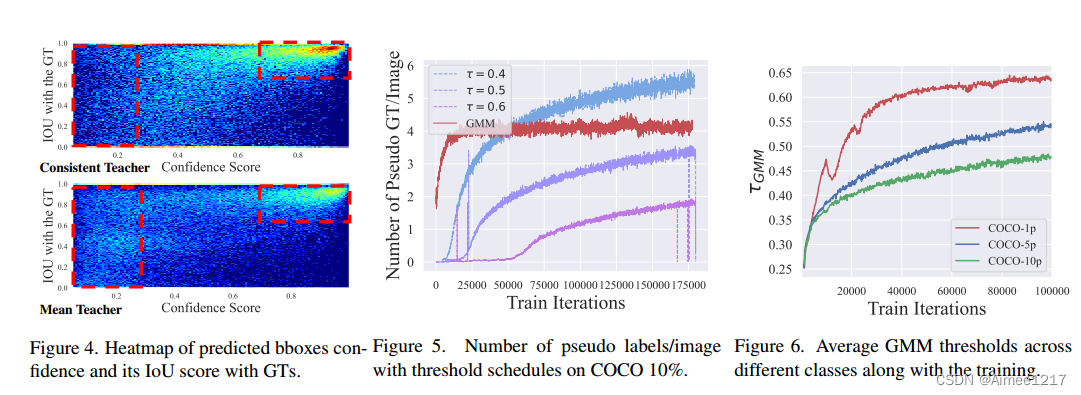
任务不一致:在主流的半监督目标检测方法中,分类与回归任务的不一致也是导致不稳定性的一个重要原因。为了筛选高质量的伪标签,通常会使用分类置信度作为指标,并设置阈值来筛除低置信度的伪标签框。然而,一个伪标签框的分类置信度好坏并不一定能反映其定位准确度的高低。因此,利用分类置信度进行伪标签筛选的方法会进一步加剧伪标签在训练过程中的不稳定性。如下图(4)所示,可以看到Mean-Teacher中存在大量分类置信度高但是回归不准确(与GT的IOU较低)的定位框。

时序不一致: 固定阈值筛选伪标签的方法同样会导致不一致性。在半监督目标检测中,为了筛选高质量的伪标签进行训练,常常采用一个固定的阈值对分类的置信度进行筛选。然而,这种方法会导致在训练不同阶段的不一致性。在训练初期,由于模型对预测结果不够自信,固定的阈值会导致过少的伪标签框被筛选,而随着模型的不断训练,每张图的伪标签框数量会逐渐增多,直到训练后期过多。这种伪标签框数量的不一致同样会导致 Student 网络训练的不一致。如上图(5)可以看到,不同 threshold 的 Mean-Teacher 均会出现“伪标签框数量随着训练逐渐增多”的不一致现象。
Consistent Teacher
在分析现有半监督目标检测伪标签的偏移问题与不稳定性后,本文提出了一种新的半监督目标检测方法 Consistent-Teacher,整体如下图。Consistent-Teacher 设计了三种模块来解决上述问题,包括自适应的标签分配(ASA),3D特征对齐(FAM-3D)和基于高斯混合模型的自适应阈值(GMM-based Threshold)
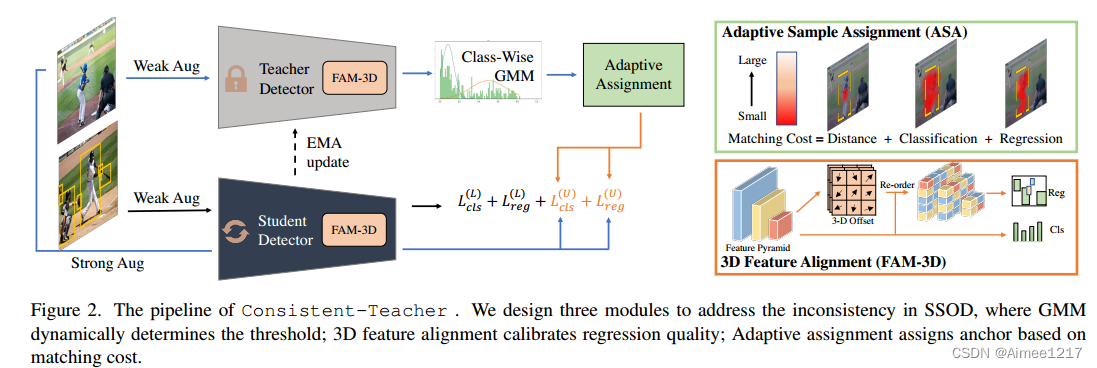
整体想法:Consistent-Teacher 包含一个Teacher模型和一个Student模型,其中教师模型的参数是学生模型参数的指数滑动平均(EMA)。在训练的每一个iteration,学生模型一方面在有标签数据上进行有监督训练;另一方面,教师模型对无标签数据进行标注,得到伪标签框,并在对无标签数据进行了强数据增强后,训练学生模型。
1、在这个教师-学生模型的基础上,本文提出三种模块来解决上述伪标签不一致问题。上文提到静态anchor分配由于使用IoU阈值分割来分配anchor,略微变化就会导致分配的不同。本文则提出采用自适应的标签分配 (ASA),与静态anchor分配不同,ASA为每一对anchor-真实值边界框计算一个匹配损失,然后选择匹配损失最小的若干对anchor-真实值边界框作为最终的anchor分配。
2、其次,为了解决上文提到的分类与回归任务之间存在的不一致问题,本文提出3D特征对齐模块 (FAM-3D),通过使分类特征自适应地检索到最佳回归特征,以执行回归任务。以此,FAM-3D成功地将分类和回归特征进行了对齐。具体而言,FAM-3D在检测头中额外增加一个分支,用于预测最优回归特征位置的偏移量。FAM-3D中的“3D”意味着这个位置偏移量不仅在x和y维度上预测回归特征的偏移量,同时还预测特征金字塔中进行跨层的偏移量预测。我们使用计算出偏移量对分类特征进行重拍,即可得到与分类特征对齐的最优回归特征。这个偏移量是通过端到端优化回归特征位置头获得的,而不需要手工标注的监督。最后模型利用分类特征进行分类,并利用对齐的回归特征回归检测框。
3、最后,为了解决硬阈值选择伪标签带来的不一致问题,本文提出使用动态的阈值。它随着训练过程中的模型能力变化,调整伪标签的阈值。为了动态的调整伪标签框筛选的阈值,Consistent-Teacher将伪标签框筛选的过程看作是一个二分类过程,即正样本类为筛选得到的高质量伪标签框,负样本类为要筛除的低质量标签框。本文采用高斯混合模型(GMM)对这个二分类进行建模。将正样本类别和负样本类别分别看作两个高斯分布,通过Expectation-Maximum(EM)算法迭代求解高斯混合模型的最优参数,通过高斯混合模型得到分类阈值(区分正样本和负样本)。在训练中,Consistent-Teacher维持一个class-wise的队列存储用于建模GMM的的样本,并在训练过程中不断通过GMM获得动态更新的阈值进行自适应的筛选样本。
验证SSOD的不一致性
首先本文画出了伪标签的准确性,以及伪标签一致性随着训练不断进行的变化图。本文通过伪标签与真实标签的mAP来衡量伪标签的准确性,并通过两个连续的checkpoint对同一个样本预测的一致性作为伪标签的一致性衡量标准。 如下图可以看到,Mean-Teacher的伪标签不一致性远高于 Consistent-Teacher ;随着训练进行不断增加,Mean-Teacher的伪标签的mAP也远低于Consistent-Teacher。

下左图和中间的图可以看到,随着训练的进行,Mean-Teacher的伪标签框数量逐渐增多,会导致训练的不一致性。而本文提出的Consistent-Teacher通过GMM动态的调整并缓慢提高阈值,可以维持不同训练阶段中,伪标签框数量相对稳定。














 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









