








目录
简介
题目:《Consistent-Teacher: Towards Reducing Inconsistent Pseudo-targets in Semi-supervised Object Detection》, CVPR’23(Highlight),《一致性教师:减少半监督目标检测中不一致的伪目标》
日期: 2023.3.28(v3),v1:2022.9.4
单位: 商汤、上海AI实验室、新加坡国立大学、北京大学
论文地址: http://arxiv.org/abs/2209.01589
GitHub: https://github.com/Adamdad/ConsistentTeacher
作者

研究方向主要是模型架构研究、半监督学习、目标检测
共同一作

个人主页:https://adamdad.github.io/

其他作者




- 摘要
在本研究中,我们深入研究了半监督目标检测(SSOD)中伪目标的不一致性。我们的核心观察结果是,振荡的伪目标破坏了精确探测器的训练。它给学生的训练注入了噪音,导致了严重的过拟合问题。因此,我们提出了一个系统的解决方案,称为Consistent Teacher,以减少不一致性。首先,自适应锚分配(ASA) 取代了基于静态IoU的策略,使学生网络能够抵抗噪声伪边界盒。然后,我们通过设计三维特征对齐模块(FAM-3D) 来校准子任务预测。它允许每个分类特征在任意尺度和位置自适应地查询回归任务的最优特征向量。最后,高斯混合模型(GMM) 动态修正了伪框的得分阈值,在早期阶段稳定了GT的数量,并弥补了训练过程中不可靠的监督信号。Consistent Teacher在SSOD的大量评估中提供了强有力的结果。它在ResNet-50主干上实现了40.0mAP,只给出了10%的注释MS-COCO数据,这比以前使用伪标签的基线高出了约3mAP。当在带有附加未标记数据的完全注释MS-COCO上训练时,性能进一步提高到47.7mAP。
本文通过分析现有半监督目标检测(SSOD)伪标签的偏移问题与不稳定性(Inconsistancy),提出了一种新的半监督目标检测器Consistent-Teacher。本文被CVPR2023评为Highlight(占提交总数的2.5%)。
-
什么是伪标签的不稳定性?
在半监督目标检测中,生成的伪标签存在不稳定(Inconsistency)的问题。主流的半监督目标检测器生成伪标签时是基于当前时刻的Teacher模型的预测。与全监督训练时的静态标签(在训练过程中不会变化)不同,一个无标签图像中一个物体的伪标签可能在训练过程中某个时间点出现,不断变化,直至最后稳定或消失。在使用不稳定的伪标签监督下进行训练会导致一系列问题,学生网络的优化目标不一致,会导致模型训练的不稳定和性能下降,以及模型收敛速度的下降。

-
提出了3种不稳定性(设计inconsistency问题)并分析原因:

- Assignment inconsistency:分配不一致。
当前主流的两阶段(Two-stage)或者单阶段(Single-stage)目标检测网络都使用基于IoU阈值的静态anchor分配方法,这种方法对于伪标签框中的噪声非常敏感。即使伪标签框中只有微小的噪声,伪标签的不稳定性也会导致anchor分配的不同。 - Subtasks inconsistency:下游任务的不一致性,即分类Cls-回归Reg任务的不一致性。
在主流的半监督目标检测方法中,分类与回归任务的不一致也是导致不稳定性的一个重要原因。为了筛选高质量的伪标签,通常会使用分类置信度作为指标,并设置阈值来筛除低置信度的伪标签框。然而,一个伪标签框的分类置信度好坏并不一定能反映其定位准确度的高低。因此,利用分类置信度进行伪标签筛选的方法会进一步加剧伪标签在训练过程中的不稳定性。 - Temporal inconsistency:时序不一致。
固定阈值筛选伪标签的方法同样会导致不一致性。在半监督目标检测中,为了筛选高质量的伪标签进行训练,常常采用一个固定的阈值对分类的置信度进行筛选。然而,这种方法会导致在训练不同阶段的不一致性。在训练初期,由于模型对预测结果不够自信,固定的阈值会导致过少的伪标签框被筛选,而随着模型的不断训练,每张图的伪标签框数量会逐渐增多,直到训练后期过多。这种伪标签框数量的不一致同样会导致 Student 网络训练的不一致。
- Assignment inconsistency:分配不一致。
-
Consistent Teacher很大程度上,改善了生成伪标签的不一致性
左图:比较“Mean Teacher”和“Consistent Teacher”的训练损失。不一致的伪目标会导致分类分支过拟合,而回归损失则难以收敛(如下图)。
SSOD中关于COCO 10%评估的不一致性问题的说明。(左)我们比较“Mean Teacher”和“Consistent Teacher”的训练损失。在Mean Teacher中,不一致的伪目标导致分类分支上的过拟合,而回归损失变得难以收敛。相反,我们的方法为学生设定了一致的优化目标,有效地平衡了这两项任务并防止了过度拟合。
(右)伪标签和分配动态的图片集。绿色和红色的box分别指的是北极熊的ground truth和伪标签。红点是为伪标签指定的定位框。热图表示老师预测的密集置信度分数(越大越亮)。附近的一块木板最终在基线中被错误地归类为北极熊,而我们的自适应分配防止了过度拟合。

Mean-Teacher的伪标签不一致性远高于 Consistent-Teacher ;随着训练进行不断增加,Mean-Teacher的伪标签的mAP也远低于Consistent-Teacher。
Consistent-Teacher提高了SSOD中训练的一致性。(左轴)不同时间未标记集合上的mAP。(右轴)伪标签的不一致性。

Mean-Teacher预测了很多分类置信度高但是定位不准确的伪标签框(左边红色框)。而本文提出的Consistent-Teacher预测的大多数是分类置信读高且定位准确的伪标签框,这说明本文提出的方法可以很好的对齐分类与回归的特征并且预测更为准确的伪标签框
预测的bboxes置信热力图及其与GTs的IoU得分。

在静态置信阈值τ=0.4、0.5、0.6的情况下,随着训练的进行,Mean-Teacher的伪标签的数量随着检测器变得更加自信而不断增加。而本文提出的Consistent-Teacher基于GMM的方法根据模型容量自适应地调整最佳阈值,具有几乎恒定数量的GT,这减少了时间不一致性,可以维持不同训练阶段中,伪标签框数量相对稳定。
COCO上具有阈值时间表的伪标签/图像数量10%

在图6中,我们绘制了GMM在COCO 1%/5%/10%上获得的估计阈值曲线。随着训练的进行,有效值稳步增加。此外,在标记样本较少的情况下,GMM根据更多的过拟合问题设置更高的置信阈值。典型的静态阈值设置无法解决学习目标的不一致性,而GMM提供了一个令人满意的解决方案。
不同类别的均GMM阈值以及训练。

工作重点
- 首次对SSOD中的不一致目标问题进行了深入调查,该问题会导致严重的过拟合问题。
- 引入了一种自适应样本分配(ASA),以稳定噪声伪框和锚点之间的匹配,从而为学生模型提供稳健的训练。
- 我们开发了一个三维特征对齐模块(FAM-3D)来校准分类置信度和回归质量,从而提高了伪框的质量。
- 我们采用GMM来灵活地确定训练中每个类的阈值。自适应阈值随着时间的推移而变化,并减少了SSOD的阈值不一致性。
- Consistent Teacher在广泛的评估中取得了令人信服的进步,并成为SSOD的新的坚实基线。
方法
在分析现有半监督目标检测伪标签的偏移问题与不稳定性后,本文提出了一种新的半监督目标检测方法 Consistent-Teacher,整体如下图。Consistent-Teacher 设计了三种模块来解决上述问题,包括自适应的标签分配(ASA),3D特征对齐(FAM-3D)和基于高斯混合模型的自适应阈值(GMM-based Threshold)
Consistent-Teacher框架:我们设计了三个模块来解决SSOD中的不一致性,其中GMM动态地确定阈值;3D特征对齐校准回归质量;基于匹配成本的自适应标签分配。

- 总体Loss

ft(·; θt):教师检测器、fs(·; θs):学生检测器
N个样本的标记集,M个样本的未标记集
T:teacher网络的weak数据增强;T’:student的strong 数据增强
y:表示gt;^y:教师模型生成的伪标记,
所有模型的Lcls和Lreg均设置了焦点损失和GIoU损失
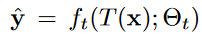
上文提到静态anchor分配由于使用IoU阈值分割来分配anchor,略微变化就会导致分配的不同。
而且由于类别和伪框有时是冲突的,不能直接用类别分数过滤。故提出:将伪框分配给锚点,最小化他们的loss。
本文则提出采用自适应的标签分配 (ASA),与静态anchor分配不同,ASA为每一对anchor-真实值边界框计算一个匹配损失,然后选择匹配损失最小的若干对anchor-真实值边界框作为最终的anchor分配。(计算每个预测与给定的GT(也包括伪bbox)之间的匹配代价,并根据相对匹配代价执行分配。)
RetinaNet中的每个锚只有在其具有ground truth(GT)的IoU bbox大于阈值时才被分配为正。这种静态标签分配打破了半监督学习中的一个重要特性。以分类为例,实例级伪标签满足
这意味着伪标签^c应该与其自己的预测对齐。然而,当SSOD采用静态锚点分配时,这一规则被打破了。也就是说,为锚分配的标签有时与他们自己的预测相矛盾,这是图中伪标签漂移现象的根源。1。因此,我们建议为锚分配伪bbox,以最大限度地减少其损失

将伪框分配给锚点,最小化他们的loss,公式如下,其中n代表anchor index。

n:锚索引
an∈{1,2,···,L+1}:L个预测的bbox中指定的伪bbox索引,索引L+1表示背景标签。
Cdist代表锚点和伪box中心的距离,每个伪box选取k个最小cost的作为正样本。
计算每个锚点与伪bbox之间的匹配成本,认为成本最低的为正样本。计算公式如下:其中Cdist代表锚点和伪box中心的距离。每个伪box选取k个最小cost的作为正样本

λreg和λdist是加权参数
Cdist计算锚点n的中心和伪bbox yl之间的距离,用作具有小权重值(λdist~0.001)的中心先验,以稳定训练。
对于每个伪bbox的匹配成本,具有最高K个最低成本的锚被分配为正。由于分配是根据模型的检测质量进行的,因此伪框中的噪声对特征点分配的影响可以忽略不计。
Consistent-Teacher的检测头结构。左侧为头部结构,右侧为3D FAM模块

其次,为了解决上文提到的分类与回归任务之间存在的不一致问题,本文提出3D特征对齐模块 (FAM-3D),通过使分类特征自适应地检索到最佳回归特征,以执行回归任务。以此,FAM-3D成功地将分类和回归特征进行了对齐,即用分类置信度校准bbox定位
具体而言,FAM-3D在检测头中额外增加一个分支,用于预测最优回归特征位置的偏移量。FAM-3D中的“3D”意味着这个位置偏移量不仅在x和y维度上预测回归特征的偏移量,同时还预测特征金字塔中进行跨层的偏移量预测。
在不同的FPN水平上添加了一个额外的CONV3×3(RELU(CONV1×1))层,并为每个预测估计偏移向量d=(d0,d1,d2)∈R3。然后使用预测的偏移分两步对P进行重新排序

P:特征金字塔;P(i,j,l):第l个金字塔级别的空间位置(i,j)
P’<–S( P ):重新采样函数,重新排列特征图以进行回归任务,使P′更好地与分类特征对齐。
其中方程5是在2-D空间中进行特征偏移,而方程6是不同尺度上的偏移。在等式6中,i′和j′是i和j在不同FPN水平上的重新缩放坐标。等式5是通过双线性插值实现的,等式6是通过调整P′(:,:,l+[d2]+1)的大小,然后对十进制数d2使用P′(:,:,l+[d2])进行加权平均来实现的,其中[·]是底函数。训练成本增加了1%左右,mAP提升了0.6个点。
两种高斯混合的分数分布和拟合结果。正、负分布分别用橙色和蓝色线条表示。蓝色虚线表示最终阈值。
最后,为了解决硬阈值选择伪标签带来的不一致问题,本文提出使用动态的阈值。它随着训练过程中的模型能力变化,调整伪标签的阈值。为了动态的调整伪标签框筛选的阈值,Consistent-Teacher将伪标签框筛选的过程看作是一个二分类过程,即正样本类为筛选得到的高质量伪标签框,负样本类为要筛除的低质量标签框。本文采用高斯混合模型(GMM)对这个二分类进行建模。将正样本类别和负样本类别分别看作两个高斯分布,通过Expectation-Maximum(EM)算法迭代求解高斯混合模型的最优参数,通过高斯混合模型得到分类阈值(区分正样本和负样本)。在训练中,Consistent-Teacher维持一个class-wise的队列存储用于建模GMM的的样本,并在训练过程中不断通过GMM获得动态更新的阈值进行自适应的筛选样本。
假设类别c的得分预测sc 是从具有正和负两种模式的所有未标记数据上的高斯混合(GMM)分布P(sc) 中采样的,假设类别分别服从高斯分布,将所有unlabeled data分成2类,正样本§的分布,负样本(n)的分布,w代表权重。

N(μ,σ2):高斯分布
wcn,μcn,(σcn)2和wcp,μcp,(σcp)2分别表示负模态和正模态的权重、均值和方差
最大化正样本的分布。使用期望最大化(EM)算法来推断后验P(pos|sc,μcp,(σcP)2),这是检测应该被设置为学生的伪目标的概率,并且自适应得分阈值被确定为

在实践中,我们为每个类维护一个大小为N(N~100)的预测队列,以适应GMM。考虑到单级检测器的分数分布是强不平衡的,因为大多数预测都是负的,所以只有前K=∑K(sk)个预测存储在队列中。EM算法只占训练时间增加的约10%。然后可以根据模型在不同训练阶段的性能自适应地确定阈值。
实施细节
所有检测器都在8个GPU上进行训练,每个GPU有5个图像(1个标记图像和4个未标记图像),类似于soft teacher。检测器使用SGD进行优化,恒定学习率为0.01,动量为0.9,重量衰减为0.0001。未标记的数据权重为λU=2。没有应用学习率衰减。在COCO-PARTIAL和VOC-PARTIAL评估中,我们对检测器进行180K迭代的训练,而为了更好地收敛,我们将COCO-ADDITION的训练时间增加到720K。教师模型通过EMA更新,动量为0.9995。我们遵循soft teacher中相同的数据预处理和扩充管道。我们采用了以ResNet-50主干为基线的RetinaNet。ImageNet预训练的模型被用作初始化。
我们将我们的一致性教师与许多主流的SSOD方法进行了比较,包括CSD, STAC, Instant Teaching, Humble Teacher, Unbiased Teacher v1 and v2, Soft Teacher, ACRST, DSL, S4OD, Dense Teacher,PseCo。
此外,实现了一种基线方法,使用标记和伪标记数据对学生进行训练,并通过学生的移动平均值更新教师。我们将其命名为Mean-Teacher基线。默认置信度阈值设置为0.4。
实验
与SOTA的比较
本文在MS-COCO 2017以及PASCAL VOC数据集上进行实验。 在MS-COCO 2017不同比例的有标签的数据上,Consistent-Teacher均获得了远超SOTA的结果。如下图可见,Consistent-Teacher在1%,2%,5%以及10%的比例(有标注数据的比例)上分别获得了25.30, 30.40, 36.10以及40.00的mAP,这个结果稳定地比之前的SOTA Dense Teacher高出3个mAP。
COCO-PAPARTIAL与val2017上其他半监督检测器的比较。分别列出了两级(上半部分)和单级(下半部分)探测器的结果。我们还报告了仅在标记数据上训练的Faster RCNN和RetinaNet性能。所有型号均采用以FPN为骨干的ResNet50。我们用下划线突出显示之前的最佳记录。

在COCO-Addition(利用全部的MS-COCO 2017作为有标注数据,并使用额外的COCO未标注数据)上本文同样获得了惊人的效果。如下图Table2,可以看到Consistent-Teacher获得了47.70的超强performance,比SOTA高1个mAP。在VOC的实验上本文提出的Consistent-Teacher同样获得了SOTA的结果。
以unbel2017为未标记集的val2017的COCO-ADDION实验结果。注意,1×表示90K训练迭代,N×表示N×90K迭代。

在VOC07标记和VOC12未标记的集合上与其他半监督检测器的VOC-PARTIAL实验结果比较。

消融实验
本文进一步进行消融实验说明本文提出的三个模块的有效性。
如表4所示,稳健的样本分配在SSOD中发挥着关键作用。通过专门化半监督任务的分配策略,我们的ASA在COCO上实现了38.50mAP 10%,与使用IoU的启发式匹配成本相比,提高了3mAP。另一个发现是,在SSOD(3.0mAP)上,ASA的性能效益几乎是在完全监督设置(1.7mAP)下的两倍。
基于IoU和我们在COCO上的自适应锚分配之间的比较。

在Figure 7和8中,通过在不同比例的有标签数据上进行训练,以及对比不同固定阈值的模型可以看到GMM可以带来稳定的0.5个点的提升。
Table 5中可以看到FAM-2D可以带来0.6的提升,而FAM-3D可以进一步带来0.4个点的提升。
基于GMM的伪标记滤波的消融研究。每个值表示COCO 10%数据上的mAP得分。

在COCO上以不同数据比率消融GMM。将模型与硬阈值为0.4的基线进行比较。

探测头结构的消融实验。我们比较了COCO 10%和标准1×评估的不同头部结构的性能、模型尺寸和FLOP。FLOP是在1280×800的输入图像大小上测量的。

总结
- conclusion
本文对SSOD中出现的不一致性问题进行了系统的研究,并提出了一种简单有效的半监督对象检测器,称为“一致教师”作为解决方案。所提出的方法采用自适应锚点分配和FAM,前者识别具有最低匹配成本的正锚点,后者通过回归三维特征金字塔偏移来对齐分类和回归任务。为了解决伪框中的阈值不一致问题,利用GMM动态调整阈值进行自训练。通过集成这三个模块,我们的一致教师在各种SSOD基准测试上实现了比最先进方法的显著性能改进,展示了稳健的锚分配和一致的伪框。
-
supplementary material
在这篇补充材料中,我们提供了更多的实验定量结果、模型大小的比较和边界框的可视化,所有这些都有助于增强我们提出的一致教师的有效性。此外,我们还提供了关于我们的实验方法、实现信息和超参数设置的更多细节。我们的代码也附在附件中供您参考。
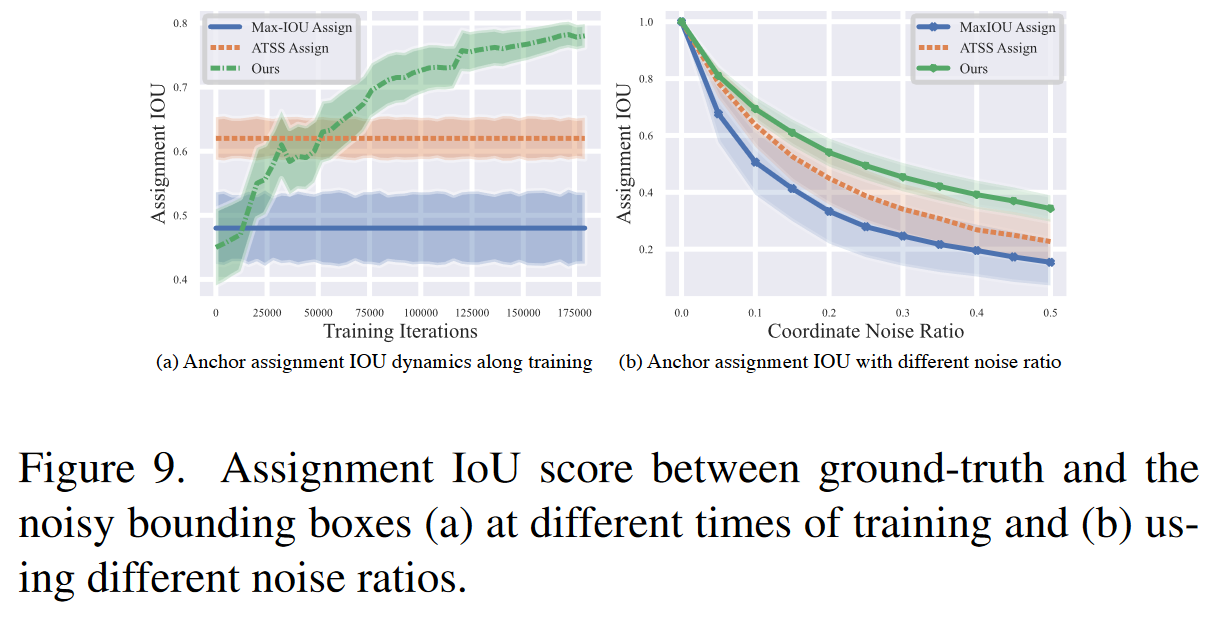
(a)在不同的训练时间和(b)使用不同的噪声比,在ft和噪声边界框之间分配IoU分数。
使用IOU置信度线性回归(LR)误差进行分类和回归不一致性分析。提供了平均教师IoU置信图。

基于锚和无锚检测器的SSOD性能。

λdist的消融实验
用不同的方法每秒训练时间。ASA不仅提高了性能,还降低了任务期间的时间复杂性,这主要是因为它的实现更高效,对锚点数量的要求更少。FAM3D引入了训练时间的边际增加,表明在性能增强和计算效率之间存在合理的平衡。在基于GMM的阈值化的情况下,每次迭代更新阈值会导致训练时间增加约10%,这表明GMM可以提供某些优势,但代价是延长训练持续时间。
COCO%10评估的定性比较。橙色中的边界框是基本事实,而紫色指的是预测。红色突出显示误报预测。

COCO%10评估的良好检测结果。橙色中的边界框是基本事实,而紫色指的是预测。

用于标记图像训练的数据扩充。

未标记图像的弱数据增强。

COCO%10评估的故障检测结果。橙色中的边界框是基本事实,而紫色指的是预测。

针对未标记图像的强数据增强。

外观变换,称为TransAppearance。

几何变换,称为TransGeo。














 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









