







VS IDE 中Visual C++ 中的项目属性配置
一、 Visual C++ 项目系统基于 MSBuild。 虽然可以直接在命令行上编辑 XML 项目文件和属性表,我们仍建议你使用 VS IDE,在你修改参与继承的属性时,这一点尤为重要。 Visual C++ 项目系统不一定可以识别在 MSBuild 中有效的手动编辑文件,在生成过程中可能产生细微错误。
项目文件是文件扩展名为 .vcxproj 的 XML 文件。
所有在 IDE 中设置的属性直接写入项目文件或生成时导入的属性表中。
VC++ 目录是配置属性,对应不同配置,其值可以不同,例如 Debug 对应 Release。 你可以使用对话框顶部的“配置”和“平台”列表框设置适用于属性的配置;在许多情况下,“所有平台”和“所有配置”就是合适的选择。 “通用属性”规则中的设置适用于所有配置。
当修改后,选择“确定”按钮后,新值就会写入项目文件。
参考:https://msdn.microsoft.com/zh-cn/library/669zx6zc(v=vs.120).aspx
注意:
1. “属性页”对话框仅显示适用于当前项目的属性页。 例如,如果该项目没有 .idl 文件则不会显示 MIDL 属性页。
二、“属性页”对话框中属性的详细信息
1. “常规”选项页(项目)

常规
“常规”区域中的属性影响生成过程中创建的文件位置和当选择“清除”选项(“生成”菜单)时删除的文件。

(1)输出目录:
指定链接器等工具用来放置生成过程中创建的所有最终输出文件的目录。
这通常包括链接器、管理员或 BSCMake 这类工具的输出。
对应属性$(OutDir) , 即 OutputDirectory。
(2)中间目录
指定编译器等工具用来放置生成过程中创建的所有中间文件的目录。
这通常包括 C/C++ 编译器、MIDL 和资源编译器这类工具的输出。
对应属性$(IntDir) ,即: IntermediateDirectory。
(3)Target Name
此项目生成的文件名
(4)目标扩展名
此项目生成的文件扩展名;例如,.exe 或 .dll
(5)清除时要删除的扩展名
“清除”选项(“生成”菜单)从生成项目配置的中间目录中删除文件。
当运行“清除”或执行重新生成时,具有用此属性指定的扩展名的文件将被删除。
除了中间目录中具有这些扩展名的文件外,生成系统还删除生成的所有已知输出(包括 .obj 文件这样的中间输出),与它的位置无关。
注意可以指定通配符。
(6)生成日志文件
每次生成项目时创建的日志文件指定非默认位置
默认: $(IntDir)$(MSBuildProjectName).log, 即“中间目录”/ 项目名称.log 文件。
(7)平台工具集:
允许项目以 Visual C++ 库和编译器的不同版本为目标。
Visual C++ 项目既可以以 Visual Studio 2012 (v100) 中的默认工具集为目标,也可以以创建运行在Windows XP上的可执行程序的工具集为目标。

项目默认值
“项目默认值”区域表示可以修改的默认属性。
这些属性的定义可以在 Installation Directory\VC\VCProjectDefaults 中的 .props 文件中找到。
(1)配置类型
-
“应用程序 (.exe)”,显示链接器工具集,该工具集中包括:C/C++ 编译器、MIDL、资源编译器、链接器、BSCMake、XML Web services 代理生成器、自定义生成、预生成、预链接、生成后事件等。
-
“动态库 (.dll)”,显示链接器工具集,指定 /DLL 链接器选项并将 _WINDLL 定义添加到 CL。
-
“Makefile”(生成文件),显示生成文件工具集 (NMake)。
-
静态库 (.lib),显示管理员工具集(除了用管理员代替链接器和省略 XML Web services 代理生成器外,与链接器工具集相同)。
-
“Utility”实用工具,显示实用工具工具集(MIDL、自定义生成、预生成、生成后事件)。
(2)MFC 的使用
指定 MFC 项目是否将静态或动态链接到 MFC DLL。
非 MFC 项目可以选择“使用标准 Windows 库”链接到使用 MFC 时包括的各种 Win32 库。
(3)字符集
定义是否应该设置 _UNICODE 或 _MBCS。 在适当的地方还影响链接器入口点。
注意: 默认示 Unicode字符集 配置, 如果选择使用 多字节字符集,则不需要配置Qt的字符选项。

(1)关于“多字节字符集”和“Unicode字符集”的说明:
字符集是一种“字符符号”的集合,同时代表一种编码形式。但是相同类的字符集有多种“编码形式”。
早期的VC IDE采用多字节字符集作为默认的设置。由于编译的软件适应国际化的需求,因此现在的VS IDE 默认采用 Unicode 字符集。
因此,一般推荐使用Unicode的方式,因为它可以适应各个国家语言,在进行软件国际时将会非常便得。
(2)关于“多字节字符集”的优点:
(1)适配早期的C++代码,在VS上编译
(2)除非在对存储要求非常高的时候,或要兼容C的代码时,我们才会使用多字节的方式 。(3)关于Unicode 字符集的优点:
(1)可以很容易地在不同语言之间进行数据交换,适合系统进行“国际化”处理。
(2)提高应用程序的运行效率。
Windows NT是使用Unicode进行开发的,整个系统都是基于Unicode的。(对Multi byte chase Set 多字节版本的API的值对Unicode的封装,因此,其中添加了转换的处理,
因此速度比 Unicode版本的调用慢)
如果调用一个API函数并给它传递一个ANSI(ASCII字符集以及由此派生并兼容的字符集,如:GB2312,通常称为ANSI字符集)字符串,那么系统首先要将字符串转换成Unicode,然后将Unicode字符串传递给操作系统。
如果希望函数返回ANSI字符串,系统就会首先将Unicode字符串转换成ANSI字符串,然后将结果返回给您的应用程序。进行这些字符串的转换需要占用系统的时间和内存。如果用Unicode来开发应用程序,就能够使您的应用程序更加有效地运行。(4)字符集的历史:
参考博客:http://blog.csdn.net/stephen1315/article/details/7476236
最初的时候,Internet 上只有一种字符集——ANSI的ASCII字符集,它使用7 bits来表示一个字符,总共表示128个字符,其中包括了英文字母、数字、标点符号等常用字符。之后,又进行扩展,使用8 bits表示一个字符,可以表示256个字符,主要在原来的7 bits字符集的基础上加入了一些特殊符号例如制表符。
由于各国语言的加入,ASCII已经不能满足信息交流的需要。为了能够表示其它国家的文字,各国在ASCII的基础上制定了自己的字符集,这些从ANSI标准派生的字符集被习惯的统称为ANSI字符集,它们正式的名称应该是MBCS(Multi-Byte Chactacter System,即多字节字符系统)。派生字符集的特点是以ASCII 127 bits为基础,兼容ASCII 127,他们使用大于128的编码作为一个Leading Byte,紧跟在Leading Byte后的第二(甚至第三)个字符与Leading Byte一起作为实际的编码。这样的字符集有很多,我们常见的GB-2312就是其中之一。
例如在GB-2312字符集中,“连通”的编码为C1 AC CD A8,其中C1和CD就是Leading Byte。前127个编码为标准ASCII保留,例如“0”的编码是30H(30H表示十六进制的30)。软件在读取时,如果看到30H,知道它小于128就是标准ASCII,表示“0”,看到C1大于128就知道它后面有一个另外的编码,因此C1 AC一同构成一个整个的编码,在GB-2312字符集中表示“连”。
因此,基于 ANSI 编码扩展而来的 “字符集”,统称为“多字节字符集”!。 问题:由于ANSI 编码扩展而来的字符集的编码规范各不相同,导致最后存在的各种字符集实在太多,在国际交流中要经常转换字符集非常不便,甚至是编码字符存在冲突。
为了解决“多字节字符集”的问题,提出了Unicode字符集,它固定使用16 bits(两个字节、一个字)来表示一个字符,共可以表示65536个字符。将世界上几乎所有语言的常用字符收录其中,方便了信息交流。标准的Unicode称为UTF-16。后来为了双字节的Unicode能够在现存的处理单字节的系统上正确传输,出现了UTF-8。使用类似多字节字符集编码MBCS的方式对Unicode进行编码。注意UTF-8是编码,它属于Unicode字符集。
Unicode的最初目标,是用1个16位的编码来为超过65000字符提供映射。但这还不够,它不能覆盖全部历史上的文字,也不能解决传输的问题 (implantation head-ache's),尤其在那些基于网络的应用中。已有的软件必须做大量的工作来程序16位的数据。因此,Unicode用一些基本的保留字符制定了三套编码方式。它们分别是UTF-8,UTF-16和UTF-32。正如名字所示,在UTF-8中,字符是以8位序列来编码的,用一个或几个字节来表示一个字符。这种方式的最大好处,是UTF-8保留了ASCII字符的编码做为它的一部分,例如,在UTF-8和ASCII中,“A”的编码都是0x41. UTF-16和UTF-32分别是Unicode的16位和32位编码方式。考虑到最初的目的,通常说的Unicode就是指UTF-16。
例如“连通”两个字的Unicode标准编码UTF-16 (big endian)为:DE 8F 1A 90 而其UTF-8编码为:E8 BF 9E E9 80 9A
因此, “Unicode 字符集”存在多种编码形式,优点:利于国际化,且由于WinNT操作系统底层都采用Unicode字符编码,因此,Exe应用采用Unicode编码,可以加快消息相应,减少内存使用优点。
字符集与字符编码的系谱图, 从图中看出, Unicode字符集包含了:UTF-8, UTF-16, UTF-32等编码; 而ANSI(多字节字符集)有GBK编码, ISO8895-1等编码;
(5)C++基本数据类型中表示字符的有两种:char、wchar_t区别:
char叫多字节字符(多字节字符集),一个char占一个字节,之所以叫多字节字符是因为它表示一个字时可能是一个字节也可能是多个字节。一个英文字符(如’s’)用一个char(一个字节)表示,一个中文汉字(如’中’)用3个char(三个字节)表示,看下面的例子。
wchar_t被称为宽字符(是采用Unicode字符集),一个wchar_t占2个字节。之所以叫宽字符是因为所有的字都要用两个字节(即一个wchar_t)来表示,不管是英文还是中文。看下面的例子:
用法:
多字节字符(char)串常量时用一般的双引号括起来就可以了。
宽字节字符(wchar_t)串常量时要在引号前加L,如L”String test”
注意:
 理解_T()、_Text()宏即L”“ 因为:查看tchar.h头文件的定义我们知道_T和_TEXT的功能是一样的,是一个预定义的宏。
理解_T()、_Text()宏即L”“ 因为:查看tchar.h头文件的定义我们知道_T和_TEXT的功能是一样的,是一个预定义的宏。#define _T(x) __T(x) #define _TEXT(x) __T(x我们再看看__T(x)的定义,发现它有两个:#ifdef _UNICODE // ... 省略其它代码 #define __T(x) L ## x // ... 省略其它代码 #else /* ndef _UNICODE */ // ... 省略其它代码 #define __T(x) x // ... 省略其它代码 #endif /* _UNICODE */当我们的工程的Character Set设置为Use Unicode Character Set时_T和_TEXT就会在常量字符串前面加L,否则(即Use Multi-Byte Character Set时)就会以一般的字符串处理。

VSIDE中设置“Unicode字符集”和“多字节字符集”的对系统的影响:
(1)预定义的影响
当设置为Unicode Character Set时,会有预编译宏:_UNICODE、UNICODE
在C/C++ 预定义配置中,可以看到:
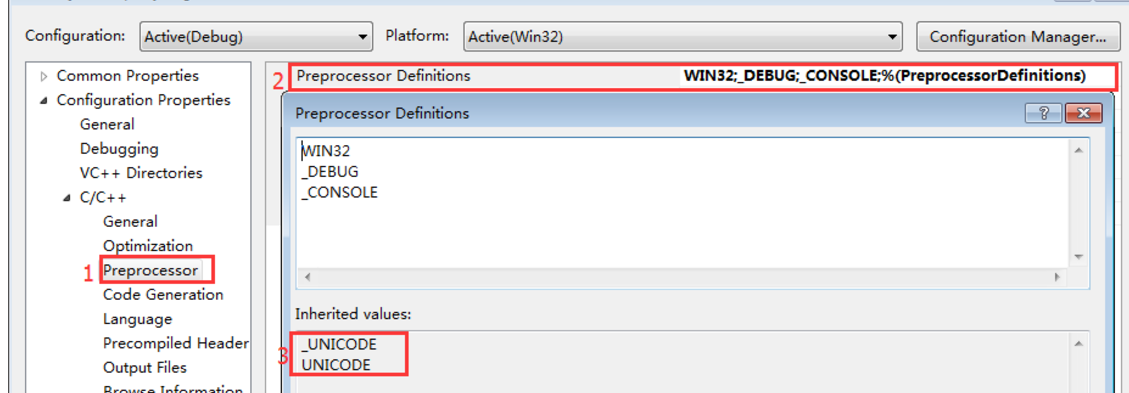
当设置为Use Multi-Byte Character Set时,会有预编译宏:_MBCS

(2)对VS 数据类型的影响
多字节字符集(MBCS),与 Unicode字符集 不同设置,对Visual C++ 内置的宏定义影响也不一样,如下图:
当设置为MBCS时: TCHAR 则指char(多字节字符类型); LPTSTR 则指代 char*,
当设置为Unicode时: TCHAR 则指wchar_t(多字节字符类型); LPTSTR 则指代 wchar_t*,
其他宏则分别指明了类型:“W”值宽字节 wchar_t, 否则不带W的,则是“多字节 char类型”

(3)相互转换方法
- LPWSTR->LPTSTR: W2T();
- LPTSTR->LPWSTR: T2W();
- LPCWSTR->LPCSTR: W2CT();
- LPCSTR->LPCWSTR: T2CW();
- ANSI->UNICODE: A2W();
- UNICODE->ANSI: W2A();
























 898
898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









