










📮 求内推
👩 个人简介:听障人,96年,计算机专业(本科),从事数据分析工作
🛠 语言与工具:包括但不限于Python、SQL、tableaubi、finebi、powerbi。
💻 期望岗位:数据分析、数据运营、报表开发等(hc偏技术方向)
📍 期望城市:杭州
项目背景
在当今美食多元化的时代,披萨已然成为了人们日常生活中不可或缺的一部分,而在当今激烈竞争的餐饮业中,数据成为了制胜的关键,本数据集包含了某披萨品牌一整年的上万条订单数据,通过探索分析本数据集,可以了解食品销售,洞悉消费者趋势、优化产品组合和提升盈利能力。
问题描述
01探索披萨消费趋势
披萨消费存在怎样的季节性和时间性趋势?
在不同季节、月份或周天数内,哪些时期披萨销售最为活跃?
是否存在特殊日期(如假日或特殊活动日)对销售的显著影响?
02定价与销量的关系
不同大小或类别的披萨是否有不同的定价策略?
单位价格的变化是否与销售数量有关?
03成本与利润分析
每种披萨的制作成本是多少?
哪些披萨为企业带来最高的利润?
数据说明
数据来源:和鲸社区(搜披萨订单数据即可)
| 字段名 | 说明 |
|---|---|
| pizza_id | 可供订购的披萨id |
| order_id | 订单id |
| pizza_name_id | 披萨名称id |
| quantity | 该订单的披萨数量 |
| order_date | 订单日期 |
| order_time | 订单时间 |
| unit_price | 该订单的披萨单价 |
| total_price | 该订单的披萨总价 |
| pizza_size | 披萨尺寸:S、M、L、XL、XXL |
| pizza_category | 披萨类别:素食、非素食 |
| pizza_ingredients | 披萨制作配料 |
| pizza_name | 披萨的名称 |
step1.导入模块
import pandas as pd
from datetime import datetime as dt
import numpy as np
import re
import plotly.graph_objects as go
import plotly.express as px
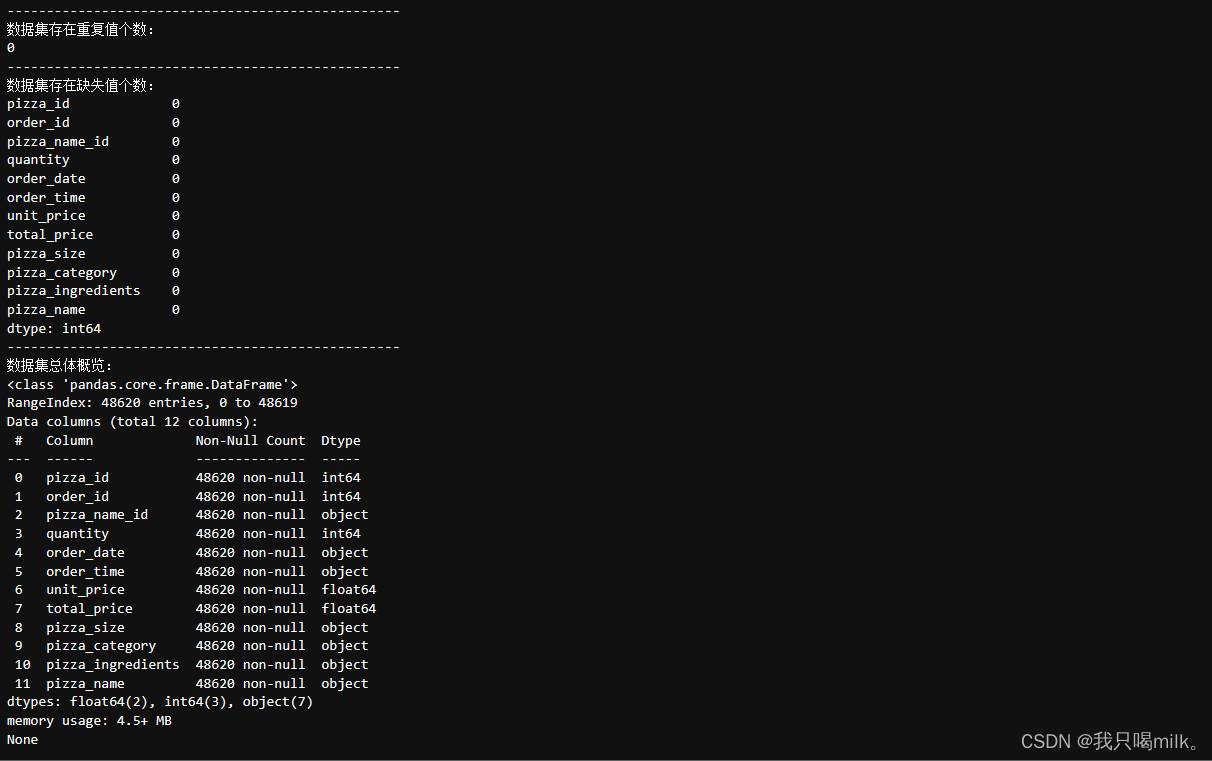
step2.数据概览
df = pd.read_csv(r'D:\pythonbag\Datas\pizza_sales.csv')
print('-'*50)
print('数据集存在重复值个数:')
print(df.duplicated().sum())
print('-'*50)
print('数据集存在缺失值个数:')
print(df.isna().sum())
print('-'*50)
print('数据集总体概览:')
print(df.info())
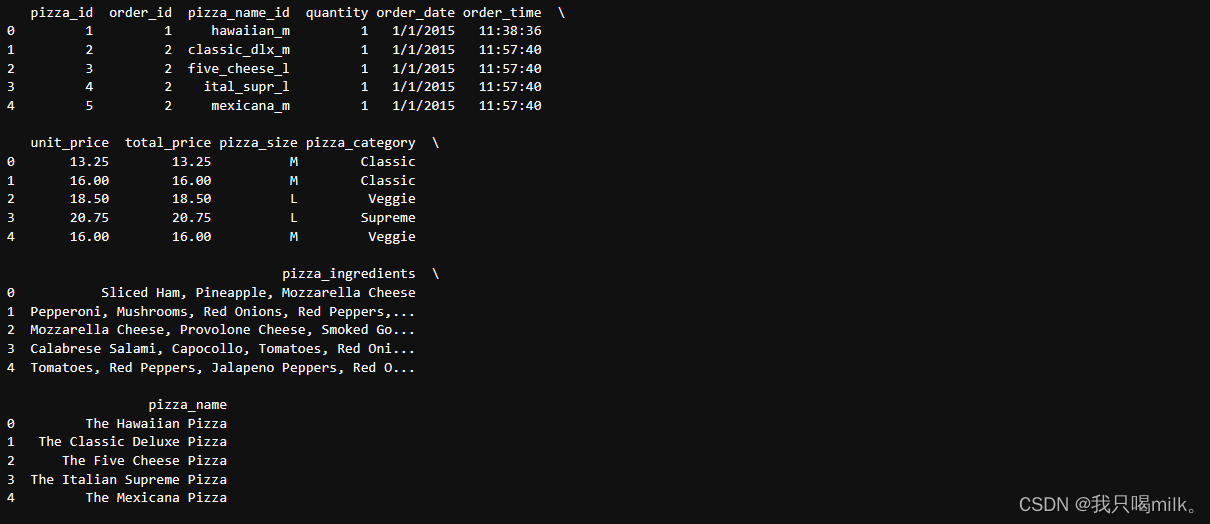
print(df.head(5))
step3.数据处理
# 将pizza_id和order_id的数据类型转换为字符串类型
df['pizza_id'] = df['pizza_id'].astype(str)
df['order_id'] = df['order_id'].astype(str)
# 发现时间格式不统一(d/m/y、d-m-y),将时间格式的字符/替换成字符-
df['order_date'] = df['order_date'].replace('/','-',regex=True)
# 将object类型的order_date转换成datetime类型
df['order_date'] = pd.to_datetime(df['order_date'],format='%d-%m-%Y')
# 提取月份(分析哪个销售时段最火)
# df['order_month'] = df['order_date'].dt.strftime('%b') # %B完整的月份名,%b简写的月份名
df['order_month'] = df['order_date'].dt.month
# 用映射月份到季度的方法提取季节(分析哪个销售时段最火)
def map_to_quarter(month):
if month in range(3,6):
return 'Spring'
elif month in range(6,9):
return 'Summer'
elif month in range(9,12):
return 'Autumn'
else:
return 'Winner'
df['order_season'] = df['order_date'].dt.month.map(map_to_quarter)
# df['order_season'] = pd.cut(df['order_date'].dt.month,bins=[1,4,7,10,13],labels=['Q1','Q2','Q3','Q4']) # pd.cut()更合适连续数值的分桶
# 提取星期名(分析哪个销售时段最火)
df['order_weekday'] = df['order_date'].dt.strftime('%a') # %A完整的星期名,%a简写的星期名
# 提取小时(分析哪个销售时段最火)
# 方法一:转换为datetime格式
df['order_hour'] = pd.to_datetime(df['order_time'],format='%H:%M:%S') # 生成了含有日期和时间的数据,而日期是1900/1/1
df['order_hour'] = df['order_hour'].dt.hour # 只提取时间部分
# 方法二:正则表达式
# def extract_hour(str_time):
# match = re.search(r'^(\d{1,2}):',str_time) # 从开头到第一个冒号之间提取一两位整数即小时
# return int(match.group(1))
# df['order_hour'] = df['order_time'].map(extract_hour)
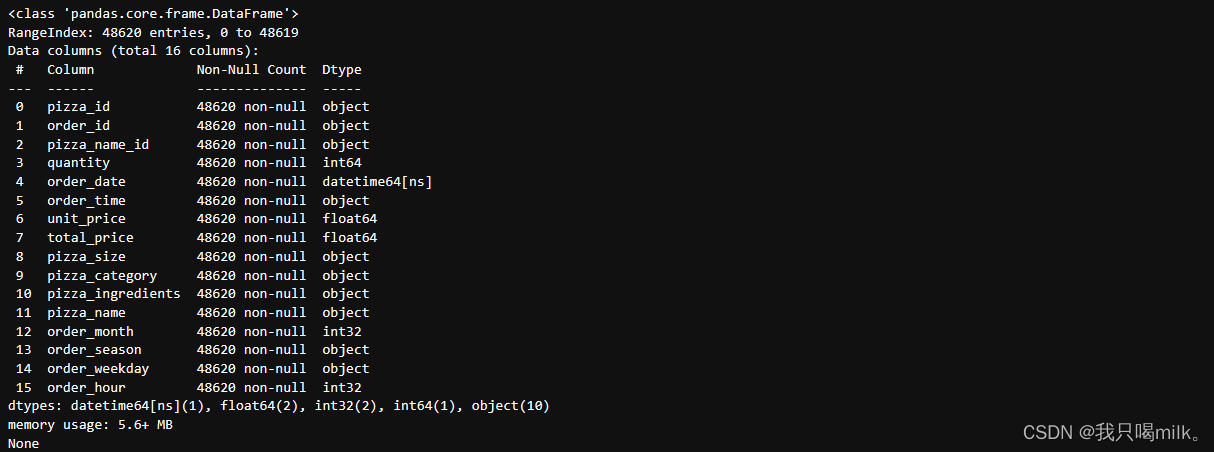
print(df.info())
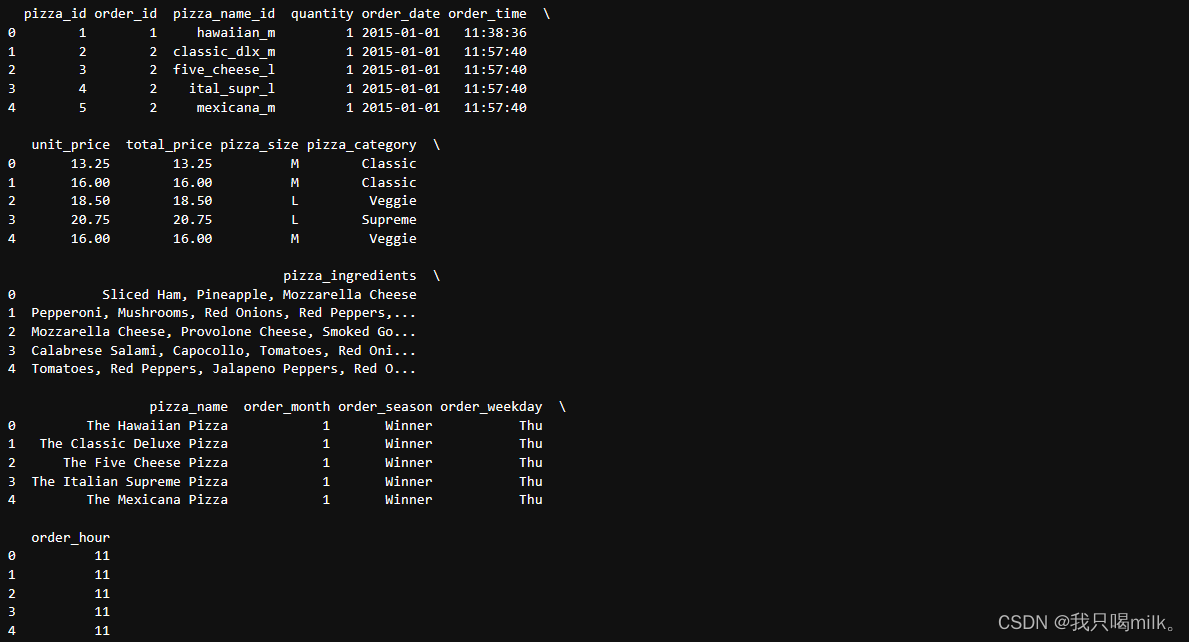
print(df.head(5))
step4.探索披萨消费趋势
4.1 探索披萨消费在时间点的趋势
hour_df = df.groupby(by='order_hour',as_index=False).agg({'quantity':'sum'})
print(hour_df)
fig4 = px.line(hour_df,title='披萨每小时销量可视化',template='plotly_white',x='order_hour',y='quantity',labels={'order_hour':'Hour'})
fig4.show()

小结:销量从上午十点开始,到12点到达峰值(午餐),之后稍微下降(下午茶),到17点又回升(晚餐),晚饭结束后开始逐渐下降。
4.2 探索披萨消费在每日的趋势
daily_df = df.groupby(by='order_date',as_index=False).agg({'quantity':'sum'})
print(daily_df)
fig_daily = px.line(daily_df,title='披萨每日销量可视化',template='plotly_white',x='order_date',y='quantity',labels={'order_date':'date'})
fig_daily.show()

小结:每日销量大致在100-200范围之内,有个别日子销量特别高,250份左右,可能当天做了什么活动刺激客户购买力度。
4.3 探索披萨消费在周天数的趋势
weekday_df = df.groupby('order_weekday',as_index=False).agg({'quantity':'sum'})
# 使用映射方法修改周天数顺序
wd_dict = {'Mon':'1','Thu':'2','Wed':'3','Tue':'4','Fri':'5','Sat':'6','Sun':'7'}
weekday_df['index'] = weekday_df.order_weekday.map(wd_dict)
weekday_df = weekday_df.sort_values(by='index').reset_index(drop=True)
# print(weekday_df)
fig2 = px.bar(weekday_df,title='披萨每周天数销量可视化',template='plotly_white',x='order_weekday',y='quantity',labels={'order_weekday':'Weekday'})
fig2.show()

小结:每周天数销量大概在6000-8000范围之内,其中周五销量是最高。
4.4 探索披萨消费在不同月份的趋势
monthly_df = df.groupby('order_month',as_index=False).agg({'quantity':'sum'})
# print(monthly_df)
fig = px.line(monthly_df,title="披萨每月销量可视化",template='plotly_white',x='order_month',y='quantity',labels={'order_month':'Month'})
fig.show()

小结:从月度销量来看,在这一年中销量最好的是七月,九月十月跌倒低谷了。
4.5 探索披萨消费在不同季节的趋势
season_df = df.groupby('order_season',as_index=False).agg({'quantity':'sum'})
#使用映射方法修改季节顺序
season_dict = {'Spring':'1','Summer':'2','Autumn':'3','Winner':'4'}
season_df['index'] = season_df.order_season.map(season_dict)
season_df = season_df.sort_values(by='index').reset_index(drop=True)
# print(season_df)
fig1 = px.pie(season_df,title='披萨每季节销量可视化',template='plotly_white',names='order_season',values='quantity',hole=0.5,labels={'order_season':'Season'})
fig1.show()

小结
从前面几个时间分析可以看出,披萨基本上不受季节影响,且在中午12点到一点和晚上17点到18点销售量最高,工作日周五销售量也很高。披萨作为一款广受全世界欢迎的快餐食品,确实方便了大部分上班族。
step5 单价与销量的关系
5.1 披萨单价箱线图
pizza_box = px.box(df,y='unit_price',title='披萨单价分布可视化')
pizza_box.show()

小结:大部分披萨集中在16.5元,最低和最高分别为9.3元和25.5元,有极少披萨超过35元。
5.2 不同尺寸披萨单价箱线图
size_box = px.box(df,x = 'pizza_size',y='unit_price',title='不同尺寸披萨单价分布可视化',category_orders={'pizza_size':['S','M','L','XL','XXL']})
size_box.show()

小结:尺寸越大,单价就越贵。s码披萨12元,M码披萨16.25元,L码披萨20.5元,XL码披萨27元,XXL码披萨38元
5.3 不同披萨种类单价箱线图
kind_box = px.box(df,x='pizza_category',y='unit_price',title='不同披萨种类单价分布可视化')
kind_box.show()

小结:顺序如下:经典披萨;蔬菜披萨;超级披萨;鸡肉披萨。
5.4 不同尺寸披萨销量情况
size_df = df.groupby(by='pizza_size',as_index=False).agg({'quantity':'sum'})
print(size_df)
size_bar = px.bar(size_df,x='pizza_size',y='quantity',title='不同尺寸披萨销量可视化',category_orders={'pizza_size':['S','M','L','XL','XXL']})
size_bar.show()

小结:其中L码披萨销量最好,依次是M码和S码,XL和XXL码销量特别少。
5.5 不同种类披萨销量
kind_df = df.groupby(by='pizza_category',as_index=False).agg({'quantity':'sum'})
print(kind_df)
kind_bar = px.bar(kind_df,x='pizza_category',y='quantity',title='不同种类披萨效率可视化')
kind_bar.show()

小结:其中classic披萨销量最好,其余三个销量都不相上下。
进一步分析经典披萨具体哪种卖的最好
classic_df = df[df['pizza_category']=='Classic']
# print(classic_df.head())
classic_df = classic_df.groupby(by='pizza_name',as_index=False).agg({'quantity':'sum'})
print(classic_df)
classic_bar = px.bar(classic_df,x='pizza_name',y='quantity',title='经典披萨种类销量可视化')
classic_bar.show()

step6 成本和利润分析
6.1 计算成本和利润
# 添加成本列和利润列,假设每种披萨成本为单价的60%
df['cost'] = df['total_price'] * 0.6
df['profit'] = df['total_price'] - df['cost']
print(df.head(5))
6.2 每种披萨的制作成本可视化
cost_df = df.groupby(by='pizza_name',as_index=False).agg({'cost':'mean'}).sort_values(by='cost',ascending=False).reset_index(drop=True).round(2)
print(cost_df)
fig7 = px.bar(cost_df,template='plotly_white',title='每种披萨的制作成本可视化',x='pizza_name',y='cost',labels={'pizza_name':'Pizza','cost':'Cost'})
fig7.show()

6.3 披萨的利润可视化
profit_df = df.groupby(by='pizza_name',as_index=False).agg({'profit':'sum'}).sort_values(by='profit',ascending=False).reset_index(drop=True).round(2)
print(profit_df)
fig8 = px.bar(profit_df,template='plotly_white',title='披萨的利润可视化',x='pizza_name',y='profit',labels={'pizza_name':'Pizza','profit':'Profit'})
fig8.show()

总结
- 每天销量最好是在中午12点到13点和傍晚18点到19点,而下午和晚上仍有一些销量;每日销量大概在100-200范围之内;每周销量大概在6000-8000范围之内,其中周五销量最高;从月度销量来看,销量最好的是七月,九月十月跌倒低估了,整体来看销量有些波动;在每个季节中销量似乎是差不多,由此可见披萨基本上不受季节影响。
- 披萨平均单价为16.5元,其中尺寸越大单价就越贵,其中L码披萨销量最高,依次是M和S码;不同种类披萨单价都差不多,其中经典披萨很受人喜欢,其余三个种类不相上下。
- 假设成本为披萨单价的60%,成本是最高的是the brie carre pizza,但是它利润却是最低的。可以适当把成本调低一些,或者提高其销量。

















 3115
3115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









