







📮 求内推
👩 个人简介:听障人,96年,计算机专业(本科),从事数据分析工作
🛠 语言与工具:包括但不限于Python、SQL、tableaubi、finebi、powerbi。
💻 期望岗位:数据分析、数据运营、报表开发等(hc偏技术方向)
📍 期望城市:杭州
背景描述
本数据集汇集了某个电商平台的用户基本信息、行为习惯和互动数据。它包括用户的年龄、性别、居住地区、收入水平等基本属性,以及他们的兴趣偏好、登录频率、购买行为和平台互动等动态指标。 数据集关注的焦点在于电商领域,旨在通过用户行为的深入分析,揭示其偏好和需求。通过这些数据,商家能够更好地理解消费者,制定有效的市场策略,满足用户期望,推动业务发展。
数据说明
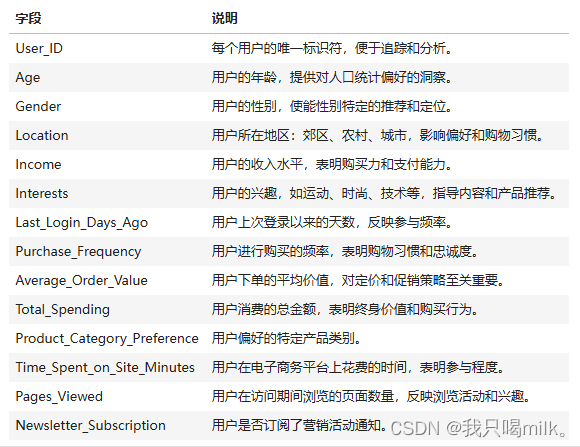
问题描述
用户活跃分析
用户分群
数据清洗及预览
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import KMeans # 聚类算法
from sklearn.preprocessing import StandardScaler # 标准化
from sklearn.metrics import silhouette_score # 轮廓系数
from sklearn.metrics import davies_bouldin_score # 计算簇间相似度
from sklearn.decomposition import PCA # 降维df = pd.read_csv(r'\user_personalized_features.csv',index_col=['Unnamed: 0'])
display(df.head())
print('-'*50)
print("该数据集维度为:",df.shape)
print('-'*50)
print("该数据集重复值个数:\n",df.duplicated().sum())
print('-'*50)
print("该数据集缺失值个数:\n",df.isna().sum())
print('-'*50)
print("该数据集的基本信息:\n")
display(df.info())
print('-'*50)
print("该数据集的描述统计:")
display(df.describe())

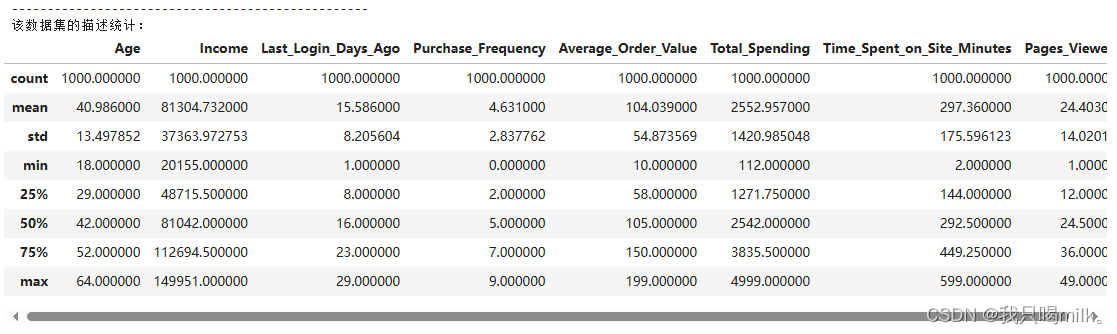
解读:
Age:电商用户的年龄主要分布在18-64岁之间,平均年龄为40岁。由于29~52岁占了总体的50%,因此年龄分布呈现中年集中的现象。
Income:电商用户的收入主要分布在20155-149951元之间,平均收入为81305元,表示用户收入差异较大。其中中位数为81042元,表示有一半用户超过了此水平,但高收入群体较小,约占了总体4/1,而大部分用户收入则较为密集分布在中等水平上。
Last_Login_Days_Ago:电商用户距离上次登录的时间天数主要分布在1-29天之间,平均距离上次登录时间为15.5天。其中25%分位数为8天,表示25%用户在最近8天内有登录行为,意味着有75%用户距离上次登录的时间超过8天,大多数用户可能不够活跃。
Purchase_Frequency:电商用户的购买频率主要分布在0-9次之间,平均为4.6次。其中25%分位数为2次,表示有25%用户的购买率较低下,中位数为5次,表示有一半的用户购买行为较为频繁。
Average_Order_Value:电商用户下单的平均金额主要分布在10-199元之间,平均金额为104元。其中中位数为105元,体现了用户倾向中等价位的购物策略。75%订单不超过150元,表示高价位的产品可能比较少。整体消费偏好经济实惠。
Total_Spending:电商用户消费的总金额主要分布在112-4999元之间,平均总金额为2553元。其中25%分位数为1271元,表示有25%用户消费能力较低。25%到75%的跨度,随着消费的增加,用户体量可能会随之减少,75%到100%的用户可能更少。
Time_Spent_on_Site_Minutes:电商用户在平台上停留时间主要分布在2-599分钟之间,平均停留时间为297分钟。其中25%分位数为144分钟,意味着有75%用户在该平台停留时间超过约2个小时。
Pages_Viewed:电商用户浏览页数主要分布在1-49页之间,平均浏览页数为24.4页。其中25%分位数为12页,意味着有75%用户浏览的页数超过12页。
# category_unique = ['Gender','Location','Interests','Product_Category_Preference']
# for name in category_unique:
# print(f'{name}:{df[name].unique()}')
# 使用for判断特征是否object类型再取唯一值。
for name in df.iloc[:,1:].columns:
if df[name].dtypes == 'object':
print(f'{name}:{df[name].unique()}')
描述性可视化(分类特征)
fig = plt.figure(figsize=(15,13))
# 使用循环生成多个子图,减少代码冗余
cols = ['Gender','Location','Interests','Product_Category_Preference','Newsletter_Subscription']
# enumerate()用于同时遍历一个可迭代对象的索引和值
for i,col in enumerate(cols,1):
ax = fig.add_subplot(2,3,i)
if df[col].dtypes == 'bool':
sns.histplot(data=df[col],ax=ax,discrete=True) # discrete=True 设置此列为离散数据
ax.set_xticks([0,1])
ax.set_xticklabels(labels = ['False','True'])
else:
sns.histplot(data=df[col],ax=ax)
if df[col].dtypes == 'object':
# 明确x轴刻度位置即刻度数量
ax.set_xticks(range(len(df[col].unique())))
# 设置x轴刻度标签及旋转
ax.set_xticklabels(labels=df[col].unique(),rotation=20)
ax.set_title(f'{col}分布')
ax.set_xlabel(f'{col}')
ax.set_ylabel('number')
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7254
7254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









