







目录
简介
策略梯度(Policy Gradient)的缺点在于采样量大,且每一次更新参数都需要采样n轮,更新完又要去采样……换言之,对游戏数据的利用率很低,太慢了。
这种采样-学习-采样的过程,是一种on-policy策略,接下来我们要将的PPO则不同,是一种off-policy的策略。
符号
本篇中运用到的符号和上一篇中的基本一致。
On/Off Policy
- On Policy:训练同一个agent,同时还要求他去对环境进行交互。
- Off Policy:训练的是一个agent,实际和环境交互的是另一个agent。
举个下棋的例子,如果你是通过自己下棋来不断提升自己的棋艺,那么就是on-policy的,如果是通过看别人下棋来提升自己,那么就是off-policy的
Off-poicy的好处是什么?他能重复利用别人的数据来进行训练。我update了1次参数,可以用他的数据来训练;我update了100次参数,还是可以用他的数据来训练。
这听起来似乎是反直觉的:我参数都变了100次了,为什么还能用别人之前得到的数据来训练?这就涉及到一个重要性采样(importance sampling)的问题了。
重要性采样(importance sampling)
重要性采样,即使用q分布来逼近p分布的方法。公式如下:
E
x
∼
p
[
f
(
x
)
]
=
∫
f
(
x
)
p
(
x
)
d
x
=
∫
f
(
x
)
p
(
x
)
q
(
x
)
q
(
x
)
d
x
=
E
x
∼
q
[
f
(
x
)
p
(
x
)
q
(
x
)
]
\begin{aligned} \mathbb{E}_{x\sim p}[f(x)]&=\int f(x)p(x)dx\\ &=\int f(x)\frac{p(x)}{q(x)}q(x)dx\\ &=\mathbb{E}_{x\sim q}[f(x)\frac{p(x)}{q(x)}] \end{aligned}
Ex∼p[f(x)]=∫f(x)p(x)dx=∫f(x)q(x)p(x)q(x)dx=Ex∼q[f(x)q(x)p(x)]
其中,
p
(
x
)
q
(
x
)
\frac{p(x)}{q(x)}
q(x)p(x)叫作重要性权重(importance weight)。
这样,我们就完成用q分布逼近p分布,也即用训练的actor来逼近与环境交互的actor。
实际运用中,p和q的分布不能相差过大,否则需要多次采样才能得到较为近似的结果。
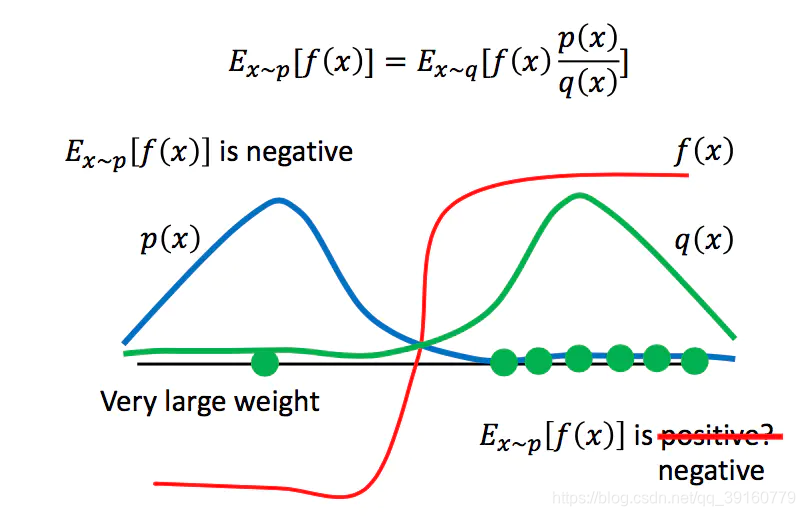
如上图,当
x
∼
p
(
x
)
x\sim p(x)
x∼p(x)时,我们采样的
p
(
x
)
p(x)
p(x)大部分在右半侧,这是由p的分布决定的。这样的采样会导致我们得到
f
(
x
)
f(x)
f(x)结果为正的错误结论。只有当采样数量非常多时,我们才能采样到左半侧的点,这里的点q很小p很大,所以重要性权重
p
(
x
)
q
(
x
)
\frac{p(x)}{q(x)}
q(x)p(x)也很大,这样就会一下把
f
(
x
)
f(x)
f(x)的期望值往负数上拉,从而得到正确结果。而这一切的前提在于,足够多的的采样量,如果采样次数不够,可能一直采的都是右半侧的点。
好在实际训练的时候我们可以延迟更新参数
θ
′
\theta'
θ′(即不断更新分布
q
(
x
)
q(x)
q(x)),大概50轮更新一次的样子,这样既能保证pq之间的距离不要太大,训练又不会太慢。
修改 ∇ R ˉ θ \nabla\bar{R}_\theta ∇Rˉθ
在policy gradient(即on-policy)中,有:
∇
R
ˉ
θ
=
E
τ
∼
p
θ
(
τ
)
[
R
(
τ
)
∇
l
o
g
p
θ
(
τ
)
]
\nabla\bar{R}_\theta=\mathbb{E}_{\tau \sim p_\theta (\tau)}[R(\tau)\nabla logp_\theta(\tau)]
∇Rˉθ=Eτ∼pθ(τ)[R(τ)∇logpθ(τ)]
公式作出如下变换:
∇
R
ˉ
θ
=
E
τ
∼
p
θ
′
(
τ
)
[
p
θ
(
τ
)
p
θ
′
(
τ
)
R
(
τ
)
∇
l
o
g
p
θ
(
τ
)
]
\nabla\bar{R}_\theta=\mathbb{E}_{\tau \sim p_\theta' (\tau)}[\frac{p_\theta(\tau)}{p_{\theta'}(\tau)}R(\tau)\nabla logp_\theta(\tau)]
∇Rˉθ=Eτ∼pθ′(τ)[pθ′(τ)pθ(τ)R(τ)∇logpθ(τ)]
在原来的方法里,我们用
π
θ
\pi_\theta
πθ采样更新参数,更新完参数后又用模型
π
θ
\pi_\theta
πθ重新采样,很慢。现在我们换一种方式,用
π
θ
′
\pi_{\theta'}
πθ′采样,再用采样来的数据训练
π
θ
\pi_\theta
πθ。由于固定
θ
′
\theta'
θ′不变,这样我们就能重复利用不变的q分布(即
θ
′
\theta'
θ′)来逼近变化的p分布(即
θ
\theta
θ),而且大大减少了采样花费的时间。
不是 R ( τ ) R(\tau) R(τ)而是 A θ ( s t , a t ) A^\theta(s_t,a_t) Aθ(st,at)
上一篇中我们讨论过了,直接计算整个游戏过程的reward再反馈到所有行为上是不合理的,所以我们用优势函数A来代替R。同样地,接下来我们讨论更改为A后的公式应该怎么修改。
∇
R
ˉ
θ
=
E
(
s
t
,
a
t
)
∼
π
θ
[
A
θ
(
s
t
,
a
t
)
∇
l
o
g
p
θ
(
a
t
n
∣
s
t
n
)
]
=
E
(
s
t
,
a
t
)
∼
π
θ
′
[
P
θ
(
s
t
,
a
t
)
P
θ
′
(
s
t
,
a
t
)
A
θ
′
(
s
t
,
a
t
)
∇
l
o
g
p
θ
(
a
t
n
∣
s
t
n
)
]
=
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
p
θ
(
s
t
)
p
θ
′
(
s
t
)
A
θ
′
(
s
t
,
a
t
)
∇
l
o
g
p
θ
(
a
t
n
∣
s
t
n
)
]
=
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
∇
l
o
g
p
θ
(
a
t
n
∣
s
t
n
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
]
=
E
(
s
t
,
a
t
)
∼
π
θ
′
[
∇
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
]
\begin{aligned} \nabla\bar{R}_\theta&=\mathbb{E}_{(s_t,a_t) \sim \pi_\theta }[A^\theta (s_t,a_t)\nabla logp_\theta(a_t^n \vert s_t^n)]\\ &=\mathbb{E}_{(s_t,a_t) \sim \pi_{\theta'} }[\frac{P_\theta(s_t,a_t)}{P_{\theta'}(s_t,a_t)}A^{\theta'} (s_t,a_t)\nabla logp_\theta(a_t^n \vert s_t^n)]\\ &=\mathbb{E}_{(s_t,a_t) \sim \pi_{\theta'} }[\frac{p_\theta(a_t\vert s_t)}{p_{\theta'}(a_t\vert s_t)}\frac{p_{\theta}(s_t)}{p_{\theta'}(s_t)}A^{\theta'} (s_t,a_t)\nabla logp_\theta(a_t^n \vert s_t^n)]\\&=\mathbb{E}_{(s_t,a_t) \sim \pi_{\theta'} }[\frac{p_\theta(a_t\vert s_t)\nabla logp_\theta(a_t^n \vert s_t^n)}{p_{\theta'}(a_t\vert s_t)}A^{\theta'} (s_t,a_t)]\\ &=\mathbb{E}_{(s_t,a_t) \sim \pi_{\theta'} }[\frac{\nabla p_{\theta}(a_t\vert s_t)}{p_{\theta'}(a_t\vert s_t)}A^{\theta'} (s_t,a_t)]\\ \end{aligned}
∇Rˉθ=E(st,at)∼πθ[Aθ(st,at)∇logpθ(atn∣stn)]=E(st,at)∼πθ′[Pθ′(st,at)Pθ(st,at)Aθ′(st,at)∇logpθ(atn∣stn)]=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)pθ′(st)pθ(st)Aθ′(st,at)∇logpθ(atn∣stn)]=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)∇logpθ(atn∣stn)Aθ′(st,at)]=E(st,at)∼πθ′[pθ′(at∣st)∇pθ(at∣st)Aθ′(st,at)]
推导过程中有三个问题需要注意。
- 第一点,在第二步中我们将分布从 π θ \pi_\theta πθ转换为 π θ ′ \pi_{\theta'} πθ′,实际采样用的是 θ ′ \theta' θ′,因此优势函数给出的值不再是依靠参数 θ \theta θ,而是参数 θ ′ \theta' θ′,我们是直接假设两者近似的。
- 第二点,在第四步中我们要假设 p θ ( s t ) p θ ′ ( s t ) \frac{p_{\theta}(s_t)}{p_{\theta'}(s_t)} pθ′(st)pθ(st)为1,即两个参数下 s t s_t st出现的概率接近。这个假设是直觉性的,也是为了便于计算,没什么好说的。
- 第三点, ∇ f ( x ) = f ( x ) ∇ l o g f ( x ) \nabla f(x)=f(x)\nabla logf(x) ∇f(x)=f(x)∇logf(x),简单地高数知识。
于是我们得到了
∇
R
ˉ
θ
\nabla\bar{R}_\theta
∇Rˉθ。等式右侧只有一项与
θ
\theta
θ相关,而且这一项同样也是
∇
p
\nabla p
∇p,是梯度。等式两边同时去掉梯度算子符号,于是可以获得以下目标函数:
J
θ
′
(
θ
)
=
R
ˉ
θ
=
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
]
J^{\theta'}(\theta)=\bar{R}_\theta=\mathbb{E}_{(s_t,a_t) \sim \pi_{\theta'} }[\frac{p_{\theta}(a_t\vert s_t)}{p_{\theta'}(a_t\vert s_t)}A^{\theta'} (s_t,a_t)]
Jθ′(θ)=Rˉθ=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)]
目标函数的上标
θ
′
\theta'
θ′是说明它是用参数
θ
′
\theta'
θ′采样的数据来估计
θ
\theta
θ的。
添加约束
有了目标函数,一切看起来都很不错。但是实际上有一个问题:
p
θ
p_\theta
pθ和
p
θ
′
p_{\theta'}
pθ′不能差太多。这是我们之前的一个假设。现在,我们需要添加约束来证实这一点成立,而这也是PPO实际在做的。
怎么做呢?很简单,PPO的目标函数如下:
J
P
P
O
θ
′
(
θ
)
=
J
θ
′
(
θ
)
−
β
K
L
(
θ
,
θ
′
)
J^{\theta'}_{PPO}(\theta)=J^{\theta'}(\theta)-\beta KL(\theta,\theta')
JPPOθ′(θ)=Jθ′(θ)−βKL(θ,θ′)
其中,KL是KL散度,详情百度,可以理解为一种距离公式。不同的是,他计算的不是
θ
\theta
θ和
θ
′
\theta'
θ′参数上的距离,而是行为上的距离。
什么叫参数上的距离,什么叫行为上的距离?
参数上的距离很好理解,就是两个向量之间的距离,重点在于行为上的距离。
我们知道,两个Actor(即策略)分别用参数
θ
\theta
θ和
θ
′
\theta'
θ′,他们接收状态s,输出行为的概率分布
π
θ
(
s
)
\pi_\theta(s)
πθ(s)和
π
θ
′
(
s
)
\pi_{\theta'}(s)
πθ′(s)。而我们的KL散度指的就是这两个行为概率分布之间的距离,这就叫行为的距离。
参数上的距离意义不大,而行为上的距离能保证面对相同的state时,两个Actor能输出近似的行为概率分布。
上面这些就是基本的内容了,除此之外,我们还额外添加了一个约束。当
K
L
(
θ
,
θ
′
)
>
K
L
m
a
x
KL(\theta,\theta')>KL_{max}
KL(θ,θ′)>KLmax时,增加
β
\beta
β;当
K
L
(
θ
,
θ
′
)
<
K
L
m
i
n
KL(\theta,\theta')<KL_{min}
KL(θ,θ′)<KLmin时,减小
β
\beta
β。
K
L
m
a
x
KL_{max}
KLmax和
K
L
m
i
n
KL_{min}
KLmin都是自己设置的,这么做的目的是为了动态调整参数
β
\beta
β,防止太过追求
θ
\theta
θ和
θ
′
\theta'
θ′距离远近,导致
J
θ
′
(
θ
)
J^{\theta'}(\theta)
Jθ′(θ)没有起到想要的效果。
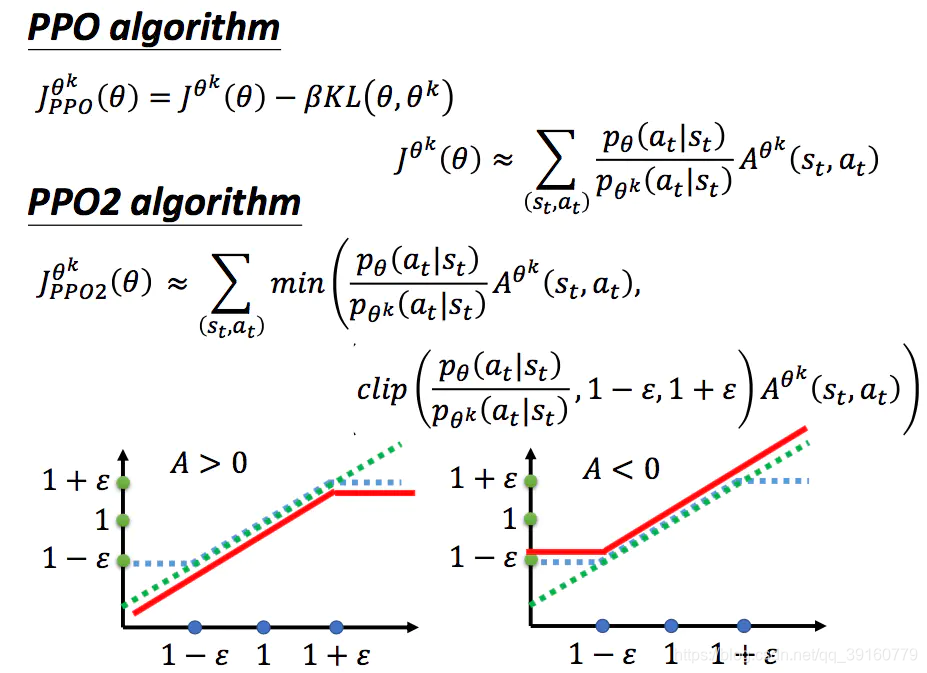
PPO2
PPO算法太复杂了,有一个PPO2,实现起来简单多了,我就不解释了,想了解的可以去B站直接搜李宏毅的视频。

















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









