






目录
-
基础篇: 必知必会的可视化技巧
-
matplotlib库表显示中文字体
-
matplotlib创建画布fig、ax的方法总结
-
使用pandas.plot函数进行快速可视化
-
赛博朋克可视化风格让你的图表科幻感十足
-
图表配色推荐
-
-
进阶篇: 可视化图展示形式-推荐用图总结
-
单条折线图太单调?可以使用面积图来代替
-
当多种类型的折线图相互叠加时,建议分类型展示
-
太多类型饼图展示不下?可以使用排序后渐变柱状图展示
-
同类型不同阶段对比图可以考虑使用双系列重叠图表示
-
多个维度的度量展示可以拆分为多个图(每个图展示单个维度)
-
同时展示季度和月份
-
类别标签过长建议为顶部错落展示
-
-
应用篇: 基于scikit-plot库对机器学习的结果进行可视化
-
绘制ks曲线
-
绘制聚类的elbow曲线
-
-
应用篇: 基于joyplot库精美展示山脊图和多维直方图
-
展示多维山脊图
-
展示多维直方图
-
-
应用篇: 对决策树模型进行精美可视化
-
利用dtreeviz库对决策树模型可视化
-
使用pybaobabat库展示
-
-
应用篇: 绘制多组数据统计分布状态图
-
分组统计柱状图使用seaborn库快速实现分组统计柱状图
-
基于seaborn的箱型图&&散点图&&分布显著性检验
-
-
实战篇: 精美可视化案例绘制
-
热力图:利用biokit库绘制精美热力图
-
滑珠图: 绘制滑珠图展示不同产品2个阶段的对比
-
多图布局:基于patchworklib库进行多个图表布局
-
词云图:利用WordCloud库来展示精美词云展示
-
交互式图表: 利用pyecharts绘制可交互的图表
-
多种度量分组展示: 绘制多图直观展示不同的度量指标
-
-
参考文档
基础篇: 必知必会的可视化技巧
matplotlib库表显示中文字体
给大家推荐下面2个库可彻底解决Matplotlib亚洲字体 (中文、韩文及日文等)乱码问题、轻松管理Matplotlib字体库;
-
mpl-font(github仓库:https://github.com/koho/mpl-font)
-
mplfonts(github仓库:https://github.com/Clarmy/mplfonts )
# 方式一
pip install mplfonts
!mplfonts init #安装好之后需要在bash环境单独执行
# 方式二
!pip install mpl_font==1.16.0
import mpl_font.noto
# 示例代码
import matplotlib.pyplot as plt
from mplfonts.util.manage import use_font
FONT_NAMES = {
"Noto Sans Mono CJK SC": "Noto等宽",
"Noto Serif CJK SC": "Noto宋体",
"Noto Sans CJK SC": "Noto黑体",
"Source Han Serif SC": "思源宋体",
"Source Han Mono SC": "思源等宽",
"SimHei": "微软雅黑",
}
fig,axes = plt.subplots(3,2,figsize=(12, 6))
for index,(font_name, desc) in enumerate(FONT_NAMES.items()):
use_font(font_name)
axes[int(index/2),index%2].text(0.1, 0.6, font_name, fontsize=20)
axes[int(index/2),index%2].text(0.1, 0.2, desc, fontsize=20)
plt.show()
输出结果:

matplotlib创建画布fig、ax的方法总结
当我们进行复杂图表绘制时,需要灵活性强。我通常喜欢实用matplotlib库来绘制复杂图表,其底层api支持几乎各种款式自定义,缺点就是需要对代码和函数接口深入了解。 matplotlib库中创建图的方式主要有下面几种:
-
通过fig创建ax主要有2种方式;方式一、方式二;
-
通过plt创建ax主要有3种方式;方式三、方式四、方式五;
-
插入画中画;即通过ax创建ax主要有1种方式;方式六
# 定义fig
fig= plt.figure(figsize=(8,12), dpi=200)
# 方式一
自定义画布ax
ax1 = fig.add_axes([0.1, 0.1, 0.8, 0.8]) # 散点图位置
ax2 = fig.add_axes([0.1, 0.9, 0.8, 0.1]) # 边际分布图位置
ax3 = fig.add_axes([0.9, 0.1, 0.1, 0.8]) # 边际分布图位置
#方式二
fig.subplots_adjust(left=0.1, wspace=0.06, hspace=0.06)
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(223)
ax4 = fig.add_subplot(224)
# 方式三
# 绘制不规则的网格ax(空间布局)
ax = plt.subplot2grid((3,3),(0,0),rowspan=1, colspan=1)
do_something(ax)
ax = plt.subplot2grid((3,3),(0,1),rowspan=1, colspan=1,projection='polar')
do_something(ax)
ax = plt.subplot2grid((3,3),(0,1),rowspan=1, colspan=2) # 使用一行2列的位置区间画图
do_something(ax)
# 方式四
fig, axes = plt.subplots(3,3)
ax1= axes[0,0] #第一个位置的画布
ax2= axes[2,2] #第一个位置的画布
plt.subplots_adjust(wspace=0.06, hspace=0.06)
# 方式五
ax= plt.subplot(221)
ax= plt.subplot(222)
plt.subplots_adjust(wspace=0.06, hspace=0.06)
# 方式六
from mpl_toolkits.axes_grid1.inset_locator import inset_axes
axins = inset_axes(ax, width=.4, height=.4,loc='upper left',
bbox_to_anchor=(0.01, 0.22, 1, 1),
bbox_transform=ax.transAxes,
borderpad=0)
axins.set_ylim(bottom=8,top=35)
axins.set_xlim(left=-.5,right=2.5)
#通过ax获得fig
fig =ax.get_figure()
# 关闭fig
plt.close(fig)
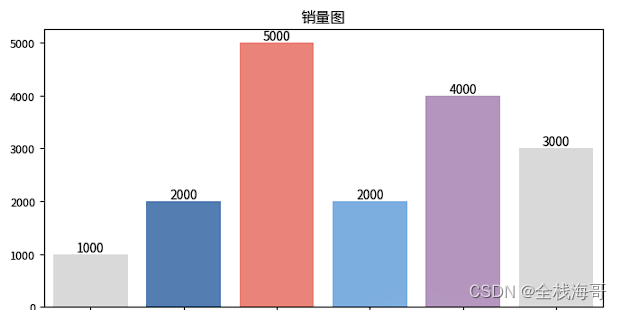
使用pandas.plot函数进行快速可视化
这里就以绘制的柱状图,可以看出非常的精简,用于快绘制想要的图表。
import pandas as pd
from mplfonts import use_font
import matplotlib.pyplot as plt
use_font('Noto Sans CJK SC')
test_dict = {'销售量': [1000, 2000, 5000, 2000, 4000, 3000], '收藏量': [1500, 2300, 3500, 2400, 1900, 3000]}
df = pd.DataFrame(test_dict, index=['一月', '二月', '三月', '四月', '五月', '六月'])
text_kwargs = dict(figsize=(8, 4), fontsize=9)
ax = df['销售量'].plot(title='销量图', kind='bar', rot=45, **text_kwargs)
m_ax = ax.bar(df.index.tolist(), df['销售量'].tolist(),color= ["#D9D9D9","#547DB1", '#EA8379','#7DAEE0','#B395BD'])
ax.bar_label(m_ax)
plt.show()
输出结果:
赛博朋克可视化风格让你的图表科幻感十足
mplcyberpunk 库(官方github:https://github.com/dhaitz/mplcyberpunk)是一个基于matplotlib库的主题库,提供赛博朋克风格科幻风格的主题,可以让你的图表更加精美。
!pip install mpl_font==1.16.0
import matplotlib.pyplot as plt
import mplcyberpunk
import mpl_font.noto
with plt.style.context("cyberpunk"):
categories = ['成都', '重庆', '上海', '西安', '南京']
values = [25, 67, 19, 45, 10]
colors = ["#D9D9D9","#547DB1", "#719DC9", "#C6D6EA", "#DEE7F3"]
fig, ax =plt.subplots(figsize=(6,3))
bars = ax.bar(categories, values, color=colors, zorder=2)
ax.bar_label(bars)
mplcyberpunk.add_bar_gradient(bars=bars)
plt.show()
图表配色推荐
给大家分享在平时绘图中好看常用的配色;
常见好看的色谱图
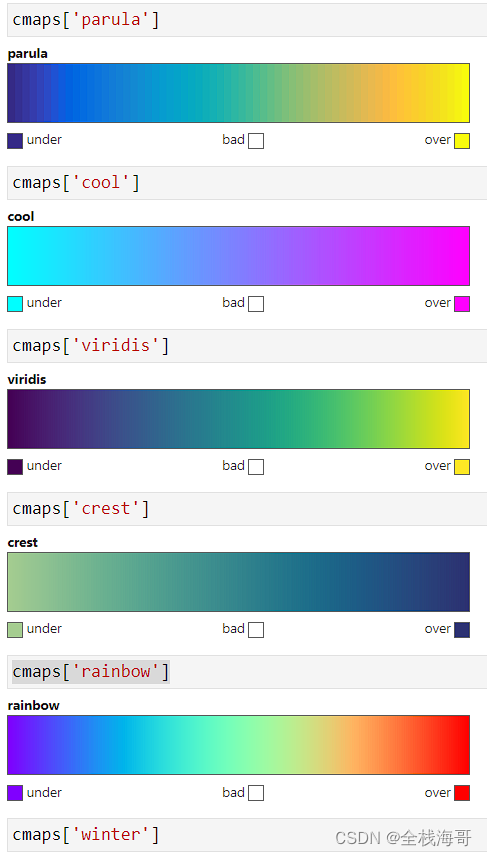
耐看的配色:
双色配色: #C9342B #339DB5
双色配色: #E6846D #8DCDD5
双色配色: #F9BEBB #89C9C8
双色配色: #9FC9DF #F1E1C7
双色配色: #C8D7EB #FAEBC7
双色配色: #9E9E9E #F5C96B
双色配色: #8A7197 #999A9E
双色配色: #B291B5 #3BA997
三色折线图配色: #C24976 #469393 #84C2AE
三色折线图配色: #EA8379 #7DAEE0 #B395BD
三色柱状图配色: #299D8F #E9C46A #D87659
三色柱状图配色: #EF76TA #456990 #48C0AA
四色柱状图配色: #55B7E6 #193E8F #E53528 #F09739
四色柱状图配色: #66529F #A37E7D #BF9895 #DAB2B2
四色柱状图配色: #DB432C #438870 #838AAF #C4B797
五色配图配色: #D9D9D9 #547DB1 #719DC9 #C6D6EA #DEE7F3
六色分面组图配色: #427AB2 #F09148 #FF9896 #DBDB8D #C59D94 #AFC7E8
六色密度图配色: #EEA599 #FAC795 #FFE9BE #E3EDEO #ABD3E1 #92B4C8
多色机制图配色:#43978F #9EC4BE #ABDOF1 #DCE9F4 #E56F5E #F19685 #F6C957 #FFB77F #FBE8D5
多色机制图配色: #D3D3D3 #DEBF80 #DCCD5B #73AD96 #5F9069 #375631
多色机制图配色: #343434 #DFE9F4 #245297 #85C17E #CDE8C3 #62AA67
进阶篇: 可视化图展示形式-推荐用图总结
单条折线图太单调?可以使用面积图来代替
折线图一般用于描述某个类型的趋势变化情况;一般来说对应的x轴的业务含义是有相对位置关系的。单条折线图展示过于单调,建议使用面积图来代替单一的折线图,使得图表丰富起来,下面是对应的案例展示。
from mplfonts.util.manage import use_font
use_font('Noto Sans CJK SC')
import matplotlib.pyplot as plt
import mplcyberpunk
with plt.style.context("cyberpunk"):
x = ['202309', '202310', '202311', '202312', '202401']
y = [25, 67, 19, 45, 10]
fig, axes =plt.subplots(1,2, figsize=(8,3),dpi=200)
ax=axes[0]
ax.set_title("不建议图表展示风格",color='red', fontsize=8)
ax.plot(x,y,marker='^')
use_font('Noto Sans CJK SC')
ax=axes[1]
ax.set_title("建议绘制展示风格",color='green', fontsize=8)
ax.plot(x,y,marker='^')
use_font('Noto Sans CJK SC')
mplcyberpunk.add_underglow(ax=ax, alpha_underglow=0.2)
fig.suptitle('单条折线图展示风格', color='C2',fontsize=8)
plt.show()
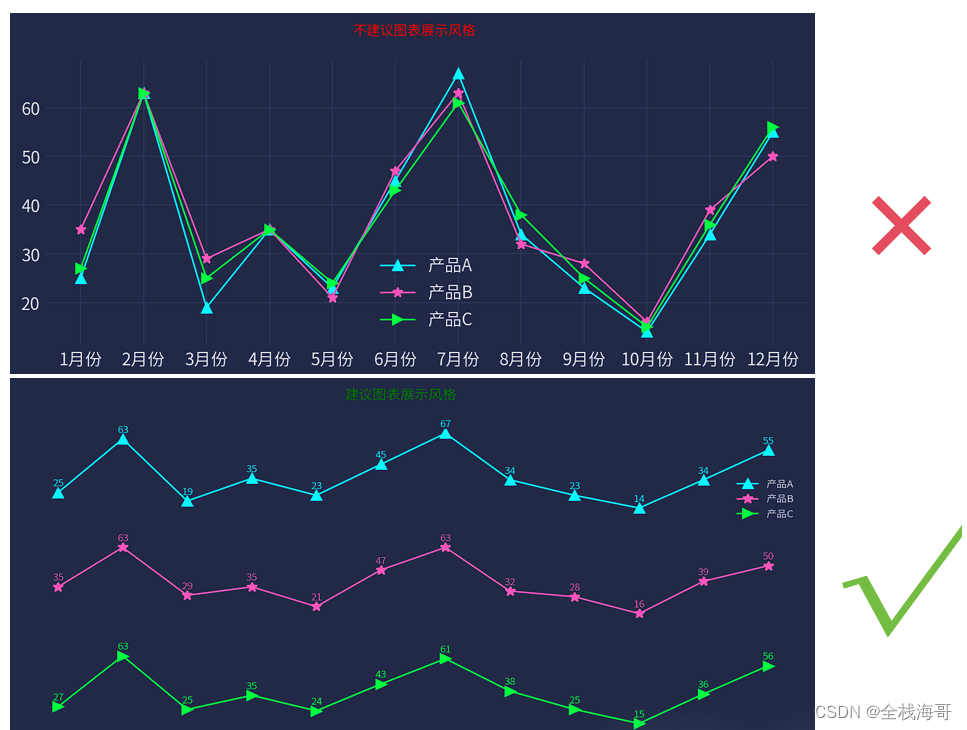
当多种类型的折线图相互叠加时,建议分类型展示
当多个类型的折线图相互叠加时,形成混乱一团无法较好的看清楚趋势,建议分开表示可以使得各类型趋势跟简单明了。下面是对应的案例展示。
from mplfonts.util.manage import use_font
use_font('Noto Sans CJK SC')
import matplotlib.pyplot as plt
import mplcyberpunk
with plt.style.context("cyberpunk"):
x = ['%d月份'%i for i in range(1,13)]
y1 = [25, 63, 19, 35,23,45,67,34,23,14,34,55]
y2 = [35, 63, 29, 35,21,47,63,32,28,16,39,50]
y3 = [27, 63, 25, 35,24,43,61,38,25,15,36,56]
fig, ax =plt.subplots(figsize=(8,3),dpi=200)
# ax.set_title("不建议图表展示风格",color='red', fontsize=8)
ax.plot(x, y1, marker='^', linewidth=1,color='C0',label='产品A')
ax.plot(x, y2, marker='*', linewidth=1,color='C1',label='产品B')
ax.plot(x, y3, marker='>', linewidth=1,color='C3',label='产品C')
ax.legend()
fig.suptitle('不建议图表展示风格', color='red',fontsize=8)
plt.subplots_adjust(hspace=0.1,wspace=0.1)
use_font('Noto Sans CJK SC')
plt.show()
with plt.style.context("cyberpunk"):
use_font('Noto Sans CJK SC')
x = ['%d月份'%i for i in range(1,13)]
y1 = [25, 63, 19, 35,23,45,67,34,23,14,34,55]
y2 = [35, 63, 29, 35,21,47,63,32,28,16,39,50]
y3 = [27, 63, 25, 35,24,43,61,38,25,15,36,56]
fig, axes =plt.subplots(3,1,figsize=(8,3.5),dpi=200)
ax1=axes[0]
o1,= ax1.plot(x,y1,marker='^',linewidth=1,color='C0',label='产品A')
for index,value in enumerate(y1):
ax1.text(index,value+10, f'{value}', ha='center', va='top', color='C0',fontsize=6,)
ax1.set_yticks([0,10,20,30,40,50,60,70])
ax1.axes.yaxis.set_visible(False)
ax1.axes.xaxis.set_visible(False)
ax1.grid()
ax=axes[1]
o2,= ax.plot(x,y2,marker='*',linewidth=1,color='C1',label='产品B')
for index,value in enumerate(y2):
ax.text(index,value+10, f'{value}', ha='center', va='top', color='C1',fontsize=6,)
ax.set_yticks([0,10,20,30,40,50,60,70])
ax.axes.yaxis.set_visible(False)
ax.axes.xaxis.set_visible(False)
ax.grid()
ax=axes[2]
o3,= ax.plot(x,y3,marker='>',linewidth=1, color='C3',label='产品C')
for index,value in enumerate(y2):
ax.text(index,value+10, f'{value}', ha='center', va='top', color='C3',fontsize=6,)
ax.axes.yaxis.set_visible(False)
ax.set_yticks([0,10,20,30,40,50,60,70])
ax.grid()
ax1.legend([o1,o2,o3],['产品A','产品B','产品C'],fontsize=6,ncol=1,loc='best')#'upper right',)
plt.subplots_adjust(hspace=0.1,wspace=0.1)
fig.suptitle('建议图表展示风格', color='green',fontsize=8)
# fig.tight_layout()
plt.show()
前后对比情况:
太多类型饼图展示不下?可以使用排序后渐变柱状图展示
饼图一般用于展示总量中各个类型(类型直接相互独立)的占用情况,一般展示的类型不超过5个。当类型超过5个后,会显得非常的臃肿,不利于突出重点。可以换成排序后渐变柱状图展示。下面是对应的案例展示。
from mplfonts.util.manage import use_font
use_font('Noto Sans CJK SC')
import matplotlib.pyplot as plt
import mplcyberpunk
with plt.style.context("cyberpunk"):
use_font('Noto Sans CJK SC')
fig, axes =plt.subplots(1,2,figsize=(10,3),dpi=200)
ax= axes[0]
colors=['#43978F', '#9EC4BE', '#ABD0F1', '#DCE9F4', '#E56F5E', '#F19685', '#F6C957', '#FFB77F', '#FBE8D5']
ax.pie([0.2, 0.17, 0.22, 0.13, 0.125, 0.025,0.12,0.01], shadow=True, # 饼图开启阴影
labels=['产品A', '产品B', '产品C', '产品D', '产品E', '产品F', '产品H', '产品G'],
autopct='%.2f%%', radius=1.1, # 设置饼图半径
colors= colors,
normalize=False)
ax=axes[1]
colors=[ '#ABD0F1','#43978F', '#9EC4BE','#DCE9F4', '#E56F5E', '#F19685','#FFB77F', '#F6C957', '#FBE8D5']
values =[0.22,0.2, 0.17, 0.13, 0.125, 0.12, 0.025,0.01]
categories = ['产品C','产品A', '产品B', '产品D', '产品E', '产品H', '产品F', '产品G']
bars = ax.bar(categories, values, color=colors, zorder=2)
ax.bar_label(bars)
use_font('Noto Sans CJK SC')
mplcyberpunk.add_bar_gradient(bars=bars,ax =ax )
plt.subplots_adjust(wspace=0.01)
fig.suptitle('多个类型的分布展示', color='green',fontsize=8)
plt.show()
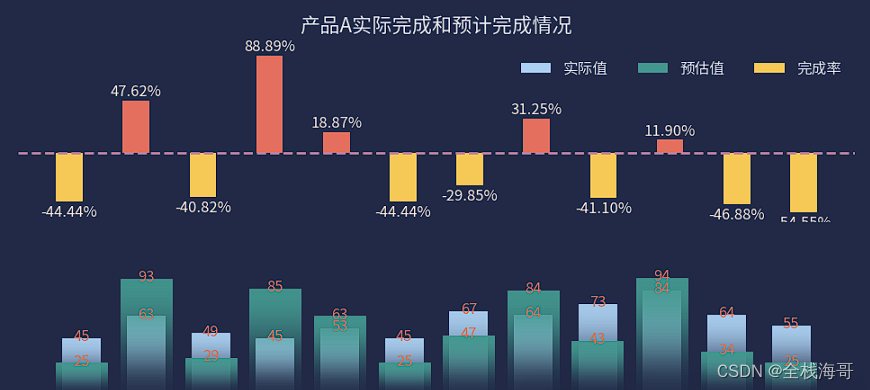
同类型不同阶段对比图可以考虑使用双系列重叠图表示
下面是一个案例展示利用双系列重叠图表示同类型不同阶段数据指标的变化情况。
from mplfonts.util.manage import use_font
use_font('Noto Sans CJK SC')
import matplotlib.pyplot as plt
import mplcyberpunk
import numpy as np
x = ['%d月'%i for i in range(1,13)]
y1 = np.array([45, 63, 49, 45,53,45,67,64,73,84,64,55])
y2 = np.array([25, 93, 29, 85,63,25,47,84,43,94,34,25])
# DCE9F4', '#E56F5E', '#F19685','#FFB77F', '#F6C957', '#FBE8D5']
with plt.style.context("cyberpunk"):
use_font('Noto Sans CJK SC')
fig, axes =plt.subplots(2,1,figsize=(6,2.5),dpi=200)
ax =axes[0]
ax.set_title("产品A实际完成和预计完成情况", fontsize=8)
delta_list = np.array([round((y2[i]-y1[i])/y1[i],4) for i in range(len(y1))])
colors = np.array(['#E56F5E' for _ in range(len(x))])
colors[delta_list<0]='#F6C957'
delta= ax.bar(x,delta_list,color=colors,width=0.4,)
for index,value in enumerate(y1):
if delta_list[index]>0:
ax.text(index,delta_list[index]+0.01, f'{delta_list[index]*100:0.2f}%', ha='center', va='bottom', color='#FBE8D5',fontsize=6,)
else:
ax.text(index,delta_list[index]-0.03, f'{delta_list[index]*100:0.2f}%', ha='center', va='top', color='#FBE8D5',fontsize=6,)
ax.axes.xaxis.set_visible(False)
ax.axes.yaxis.set_visible(False)
ax.axhline(y=0, linestyle='--', color=(194/255,127/255, 159/255), linewidth=1)
ax.legend([delta],['完成率'],fontsize=6,ncol=2,loc='upper left')#'upper right',)
ax =axes[1]
o1= ax.bar(x,y1,color='#ABD0F1',width=0.6,label='实际值')
for index,value in enumerate(y1):
ax.text(index,value+8, f'{value}', ha='center', va='top', color='#E56F5E',fontsize=6,)
o2= ax.bar(x,y2,color='#43978F',label='预估值')
for index,value in enumerate(y2):
ax.text(index,value+8, f'{value}', ha='center', va='top', color='#E56F5E',fontsize=6,)
ax.set_yticks([10*i for i in range(15)])
ax.set_yticklabels([10*i for i in range(15)])
ax.grid()
mplcyberpunk.add_bar_gradient(bars=o1,ax =ax )
mplcyberpunk.add_bar_gradient(bars=o2,ax =ax )
ax.axes.yaxis.set_visible(False)
axes[0].legend([o1,o2,delta,],['实际值','预估值','完成率'],fontsize=6,ncol=3,loc='upper right')#'upper right',)
plt.subplots_adjust(hspace=0.01,wspace=0.01)
plt.show()
输出效果图:
多个维度的度量展示可以拆分为多个图(每个图展示单个维度)
当对多个维度的数据进行可视化时,可以按照类型进行分类可视化,便于数据一目了然,下面是对应的案例。
from mplfonts.util.manage import use_font
use_font('Noto Sans CJK SC')
import matplotlib.pyplot as plt
import mplcyberpunk
import numpy as np
x = ['%d月'%i for i in range(1,13)]
y1 = np.array([45, 63, 49, 45,53,45,67,64,73,84,64,55])
y2 = np.array([25, 93, 39, 85,53,25,67,64,73,94,64,45])-10
y3 = np.array([55, 13, 89, 45,43,45,87,64,73,104,64,55])
with plt.style.context("cyberpunk"):
fig, ax =plt.subplots(figsize=(6,2.5),dpi=200)
use_font('Noto Sans CJK SC')
categories =sum([["产品A_2018_%s"%i,"产品A_2019_%s"%i,"产品B_2019_%s"%i] for i in x ],[])
y = sum([[y1[i],y2[i],y3[i]] for i in range(12) ],[])
ax.grid()
ax.axes.yaxis.set_visible(False)
bars = ax.bar(categories, y, color=sum([['C0','C1','C2' ] for _ in range(12)],[]) , zorder=2)
ax.bar_label(bars)
mplcyberpunk.add_bar_gradient(bars=bars,ax =ax )
ax.set_xticks(categories)
ax.set_xticklabels(categories,fontsize=6,rotation = 270)
fig.tight_layout()
fig.suptitle('不建议图表展示风格-以2个维度进行展示', color='red',fontsize=8)
plt.show()
with plt.style.context("cyberpunk"):
use_font('Noto Sans CJK SC')
fig, axes =plt.subplots(1,2,figsize=(6,2.5),dpi=200)
ax=axes[0]
o1,= ax.plot(x,y1,marker='^',linewidth=1,color='C0',label='2019',markersize=3)
for index,value in enumerate(y1):
ax.text(index,value+10, f'{value}', ha='center', va='top', color='C0',fontsize=6,)
o2,= ax.plot(x,y2,marker='*',linewidth=1,color='C1',label='2018',markersize=3)
for index,value in enumerate(y2):
ax.text(index,value+10, f'{value}', ha='center', va='top', color='C1',fontsize=6,)
ax.set_yticks([10*i for i in range(15)])
ax.set_yticklabels([10*i for i in range(15)])
ax.set_xticks(x)
ax.set_xticklabels(x,rotation = 270)
ax.set_title("产品A", fontsize=8)
ax.grid()
ax.legend([o1,o2],['2019','2018'],fontsize=6,ncol=2,loc='upper left')#'upper right',)
ax=axes[1]
o3,= ax.plot(x,y3,marker='>',linewidth=1, color='C3',markersize=3)
for index,value in enumerate(y3):
ax.text(index,value+ 10, f'{value}', ha='center', va='top', color='C3',fontsize=6,)
ax.axes.yaxis.set_visible(False)
ax.set_yticks([10*i for i in range(15)])
ax.set_yticklabels([10*i for i in range(15)])
ax.set_xticks(x)
ax.set_xticklabels(x,rotation = 270)
ax.set_title("产品B",fontsize=8)
ax.legend([o3],['2019'],fontsize=6,ncol=1,loc='upper left')#'upper right',)
ax.grid()
plt.subplots_adjust(hspace=0.1,wspace=0.01)
fig.suptitle('建议图表展示风格-分类型进行展示', color='green',fontsize=8)
plt.show()
同时展示季度和月份
有些指标需要展示季度和月份的趋势变化,可以将2类指标集中展示,下面是案例介绍:
from mplfonts.util.manage import use_font
use_font('Noto Sans CJK SC')
import matplotlib.pyplot as plt
import mplcyberpunk
with plt.style.context("cyberpunk"):
fig, axes=plt.subplots(1,2,figsize=(8,3.5),dpi=200)
ax =axes[0]
x = ['一季度','二季度','三季度','四季度']
y1 = [25+63+19, 35+23+45,67+34+23,14+34+55]
ax.grid()
ax.axes.yaxis.set_visible(False)
bars = ax.bar(x, y1, color=['C0','C0','C0','C0'], zorder=2)
ax.bar_label(bars)
mplcyberpunk.add_bar_gradient(bars=bars,ax =ax )
ax = axes[1]
x = ['%d月'%i for i in range(1,13)]
y1 = [25, 63, 19, 35,23,45,67,34,23,14,34,55]
ax.axes.yaxis.set_visible(False)
o1, = ax.plot(x, y1, marker='^', linewidth=1,color='C0')
ax.set_xticks(x)
ax.set_xticklabels(x,rotation = 270)
for index,value in enumerate(y1):
ax.text(index,value+3, f'{value}', ha='center', va='top',color='C2', fontsize=8,)
ax.grid()
fig.suptitle('合并季度和月份展示', color='green', fontsize=10)
plt.subplots_adjust(hspace=0.1,wspace=0.01)
use_font('Noto Sans CJK SC')
plt.show()
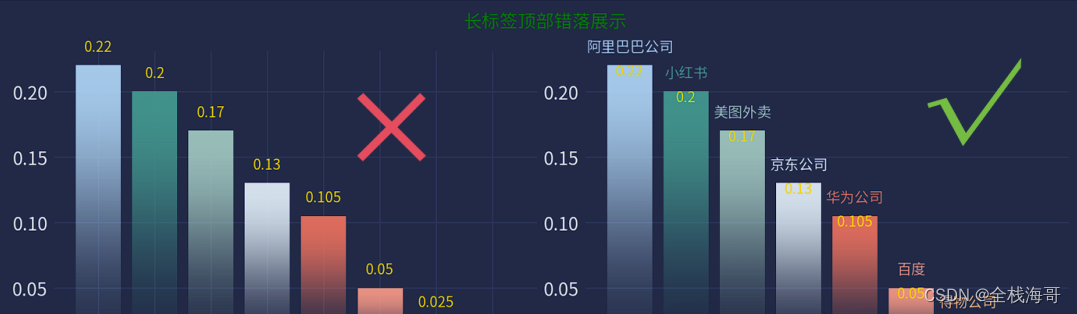
类别标签过长建议为顶部错落展示
当x轴的标签过长时,直接展示在x轴上会显示重叠,会影响展示效果。建议将X轴的标签放在柱状图的上面进行错落展示,直观明了。下面是对应的案例展示。
from mplfonts.util.manage import use_font
use_font('Noto Sans CJK SC')
import matplotlib.pyplot as plt
import mplcyberpunk
with plt.style.context("cyberpunk"):
use_font('Noto Sans CJK SC')
fig, axes =plt.subplots(1,2,figsize=(10,3),dpi=200)
ax= axes[0]
colors=[ '#ABD0F1','#43978F', '#9EC4BE','#DCE9F4', '#E56F5E', '#F19685','#FFB77F', '#F6C957', '#FBE8D5']
values =[0.22,0.2, 0.17, 0.13, 0.105, 0.05, 0.025,0.01]
categories = ['阿里巴巴公司','小红书', '美图外卖', '京东公司', '华为公司', '百度', '得物公司', '阿里云公司']
bars = ax.bar(categories, values, color=colors, zorder=2)
for index,value in enumerate(categories):
ax.text(index,values[index]+0.02, f'{values[index]}', ha='center', va='top',color='C2', fontsize=8,)
use_font('Noto Sans CJK SC')
mplcyberpunk.add_bar_gradient(bars=bars,ax=ax )
ax=axes[1]
ax.axes.xaxis.set_visible(False)
ax.set_yticks([0.00,0.05,0.10,0.15,0.20,0.25,0.30])
colors=[ '#ABD0F1','#43978F', '#9EC4BE','#DCE9F4', '#E56F5E', '#F19685','#FFB77F', '#F6C957', '#FBE8D5']
values =[0.22,0.2, 0.17, 0.13,0.105, 0.05, 0.025,0.01]
for index,value in enumerate(categories):
ax.text(index,values[index]+0.02, f'{value}', ha='center', va='top', color=colors[index], fontsize=8,)
ax.text(index,values[index]-0.01, f'{values[index]}', ha='center', va='bottom',color='C2', fontsize=8,)
bars = ax.bar(categories, values, color=colors, zorder=2)
use_font('Noto Sans CJK SC')
mplcyberpunk.add_bar_gradient(bars=bars,ax =ax )
plt.subplots_adjust(wspace=0.1,hspace=0.5)
fig.suptitle('长标签顶部错落展示', color='green',fontsize=10)
plt.show()
前后对比情况:
应用篇: 基于scikit-plot库对机器学习的结果进行可视化
scikit-plot是一个基于sklearn和Matplotlib的库(github库:https://github.com/reiinakano/scikit-plot),主要的功能是对训练好的模型进行可视化,功能比较简单易懂。包含常见机器学习各类曲线。例如P-R、KS、ROC曲线,包含有监督、无监督算法类指标曲线,便于你快速画出对应的图表。其他用法可以访问其github仓库,下面是案例展示。
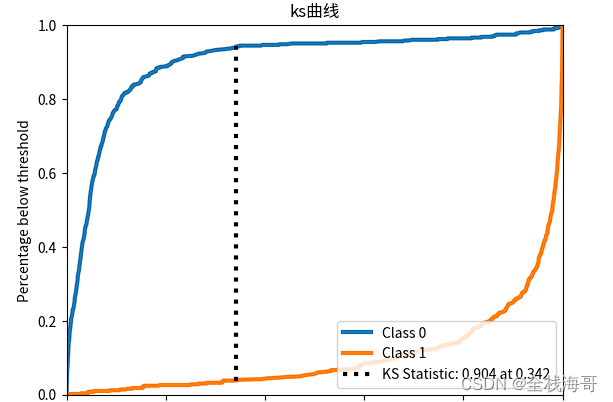
绘制ks曲线
下面是利用scikit-plot库快速绘制ks曲线,以便我们清楚的知道模型性能(区分度)。
# !pip install scikit-plot==0.3.7
import matplotlib.pyplot as plt
import scikitplot as skplt
import mpl_font.noto
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
X_train, y_train = make_classification(n_samples=1000, n_features=4,
n_informative=2, n_redundant=0,n_classes=2,
random_state=0, shuffle=False)
lr = LogisticRegression()
lr = lr.fit(X_train, y_train)
y_probas = lr.predict_proba(X_train) #(1000, 2)
skplt.metrics.plot_ks_statistic(y_train, y_probas, title='ks曲线',)
plt.show()
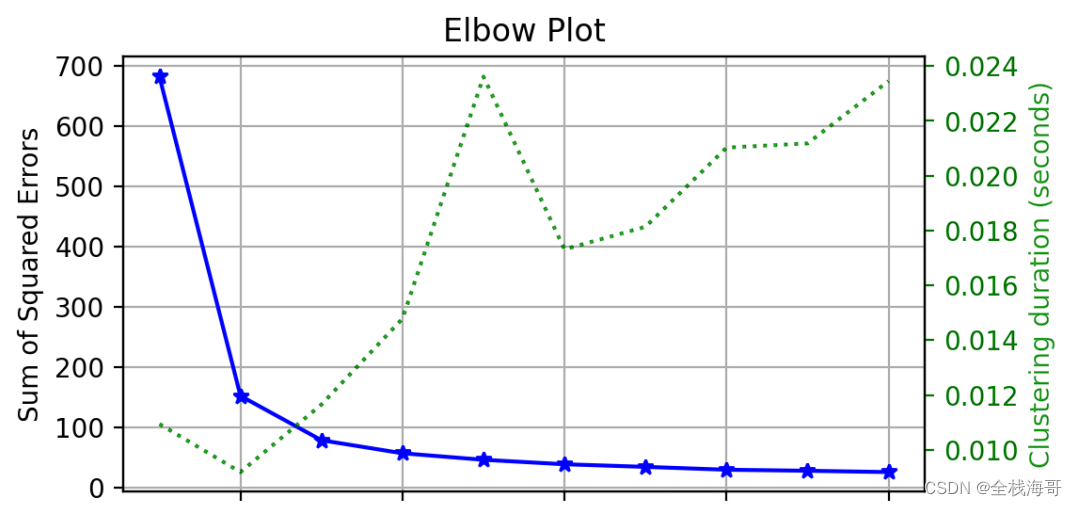
绘制聚类的elbow曲线
下面是使用scikit-plot库的plot_elbow_curve函数来快速绘制elbow聚类曲线。
import matplotlib.pyplot as plt
import scikitplot as skplt
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris as load_data
X, y = load_data(return_X_y=True)
kmeans = KMeans(random_state=1,n_init=10)
fig,ax = plt.subplots(figsize=(5.5,3),dpi=200)
skplt.cluster.plot_elbow_curve(kmeans, X, cluster_ranges=range(1, 11),ax=ax)
plt.show()
输出可视化图表:
应用篇: 基于joyplot库精美展示山脊图和多维直方图
joyplot库(其官方github: https://github.com/leotac/joypy)是一个专为Python用户设计的数据可视化工具,主要用于绘制一种名为“峰峦图”(Ridgeline Plots)或简称“Joyplot”的特殊类型的图表。这种图表类型以其独特的美学和信息传达能力而受到青睐,它通过叠加多个核密度估计曲线来展示多个变量或多个类别数据的分布情况。
-
核密度估计:Joyplot允许用户对数据进行核密度估计,并将这些估计以层叠的方式展示在同一张图上。 多组数据比较:特别适合用于对比不同组别或随时间变化的数据分布,每一条堆积的曲线代表一个特定组别的概率密度函数。
-
自定义样式:用户可以调整曲线的颜色、透明度、宽度等样式属性,以及背景、坐标轴标签、标题等视觉元素。
-
易用性:基于matplotlib和pandas构建,与这两种流行的数据处理和绘图库高度集成,方便用户直接在DataFrame上操作并快速生成图表。
-
分组可视化:通过by参数支持按照某一列分类变量进行分组,绘制各组内其他数值型变量的分布。 其他用法可以访问其github仓库。下面是案例展示
展示多维山脊图
下面是利用joyplot库来绘制山脊图,其可以展示3维的数据,并较直观的进行两两对比。
# !pip install joypy==0.2.6
import joypy
import pandas as pd
import numpy as np
import matplotlib
from matplotlib import pyplot as plt
from matplotlib import cm
from sklearn.datasets import load_iris
iris, y = load_iris(as_frame=True, return_X_y=True)
iris.columns = ["SepalLength","SepalWidth","PetalLength","PetalWidth"]
iris["Name"] = y.replace([0,1,2], ['setosa', 'versicolor', 'virginica'])
fig, axes = joypy.joyplot(iris,colormap= plt.cm.cool)
plt.cm.cool
展示多维直方图
%matplotlib inline
fig, axes = joypy.joyplot(iris, by="Name", column="SepalWidth",
hist=True, bins=20, overlap=0,
grid=True, legend=False)
应用篇: 对决策树模型进行精美可视化
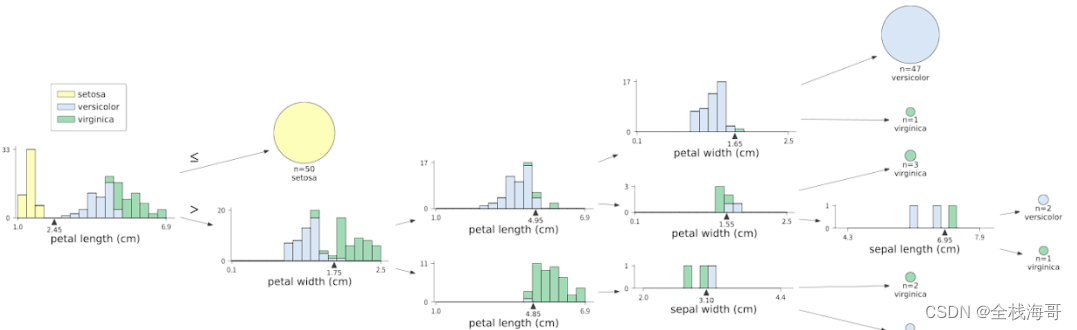
利用dtreeviz库对决策树模型可视化
树模型是机器学习常用于建模的重要算法,dtreeviz库(其github仓库:https://github.com/parrt/dtreeviz)可以直观展示出每个节点的状态。其支持普通的树模型、xgboost、lightgbm算法等等。其他用法可以访问其github仓库。下面是案例展示
!pip install dtreeviz==1.3.2 scikit-learn==1.0.2 cairosvg==2.7.1
!pip install dtreeviz[xgboost]
!pip install dtreeviz[pyspark]
!pip install dtreeviz[lightgbm]
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
from dtreeviz.trees import dtreeviz
from PIL import Image
import cairosvg
import numpy as np
clf = DecisionTreeClassifier(max_depth=5) # limit depth of tree
iris = load_iris()
clf.fit(iris.data, iris.target)
from mplfonts.util.manage import use_font
fontname='Noto Sans CJK SC'
use_font(fontname)
viz = dtreeviz(clf,
iris['data'],
iris['target'],
target_name='',
feature_names=np.array(iris['feature_names']),
class_names={0: 'setosa', 1: 'versicolor', 2: 'virginica'}, scale=1.5,
orientation='LR'
# ,fontname= fontname
) # ('TD', 'LR')
viz.save("demo.svg")
cairosvg.svg2png(url="demo.svg", write_to="demo.png", dpi=600)
img = Image.open("demo.png")
使用pybaobabat库展示
pybaobabdt 是一个基于 Python 的决策树(Decision Tree)和随机森林(Random Forest)可视化工具。下面是其案例展示。相关资料可以参考:https://pypi.org/project/pybaobabdt/
!pip install pybaobabdt==1.0.1 pygraphviz==1.12
import pybaobabdt
from matplotlib.colors import ListedColormap
ax = pybaobabdt.drawTree(clf,
size=10,
dpi=100,
maxdepth=6, #设置渲染的树的最大深度
colormap=ListedColormap(["#01a2d9", "gray", "#d5695d","gray"]),
features=np.array(iris['feature_names']))
应用篇: 绘制多组数据统计分布状态图
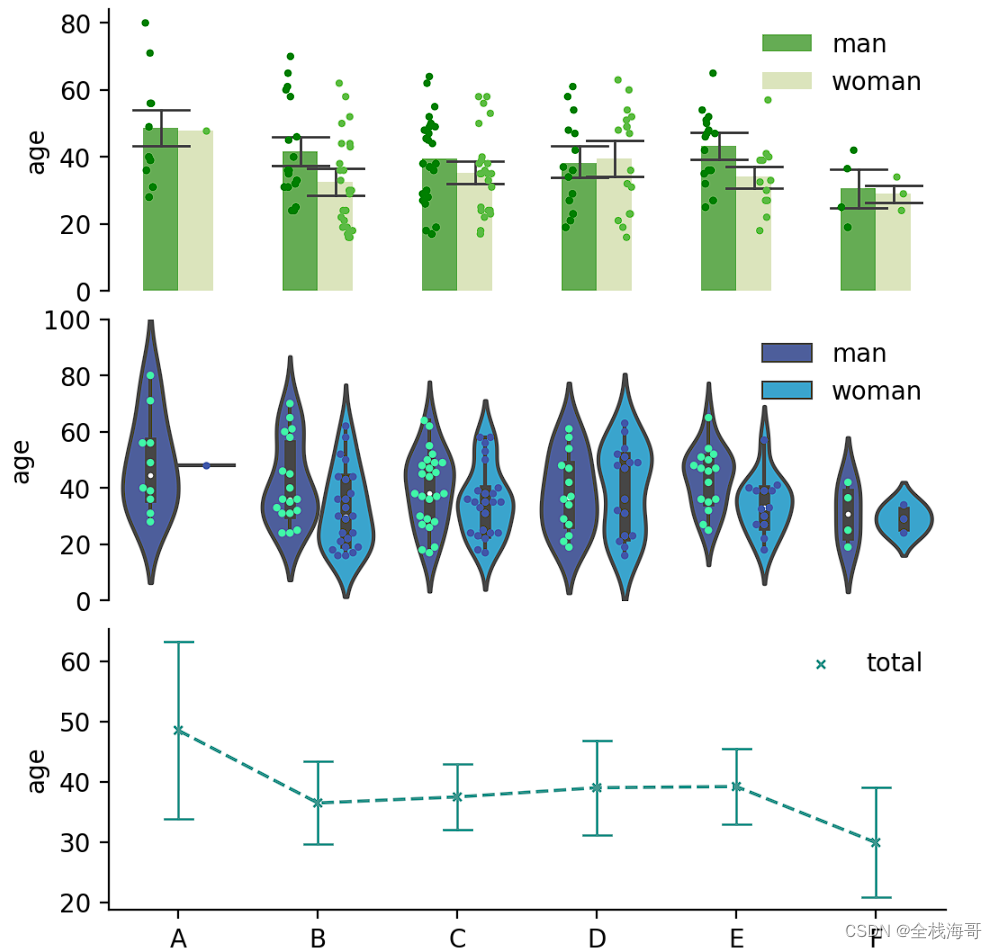
分组统计柱状图使用seaborn库快速实现分组统计柱状图
我还发现一个宝藏网站:http://shiny.chemgrid.org/boxplotr/;可以在线绘制箱型图;你也可以使用seaborn库只需要少量代码既可绘制,seaborn库提供大量函数接口,可以快速进行一维、多维、分类、连续变量的数据可视化。可参考其官网文档:https://seaborn.pydata.org/tutorial.html。下面是介绍一个案例展示(由三类图组合而成)。
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import warnings
print("matplotlib:", matplotlib.__version__)
warnings.filterwarnings("ignore")
titanic = sns.load_dataset("titanic")
df = titanic[titanic['who'].isin(['man','woman'])].query("deck!='G'")
print(df.describe())
from pandas.api.types import CategoricalDtype
df['deck']=df['deck'].astype( CategoricalDtype(categories=['A','B','C','D','E','F'], ordered=True))
df['deck'].unique()
f,axes = plt.subplots(3,1, figsize=(6,6.5),dpi=200, )
ax =axes[0]
ax=sns.barplot(data=df, x="deck",
y="age", hue="who", errorbar=("ci", 85),estimator=np.mean,
palette=['#5CBB45','#DEEBB5'],
capsize=.2,
width=0.5, #设置柱状图的宽度
errwidth=1,
ax=ax,orient='v',) #estimator=np.mean, ci=85,
sns.stripplot(data=df, x="deck",
y="age",hue="who",dodge=True,jitter=True, ax=ax,
palette=['green','#5CBB45'],size=3,orient='v',legend=False)
h, l = ax.get_legend_handles_labels()
ax.legend(h, ['man','woman'],ncol=1,frameon=False,loc='upper right')
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.axes.xaxis.set_visible(False)
ax =axes[1]
sns.violinplot(data=df, x="deck",hue="who",palette=['#4057A8','#22AFE5'],
y="age",dodge=True, ax=ax,orient='v',legend=False)
ax=sns.swarmplot(data=df, x="deck",hue="who",size=3,palette=['#40F7A8','#4057A8'],
y="age",dodge=True, ax=ax,orient='v',legend=False)
h, l = ax.get_legend_handles_labels()
ax.legend(h, ['man','woman'],ncol=1,frameon=False,loc='upper right')
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.axes.xaxis.set_visible(False)
ax.set_yticks([20*i for i in range(6)])
ax.set_yticklabels([20*i for i in range(6)])
ax =axes[2]
ax=sns.pointplot(data=df, x="deck", y="age", orient='v',dodge=True,
markers= "x",linestyles= "--",errwidth=1,
errorbar=("se",3 ), capsize=.2, scale=0.5, ax=ax,color='#43978F',join=True,label='total') #['#43978F','#ABD0F1']
h, l = ax.get_legend_handles_labels()
ax.legend(h, ['total'],ncol=1,frameon=False,loc='upper right')
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
plt.subplots_adjust(hspace=0.1)
plt.show()
可视化结果:
基于seaborn的箱型图&&散点图&&分布显著性检验
下面是基于测试数据绘制对应的效果图,可根据自己的实际数据进行绘制。
import matplotlib as mpl
from matplotlib.font_manager import FontProperties
from matplotlib.ticker import FormatStrFormatter
from matplotlib.ticker import MaxNLocator
import mplcyberpunk
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(2024)
import seaborn as sns
import numpy as np
import pandas as pd
from scipy.stats import ttest_ind
df = pd.DataFrame({
'group': np.repeat( ['type_A', 'type_B', 'type_C'], 100),
'value': (np.random.randn(100 * len(['type_A', 'type_B', 'type_C'])) * 20) + 10
})
df.loc[df['group'] == 'type_A', 'value'] += 10
df.loc[df['group'] == 'type_B', 'value'] += 2
df.loc[df['group'] == 'type_C', 'value'] += 20
groups = ['type_A', 'type_B', 'type_C']
linewidth=3
alpha=0.8
fig, ax = plt.subplots(figsize=(8, 6),dpi=150)
palette=[(139/255, 144/255, 206/255),(214/255, 214/255,155/255), (187/255,236/255,218/255)]
# 绘制完整的小提琴
violin_parts = sns.violinplot(x='group', y='value', data=df, split=True, inner=None,palette=palette)
# 平移小提琴
shift = -0.2
for vp in violin_parts.collections[::1]:
for path in vp.get_paths():
vertices = path.vertices
vertices[:, 0] = np.clip(vertices[:, 0], -np.inf, np.median(vertices[:, 0])) #只展示小提琴的左边
#vertices[:, 0] = np.clip(vertices[:, 0], np.median(vertices[:, 0]), np.inf) #只展示小提琴的右边
vertices[:, 0] += shift
sns.boxplot(x='group', y='value', data=df, width=0.3, fliersize=0, linewidth=1.5,
boxprops={'edgecolor': 'black'}, palette=palette, showcaps=True, whiskerprops={'linewidth':1.5},
capprops={'linewidth':1.5}, medianprops={'color':'black'})
mean_values = df.groupby('group')['value'].mean().values
sns.stripplot(x='group', y='value', data=df, jitter=True, size=4, color=".3", linewidth=0)
ax.axhline(y=67.2, linestyle='--', color=(194/255,127/255, 159/255), linewidth=1)
ax.text(2.2, 69.2, f'极大值:67.2', ha='center', va='bottom', color=(194/255,127/255, 159/255))
y, h, col = df['value'].max()+5, 5, 'k'
# 进行单边t检验&&绘制对应的效果
pairs = [('type_A', 'type_B'), ('type_B', 'type_C'), ('type_A', 'type_C')]
for i, (group1, group2) in enumerate(pairs):
group1_values = df[df['group'] == group1]['value']
group2_values = df[df['group'] == group2]['value']
_, p_value = ttest_ind(group1_values, group2_values)
x1, x2 = groups.index(group1), groups.index(group2)
ax.plot([x1, x1, x2, x2], [y + (h*i), y + h + (h*i), y + h + (h*i), y + (h*i)], lw=1.2, c=col)
ax.text((x1+x2)*.5, y+h+(h*i), f'p值:{p_value:.3f}', ha='center', va='bottom', color=col)
y += h
ax.set_ylim(-45, y+h+15)
ax.set_title('多组数据对比分布展示图',y=1.01)
ax.set_xlim(-0.7,2.4)
ax.set_xlabel('不同类型')
ax.set_ylabel('指标')
fig.tight_layout()
plt.show()
可视化结果: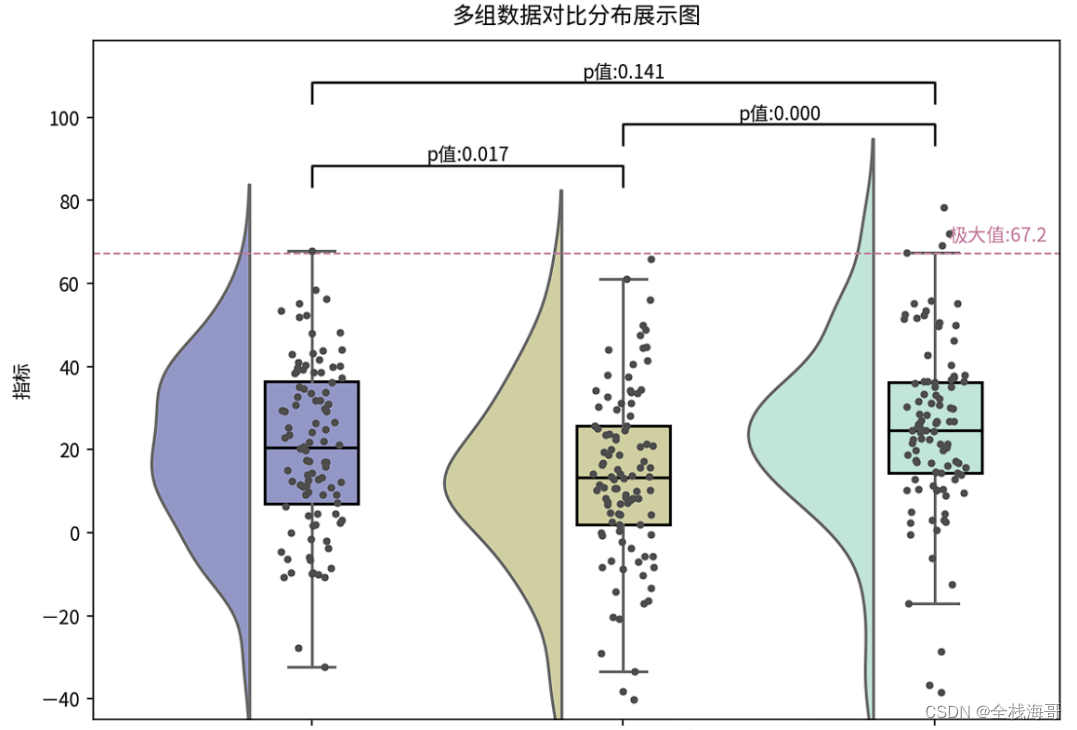
可以看出,该图表不仅可以直观展示2类型对应的分布情况,还可以展示不同类型直接的显著性情况分布,直观明了。
实战篇: 精美可视化案例绘制
热力图:利用biokit库绘制精美热力图
当你需要展示二维数据的整体变化趋势时,你可以使用biokit库(https://github.com/biokit/biokit)来进行可视化展示,下面是一个案例分享;
# !pip install biokit==0.5.0
import pandas as pd
import numpy as np
from biokit.viz import corrplot
fig = plt.figure(figsize=(6,4),dpi=200)
fig.subplots_adjust(left=0.1, wspace=0.06, hspace=0.06)
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(223)
ax4 = fig.add_subplot(224)
df = pd.DataFrame(dict(( (k, np.random.random(10)+ord(k)-65) for k in ['A','B','C','D','E','F','G'])))
df = df.corr()
c = corrplot.Corrplot(df)
c.plot(fig=fig, ax=ax1, colorbar=True,method='circle', shrink=.9,lower='circle', label_color='red'
,cmap='cool')
c.plot(fig=fig, ax=ax2, colorbar=True, cmap='crest',method='square', shrink=.9 ,rotation=45)
c.plot(fig=fig, ax=ax3, colorbar=False, cmap='copper', method='text',)
c.plot(fig=fig, ax=ax4, colorbar=True, method='pie')
plt.show()
滑珠图: 绘制滑珠图展示不同产品2个阶段的对比
import pandas as pd
import seaborn as sns
import numpy as np
import mpl_font.noto
import matplotlib.pyplot as plt
import warnings
np.random.seed(2024)
df = pd.DataFrame({'2019':[42,21,53,16,23,10,20,65,16,34,13,25,18,25,14,26]})
df['Product'] = ['A_%d'%i for i in range(16)]
df['2020'] = df['2019'].apply(lambda x:x +30+ int(10*np.random.random()) )
df.loc[7,'2020']= 30
fig,ax = plt.subplots(figsize=(6,6),dpi=120,facecolor='white',edgecolor='white')
ax.set_facecolor('white')
#绘制线
ax.hlines(y=df.index+.03, xmin=df['2019'], xmax=df['2020'], color="k", lw=1)
#添加线标记
for i,v1,v2 in zip(df.index,df['2019'],df['2020']):
if v2>v1:
ax.text((v1+v2)/2,i+0.05,s="+%d"%(v2-v1),size=10,color='#ED1A1F',ha='left',va='bottom',fontweight='bold')
else:
ax.text((v1+v2)/2,i+0.05,s=v2-v1,size=10,color='#5CBB45',ha='left',va='bottom',fontweight='bold')
#绘制type_A散点
for i,j,text in zip(df.index,df['2019'],df['2019']):
ax.scatter(j,i,s=30,color='k')
#绘制type_B散点
for i,j,text in zip(df.index,df['2020'],df['2020']):
ax.scatter(j,i+.03,s=30,color='blue')
ax.set_xlim(left=-10,right=140)
#绘制竖线
ax.plot([0,0],[0,15],color='k',lw=1)
#绘制竖线上散点
for i in df.index:
ax.scatter(0,i,color='#172A3A',ec='k',s=2,zorder=3)
for index,i in enumerate(zip(df.index,df['2020'],df['Product'])):
if i[1] > 0 :
ax.text(0-1,index,i[2],color='#3D71A0',size=8,ha='right',va='center')
else:
ax.text(i[1]-1,index,i[2],color='#3D71A0',size=8,ha='right',va='center')
ax.axis('off')
#添加图例
ax.scatter([],[],marker='o', label='2019',color="k")
ax.scatter([],[],marker='o', label='2020',color="blue")
ax.legend(loc='best',frameon=False,markerscale=1.2,ncol=1,prop={'size':8,},columnspacing=.5)
ax.invert_yaxis()
ax.set_title("不同产品在2019年~2020年销售额变化情况(滑珠图)")
可视化结果:
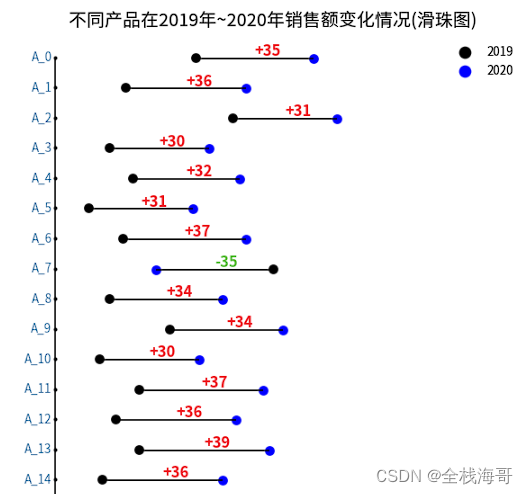
多图布局:基于patchworklib库进行多个图表布局
在matplotlib中进行可视化,可以使用patchworklib库(https://github.com/ponnhide/patchworklib)对多个图进行丝滑的排列布局。这个库的灵感来自于 ggplot2 的patchwork。因此,作为原始拼凑,用户可以轻松地仅使用/和|对齐 matplotlib 图。具体可参考官网的github仓库。下面是案例展示
# !pip install patchworklib==0.6.0
import warnings
warnings.filterwarnings("ignore")
import seaborn as sns
import patchworklib as pw
pw.overwrite_axisgrid() #When you use pw.load_seagorngrid, 'overwrite_axisgrid' should be executed
import matplotlib.pyplot as plt
penguins = sns.load_dataset("penguins")
ax1= sns.jointplot(data=penguins, x="bill_length_mm", y="bill_depth_mm", hue="species",palette=['#EA8379','#7DAEE0','#B395BD'])
# ax.ax_marg_x,ax.ax_marg_y,ax.ax_joint
h, l= ax1.ax_joint.get_legend_handles_labels()
ax1.ax_joint.legend(h,l,loc='upper center',frameon=False,markerscale=1,ncol=3,prop={'size':10,},columnspacing=.5,)
# ax1.ax_marg_x.set_title("demo")
ax2=sns.jointplot(data=penguins, x="bill_length_mm", y="bill_depth_mm", kind="reg")
ax3 = sns.jointplot(data=penguins, x="bill_length_mm", y="bill_depth_mm")
ax3.plot_joint(sns.kdeplot, color="r", zorder=0, levels=6)
ax3.plot_marginals(sns.rugplot, color="r", height=-.15, clip_on=False)
g1 = pw.load_seaborngrid(ax1,figsize=(6,6),)
g2 = pw.load_seaborngrid(ax2)
g3 = pw.load_seaborngrid(ax3)
((g2.outline|g3.outline)|g1).savefig()
词云图:利用WordCloud库来展示精美词云展示
利用WordCloud库来绘制词云,下面是效果图。
from os import path
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
wc = WordCloud(background_color="white",# 设置背景颜色
max_words=2000, # 词云显示最大词数
mask=alice_mask,# 设置背景图片
stopwords=stopwords, # 设置停用词
font_path=font_path, # 兼容中文字体,不然中文会显示乱码
)
# 生成词云
wc.generate(text)
# 生成的词云图像保存到本地
wc.to_file(path.join(d, "demo.png"))
# 显示图像
plt.imshow(wc, interpolation='bilinear')
# interpolation='bilinear' 表示插值方法为双线性插值
plt.axis("off")# 关掉图像的坐标
plt.show()

交互式图表: 利用pyecharts绘制可交互的图表
pyecharts库(官方github仓库:https://github.com/pyecharts/pyecharts)是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。注意可视化需要网络畅通。如果对这个库的可视化风格有兴趣,可以关注其对应的github 仓库,里面有对应的一首详细教程。 例如:下图是双柱状图的展示效果。
-- pyecharts: 1.9.0
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Faker
chart = (
Bar()
.add_xaxis(Faker.choose())
.add_yaxis("商品A", Faker.values(),itemstyle_opts=opts.ItemStyleOpts(color="#00CD96"))
.add_yaxis("商品B", Faker.values(), is_selected=False,itemstyle_opts=opts.ItemStyleOpts(color="#00CD00"))#默认商品B为未选中状态
.set_global_opts(title_opts=opts.TitleOpts(title="柱状图中设置标记"))
.set_series_opts(
label_opts=opts.LabelOpts(is_show=False),
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="max"),
opts.MarkPointItem(type_="min", name="min"),
opts.MarkPointItem(type_="average", name="avg"),
]
),
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_="min", name="min"),
opts.MarkLineItem(type_="max", name="max"),
opts.MarkLineItem(type_="average", name="avg"),
opts.MarkLineItem(y=99, name="自定义标记线") # 自定义标记线
]
),
)
)
chart.render_notebook()
多种度量分组展示: 绘制多图直观展示不同的度量指标当临当维度较多时候(对应的业务含义较多时),不能简单的用常见的二维图表展示(叠加柱状图、折线图;例如类型-度量值等等),应该采取分组进行度量展示,下面是该案例对应的python代码。
import matplotlib as mpl
from matplotlib.font_manager import FontProperties
from matplotlib.ticker import FormatStrFormatter
from matplotlib.ticker import MaxNLocator
import mplcyberpunk
import matplotlib.pyplot as plt
from mplfonts.util.manage import use_font
use_font('Noto Sans CJK SC')
with plt.style.context("cyberpunk"):
fig,axes = plt.subplots(3,1,figsize=(5,5),dpi=120)
axes[0].axes.xaxis.set_visible(False)
axes[0].axes.yaxis.set_visible(False)
axes[1].axes.xaxis.set_visible(False)
axes[1].axes.yaxis.set_visible(False)
axes[2].axes.yaxis.set_visible(False)
categories = ['成都', '重庆', '上海', '西安', '南京']
colors =[(139/255, 144/255, 206/255),(214/255, 214/255,155/255), (187/255,236/255,218/255),
(217/255,190/255,170/255),(177/255, 168/255, 117/255)]
#可视化第一个指标
y1= [13000,5600,34567,34512,2200]
marksize_list=[20,10,60,60,5]
use_font('Noto Sans CJK SC')
for i in range(5):
z1 =axes[0].scatter(i,0.4, edgecolor='black',color='#D9D9D9', s=40+marksize_list[i], zorder=5)
axes[0].text(i,0.41, f'{y1[i]}', ha='center', va='top', color=colors[i])
#可视化第二个指标
y2 = [0.3512,0.3235,0.2523, 0.5634, 0.1335]
out, = axes[1].plot(categories,y2, marker='^',color='gray')
for index, col in enumerate(colors):
axes[1].text(index,y2[index]+0.1, f'{y2[index]*100:.02f}%', ha='center', va='top', color=col)
#可视化第三个指标
y3 = [25, 67, 19, 45, 10]
bars = axes[2].bar(categories, y3, color=colors, zorder=2,label='销售额')
axes[2].bar_label(bars)
use_font('Noto Sans CJK SC')
mplcyberpunk.add_bar_gradient(bars=bars,ax=axes[2])
axes[2].grid()
plt.subplots_adjust()
axes[0].legend([z1,out,bars],['交易量(W)','销售额占比','销售额'],fontsize=10,ncol=3,loc='best',)
axes[0].set_title("不同地区销售额分布情况统计")
plt.show()
可视化结果:
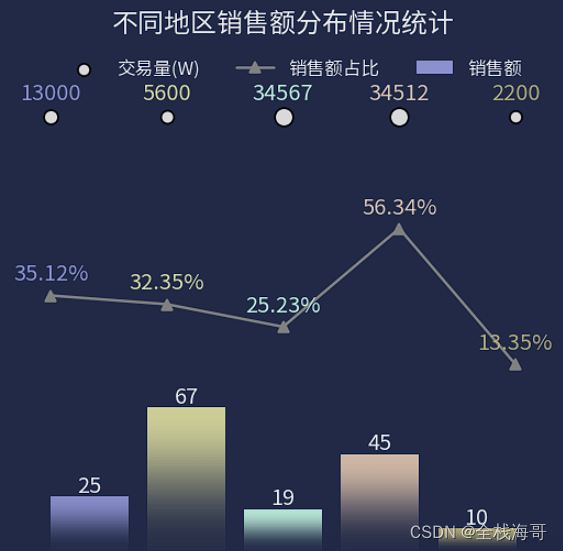
可以看出,当指标对应的度量值不在同一量级时,分开展示可以直观看出各个指标的差异。
参考文档
-
https://github.com/koho/mpl-font
-
https://github.com/matplotlib/matplotlib
-
https://github.com/Clarmy/mplfonts
-
https://github.com/dhaitz/mplcyberpunk
-
https://github.com/reiinakano/scikit-plot
-
https://github.com/leotac/joypy
-
https://github.com/parrt/dtreeviz
-
https://ieeexplore.ieee.org/document/6102453
-
https://pypi.org/project/pybaobabdt/
-
https://github.com/pandas-dev/pandas
-
http://shiny.chemgrid.org/boxplotr/
-
https://github.com/mwaskom/seaborn
-
https://github.com/biokit/biokit
-
https://github.com/ponnhide/patchworklib
-
https://github.com/pyecharts/pyecharts


















 834
834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









