







1.显著性检测与语义分割
《Joint Learning of Saliency Detection and Weakly Supervised Semantic Segmentation》

第一阶段:SSNet-1:使用image-level的语义分割数据集和pixel-level的显著性数据集训练。
SN: segmentation network
SAM:saliency aggregation module
GAP:global average pooling

第二阶段:
用第一阶段训练好的SSNet-1,预测只有image-level标签的分类数据集中的每一张图像的中间C+1响应图,并将其C个类别的分割图与image-level的one-hot 标签相乘,这样抑制了噪声,只保留标签对应的类别的响应图。然后通过CRF进一步修正。最后,根据类别和背景响应图,为每个图像的每个像素指定一个类别(即argmax取最大),得到分割任务的伪标签。
将伪标签作为Ground Truth,进一步训练SSNet-2。
2. 显著性检测结合image caption
《CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detection》

1.Image Captioning Network (ICN)
CNN+LSTM结构,生成caption, 同时得到相应feature CEV,送入LGPN模块(LPM+GPM)
2.Local Perception Module(LPM)
使用mask-rcnn实现该模块。通过Region Proposal Network(RPN) 产生一系列候选框(bounding box)后接两个分支分别用于bounding box的识别和对应物体分割mask的生成。
根据bounding box 中的类别概率与设置好的固定阈值比较,确定显著候选物体,将这些物体的mask统一映射到原始图片的对应位置,得到local perception salience Sl.
3.Global Perception Module(GPM)
生成全局显著图Sg.
4.Fusion Module(FM)
Union Guided Attention mechanism (UGA), 即Sl, Sg相加,得到Su, 作为spatial attention map, 与global feature GF相乘,得到注意力机制后的feature,然后将该feature 与Sl, Sg concate一起,得到最终salience map S.
overall loss:
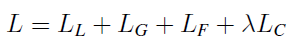
LL 为LPM模块损失,与mask-rcnn定义相同,LG 为GPM模块交叉熵损失,度量Sg与Ground Truth 差异, LF为最终salience map S与Ground Truth 的交叉熵损失, LC为ICN模块损失,定义与SAT模型(Show, attend and tell: Neural image caption generation with visual attention. Computer Science, pages 2048–2057, 2015.)相同。
在inference 阶段,该模型可为每一个输入图片同时产生caption 和 salience map。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









