







Why CNN
首先回答这样一个问题,为什么我们要学CNN,或者说CNN为什么在很多领域收获成功?还是先拿MNIST来当例子说。MNIST数据结构不清楚的话自行百度。。
我自己实验用两个hidden layer的DNN(全连接深度神经网络)在MNIST上也能取得不错的成绩(98.29%)。下面是一个三个hidden layer的网络结构图

图1
全连接深度神经网络,顾名思义,每个神经元都与相邻层的神经元连接。在这个实验中,每个数字的image是2828,也就是784(=2828)个数值,每个数值对应一个像素值,值的大小反应像素点的强度。这就意味着我们网络的输入层有784个神经元。输出层呢?由于我们是预测0-9这几个数字,输出层当然就是10个神经元了。至于隐藏层节点的个数我们可以自行选定,本实验中选的是500.
我们想想为什么DNN在训练后能够正确地分类?那肯定是它学到了东西,学到什么东西呢?它学到了图片中的某些空间结构,不同数字它们的空间结构肯定是不一样的,而这样的空间结构就是由像素点与像素点之间的关系形成。我们再仔细看DNN输入层和第一个隐藏层,发现它对我们输入的784个像素点是同等对待的,也就是说它此时并没有考虑像素点与像素点之间的关系。有没有一个好点的模型能够考虑到这点呢?那就是CNN
CNN有三个几本思想,局部感受野(local receptive fields) 权值共享(shared weights) 池化(pooling)
局部感受野(local receptive fields)
刚刚我们在DNN中是把输入层784个神经元排成了一条长线,这里我们还原图片原来的样子(28*28),如下图
强迫症的同学就不要数每行每列几个了,我已经数过了是28了。。偷笑

图2
DNN中,我们会把输入层的每个神经元都与第一个隐藏层的每个神经元连接(看看盗图1)。而在CNN中我们这样做的,第一个隐藏层的神经元只与局部区域输入层的神经元相连。下图就是第一个隐藏层的某个神经元与局部区域输入层的神经元相连的情况。

图3
这里的局部区域就是局部感受野,它像一个架在输入层上的窗口。你可以认为某一个隐藏层的神经元学习分析了它”视野范围“(局部感受野)里的特征。图中一个隐藏层的神经元有5*5个权值参数与之对应。
我们移动这样一个窗口使它能够扫描整张图,每次移动它都会有一个不同的节点与之对应。我们从输入层左上角开始,如下

图4
然后,我们一个像素往右滑动一个像素,如下

图5
以此类推可以形成第一个隐藏层,注意我们的图片是2828的,窗口是55的,可以得到一个24*24(24=28-5+1)个神经元的隐藏层
这里我们的窗口指滑动了一个像素,通常说成一步(stride),也可以滑动多步,这里的stride也是一个超参,训练是可以根据效果调整,同样,窗口大小也是一个超参。
权值共享(Shared weights and biases)
上一节中提到一个隐藏层的神经元有55个权值参数与之对应。这里要补充下,这2424个隐藏层的神经元它们的权值和偏移值是共享的 用公式描述下
σ(b+∑l=04∑m=04wl,maj+l,k+m)
σ代表的是激活函数,如sigmoid函数等,b就是偏移值,w就是55个共享权值矩阵,我们用矩阵a表示输入层的神经元,ax,y表示第x+1行第y+1列那个神经元(注意,这里的下标默认都是从0开始计的,a0,0表示第一行第一列那个神经元)所以通过矩阵w线性mapping后再加上偏移值就得到公式中括号里的式子,表示的是隐藏层中第j+1行k+1列那个神经元的输入。有点晕的话就参照上面的图,图4就是j=k=0的情况,图5是j=0,k=1. 最后加上激活函数就表示该隐藏神经元的输出了。这部分原理和DNN是一样的,如果把w改成2828的矩阵就变成了全连接,就是DNN了。
我们能不能简化一下这个公式呢
a1=σ(b+w∗a0)
a1表示隐藏层的输出,a0表示隐藏层的输入,而∗就表示卷积操作(convolution operation) 这也正是卷积神经网络名字的由来。
由于权值共享,窗口移来移去还是同一个窗口,也就意味着第一个隐藏层所有的神经元从输入层探测(detect)到的是同一种特征(feature),只是从输入层的不同位置探测到(图片的中间,左上角,右下角等等),必须强调下,一个窗口只能学到一种特征!另外,窗口还有其他叫法:卷积核(kernal),过滤器(filter)。我们在做图像识别时光学习一个特征肯定是不够的,我们想要学习更多的特征,就需要更多的窗口。如果用三个窗口的话如下图

图6
窗口与窗口间的w和b是不共享的,三个窗口就表示有三个w矩阵和三个偏移值b,结果是从整张图片的各个位置学到三种不同的特征。到这里肯定有人会问,你说学到特征了,怎么证明学到了呀?现在我们用20个窗口来学习MNIST里的图片特征,我们只看20个窗口里的权值矩阵w,如果把这20个w画成20张黑白图,每张图片都是5*5(一个权值代表一个像素点),如下图所示

图7
盯着其中的一张看,白色区域表示权值比较小,说明窗口的这部分对输入层的神经元不敏感(responds less),相反黑色部分表示权值比较大,说明窗口的这部分对输入层的神经元敏感(responds more).每张图片都有明显的黑白区域,这也能够说明CNN确实学到一些和空间结构相关的特征。究竟学的是什么特征呢?这个很难回答清楚,此处暂不深究,更好理解的话可以参考 Visualizing and Understanding Convolutional Networks
权值共享还有一个很大的好处,就是可以大大减少模型参数的个数。我们的例子中,一个窗口参数个数是26(55+1),20个窗口就是520个参数,如果换成全连接的话就是785(2828+1)个参数,比CNN多了265个参数。可能你觉得265嘛,对计算机来说完全不算什么。如果我们是30个隐藏层的DNN的话(深度学习里很常见的),需要23550(785*30)个参数,是CNN的45倍多。。当然我们也不能光光去比较它们参数的个数,毕竟两个模型本质原理上就相差甚远,但是直觉上我们可以感受到,CNN可以依靠更少的参数来获得和DNN相同的效果,更少的参数就意味着更快的训练速度,这可是谁都想要的。
池化(Pooling)
CNN还有一个重要思想就是池化,池化层通常接在卷积层后面。池化这个词听着就很有学问,其实引入它的目的就是为了简化卷积层的输出。通俗地理解,池化层也在卷积层上架了一个窗口,但这个窗口比卷积层的窗口简单许多,不需要w,b这些参数,它只是对窗口范围内的神经元做简单的操作,如求和,求最大值,把求得的值作为池化层神经元的输入值,如下图,这是一个2*2的窗口

图8
值得注意的是,我们此时的窗口每次移动两步,采用的是求最大值的方法,所有称之为max-pooling,刚刚卷积层含有2424个神经元,经过池化后到池化层就是1212个神经元。通常卷积层的窗口是多个的,池化层的窗口也是多个的。简单来说,卷积层用一个窗口去对输入层做卷积操作,池化层也用一个窗口去对卷积层做池化操作。但是注意这两个操作的本质区别。下面来看一个用三个卷积窗口和跟随其后的池化窗口长啥样。
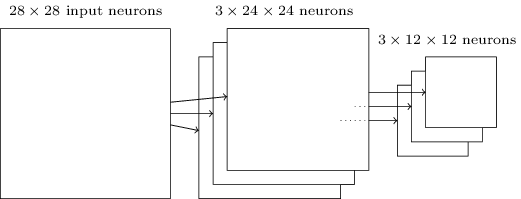
图9
怎么理解max-pooling呢?由于经过了卷积操作,模型从输入层学到的特征反映在卷积层上,max-pooling做的事就是去检测这个特征是否在窗口覆盖范围的区域内。这也导致了,它会丢失这种特征所在的精准位置信息,所幸的是池化层可以保留相对位置信息。而后者相比而言比前者更重要。不理解上面的话也没关系,但是需要记住池化层一个最大的好处:经过池化后,大大减少了我们学到的特征值,也就大大减少了后面网络层的参数(上图可以看出池化层的神经元数明显少于卷积层神经元数)。
max-pooling技术只是池化技术的一种,还有一种比较常用的是L2-pooling,与max-pooling唯一的区别就是在池化窗口扫过的区域里做的操作不是求最大值,而是所有神经元平方后求和再开根号,这和我们L2正则对权值参数的操作是一样的。实际操作中,这两种方式都是比较常用的。池化操作方式的选择也是我们调参工作的一部分,我们可以根据validation data集来调节,选择更好的池化操作。
总的来看
介绍完CNN的三个几本思想概念后我们把它串起来看下。

图10
从左往右依次是输入层,卷积层,池化层,输出层。输入层到卷积层,卷积层到池化层已经详细介绍过了。池化层到输出层是全连接,这和DNN是一样的。
整体上把我CNN的网络架构,其实和DNN很相似,都是一层一层组合起来的,层与层之间的行为也是有对应的权值w和偏移值b决定的,并且它们的目的也是一致的:通过training data来学习网络结构中的w和b,从而能把输入的图片正确分类。很简单吧。
到此为之,CNN的基本原理大致介绍完毕了,如果只需对CNN做大致了解的话上面的内容我想应该足够了。下面主要介绍下其数学原理了,想看可以去原文章看。
原文链接:https://blog.csdn.net/m0_37490039/article/details/79378143















 5086
5086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









