






记录了一些ICCV2023的新趋势与见解。
如果对其中的论文和主题感兴趣,请自行查找研究。
原文链接:ICCV 2023 top papers, general trends, and personal picks | AI Summer
理解生成学习和判别学习之间的联系
Towards understanding the connection between generative and discriminative learning
论文要点:非常令人兴奋的一个新趋势是生成模型和判别模型之间的联系。他们之间有什么共同的代表吗?
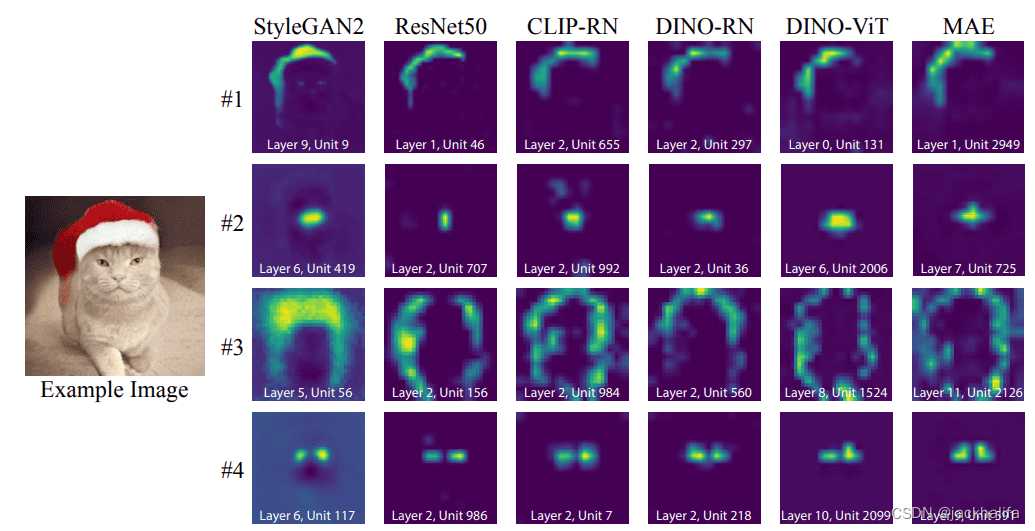
作者证明了不同模型中存在匹配神经元(rosetta neurons),这些神经元表达了共同的概念(例如对象轮廓、对象部分和颜色)。这些概念的出现没有任何监督或手动注释。
论文Rosetta Neurons:Mining the Common Units in a Model Zoo表明,用完全不同的目标预训练的完全不同的模型可以学习共享的概念(例如对象轮廓、对象部分和颜色)。这些概念的出现没有任何监督或手动注释。到目前为止,我只在 DINO 等自监督视觉变换器的自注意力图上看到了与对象相关的概念。他们进一步表明,即使对于 StyleGAN2,激活看起来也很相似。 该过程可简要描述如下:1)使用经过训练的生成模型生成图像,2)将图像输入判别模型并存储所有层的所有激活图,3)计算图像和空间维度上的皮尔逊相关性平均值,4 )找到两个模型的所有激活之间相互最近的邻居,5)对它们进行聚类。
Pre-pretraining:视觉自监督训练与自然语言监督相结合
Pre-pretraining: Combining visual self-supervised training with natural language supervision
动机:屏蔽自动编码器 (MAE) 随机屏蔽图像的 75%,并训练模型通过最小化像素重建误差来重建屏蔽的输入图像。 MAE 仅在 ImageNet 上被证明可以随模型大小缩放。
另一方面,弱监督学习(WSL)意味着自然语言监督对每个图像都有文本描述。 WSL 是监督预训练和自监督预训练之间的中间立场,其中使用文本注释,例如 CLIP。
关键思想:MAE 在分割等密集视觉任务中蓬勃发展,而 WSL 可以学习抽象特征并具有出色的零样本性能。我们能否找到一种两全其美的方法?
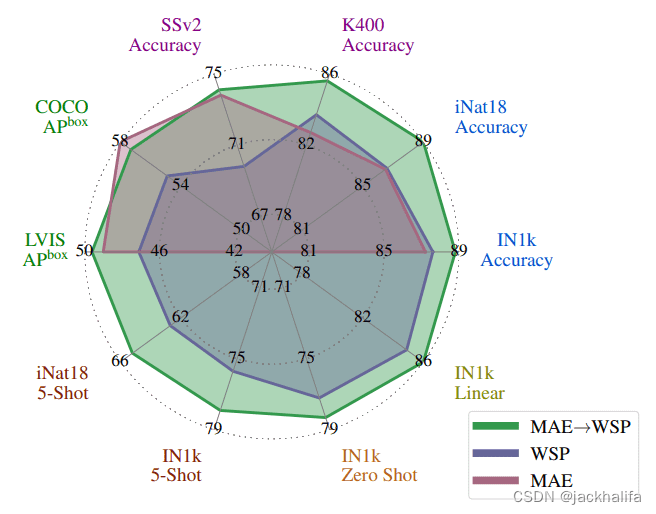
MAE 预训练可提高性能。使用自监督预训练 (MAE)、数十亿张图像的弱监督预训练 (WSP) 以及我们的预训练 (MAE --> WSP) 训练的 ViT-L 架构的传输性能,该预训练使用 MAE 初始化模型,然后进行利用WSP预训练。预训练持续提高性能。
Meta AI 在他们的工作“The effectiveness of MAE pre-pretraining for billion-scale pretraining”中表明这是可能的。
核心思想:结合 MAE 自监督(第一阶段 → 预训练)和弱监督学习(第二阶段预训练)。这种称为 MAE→WSP 的组合优于单独使用任一策略(即 MAE 模型或从头开始训练的弱监督模型)的性能。
通过重新集中注意力来调整预训练模型
Adapting a pre-trained model by refocusing its attention
由于基础性的模型是必经之路,因此寻找巧妙的方法使其适应各种下游任务是一个重要的研究途径。
加州大学伯克利分校的研究人员在他们的论文 “TOAST: Transfer Learning via Attention Steering”中表明,可以通过自上而下的注意力引导(TOAST)方法来实现这一目标。
关键思想:给定预训练的 ViT 主干,他们调整方法的附加线性层,在第一次前向传递后充当反馈路径。因此,该模型可以将注意力转移到与任务相关的特征上,如下所示,它可以超越标准微调(75.2 VS 60.2% 的准确度)。
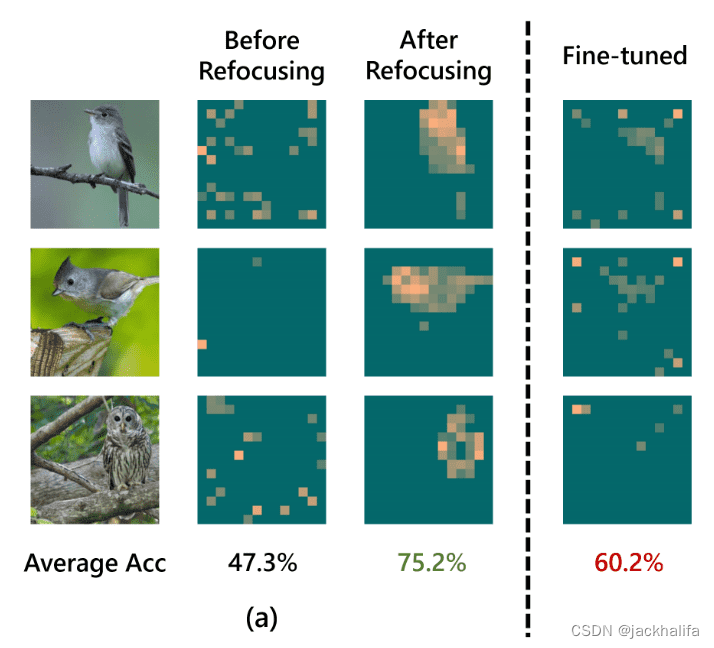
ImageNet 预训练的 ViT 用于使用不同的迁移学习算法进行下游鸟类分类。在这里,他们可视化了这些模型的注意力图。每个注意力图在 ViT 最后一层的不同头部上进行平均。
直观地说,自上而下的信号(在第一次前馈传递之后)将选择并传播每一层中与任务相关的特征,第二次前馈将能够访问这些增强的特征,从而实现更强的性能。
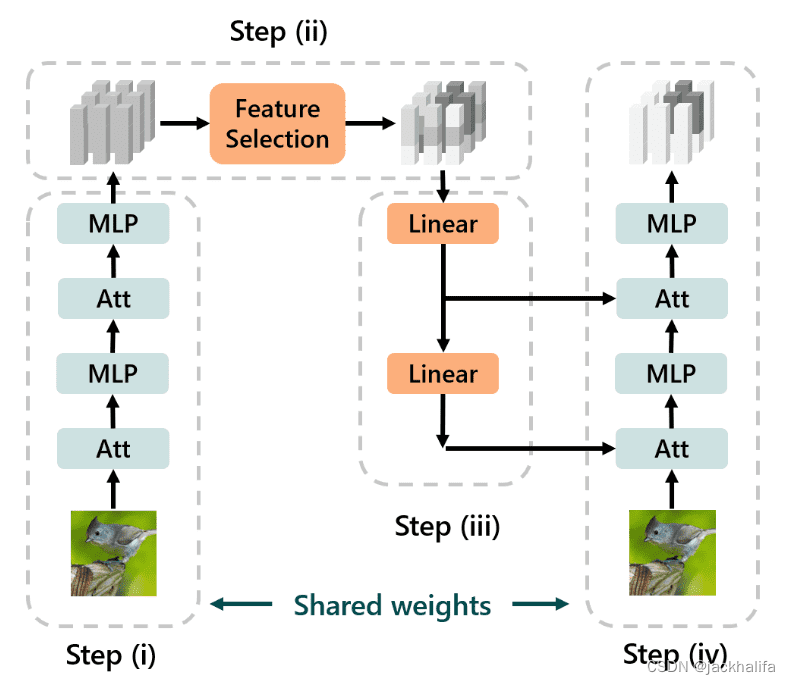
推理有四个步骤:(i)输入通过前馈Transformer,(ii)特征选择模块根据输出令牌与任务的相关性对输出令牌进行软重新加权,(iii)重新加权的令牌通过反馈发回路径,以及(iv)我们再次运行前馈传递,但每个注意力层接收额外的自上而下的输入。在传输过程中,我们只调整特征选择模块和反馈路径,并保持前馈主干冻结。
如果您有兴趣了解有关自上而下注意力的更多信息,同一小组已在CVPR中发表了类似的工作。
使用离散扩散生成模型进行图像和视频分割
Image and video segmentation using discrete diffusion generative models
谷歌 DeepMind 展示了一项有趣的工作,名为A Generalist Framework for Panoptic Segmentation of Images and Videos
关键思想:提出了一种扩散模型来对全景分割掩模进行建模,具有简单的架构和通用的损失函数。特别是对于分割,我们需要类和实例 ID,它们是离散目标。因此,使用了位扩散。
“位扩散首先将表示离散标记的整数转换为位串,然后将其位转换为可以应用连续扩散模型的实数(也称为模拟位)。为了抽取样本,位扩散使用来自连续扩散的传统采样器,之后使用最终的量化步骤(简单阈值处理)从生成的模拟位中获取分类变量。”
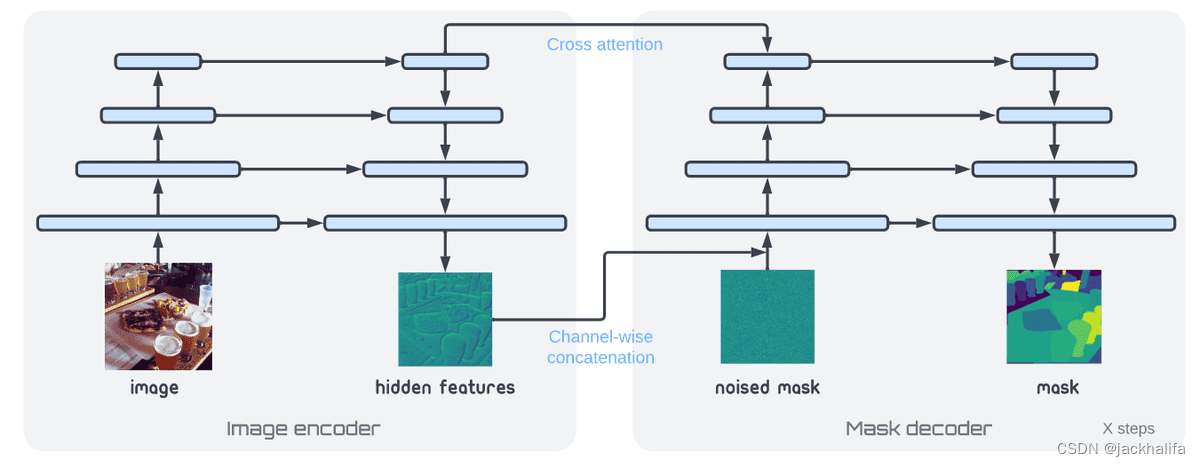 作者所提出的全景掩模生成框架的架构。他们将模型分为图像编码器和掩模解码器,以便测试时的迭代推理仅涉及解码器的多次传递。
作者所提出的全景掩模生成框架的架构。他们将模型分为图像编码器和掩模解码器,以便测试时的迭代推理仅涉及解码器的多次传递。
无条件地预训练扩散模型以产生分割掩模,然后联合训练预训练的图像编码器和扩散模型以进行条件分割。
至关重要的是,通过简单地将过去的预测添加为条件信号,我们的方法能够对视频进行建模(在流媒体设置中),从而学习自动跟踪对象实例。
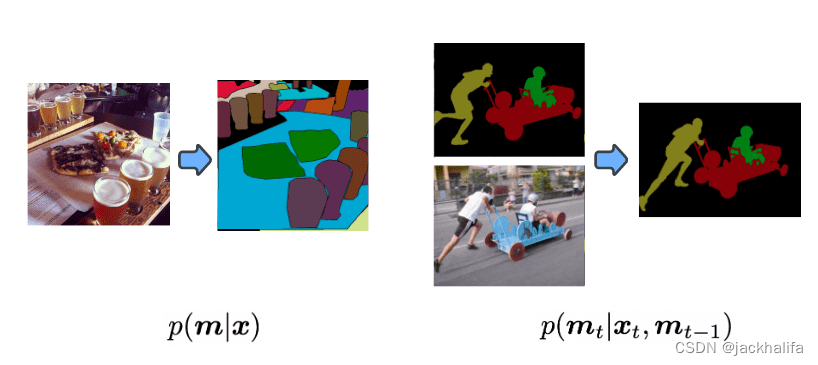
作者使用位扩散生成模型将全景分割表述为图像(左)和视频(右)的条件离散掩模 (m) 生成问题。
令人惊讶的是,它即插即用。当合并过去的条件生成时,模型会自动学习跨帧跟踪和分割实例。
这种方法的性能不如特定于任务的方法,但考虑到架构和损失函数都是与任务无关的,结果令人印象深刻。
随机分割的扩散模型
Diffusion models for stochastic segmentation
在一项最近的工作中,伯尔尼大学的研究人员在其名为Stochastic Segmentation with Conditional Categorical Diffusion Models
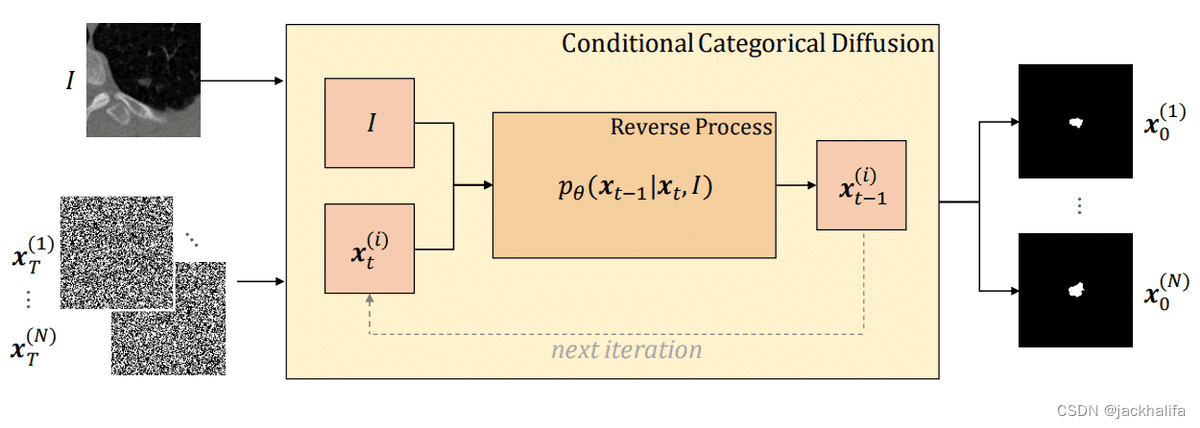
作者的方法的逆向过程的图示。条件分类扩散模型(CCDM)接收图像 I 和从分类均匀噪声中采样的分类标签图作为输入。
如果您想了解有关分类扩散的更多信息,请参阅 NeurIPS 2021 的论文演示。
扩散模型:用 Transformer 替代常用的 U-Net
Diffusion models: replacing the commonly-used U-Net with transformers
Scalable Diffusion Models with Transformers一文表明,人们可以在扩散框架内使用 Transformer,并在高达 512x512 分辨率的类条件 ImageNet 基准测试中获得具有竞争力的性能。
其背后的动机是 Transformer/ViT 具有最佳实践和扩展性能,并且已被证明比传统卷积网络(当前扩散模型中 U-net 的主要构建块)更有效地扩展视觉识别。
关键思想:简而言之,作者表明,通过在潜在扩散模型 (LDM) 框架下构建扩散变压器 (DiT) 设计空间并对其进行基准测试,其中扩散模型在 VAE 的潜在空间内进行训练,可以成功取代 带有Transformer的U-net主干网络。他们进一步表明,DiT 是扩散模型的可扩展架构:网络复杂性(以 Gflops 衡量)与样本质量(以 FID 衡量)之间存在很强的相关性。
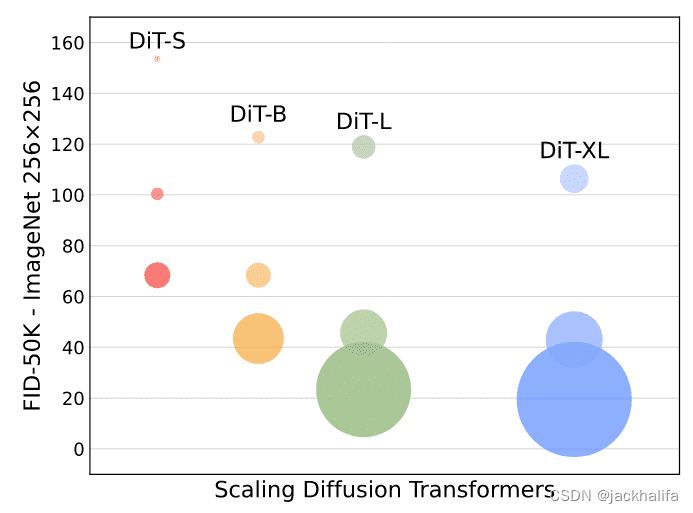
使用Diffusion Transformers (DiT) 生成 ImageNet。气泡区域表示扩散模型的flops。左:我们的 DiT 模型在 400K 次训练迭代中的 FID-50K(越低越好)。随着模型flops次数的增加,FID 的性能稳步提高。
扩散模型作为(软)MAE(Masked Autoencoders)
Diffusion Models as (Soft) Masked Autoencoders
Sander Dieleman 已经在这篇博文中讨论了扩散模型和去噪自动编码器之间的联系(排除瓶颈,并包括多个噪声级别)。
关键思想:在这个方向上,论文Diffusion Models as Masked Autoencoders提出了基于补丁的屏蔽输入的条件扩散模型。通常,噪声是在标准扩散中逐像素发生的,这可以被视为软逐像素掩蔽。
另一方面,屏蔽自动编码器接收屏蔽像素,这是一种硬屏蔽,因为像素被简单地归零。通过将这两者结合起来,作者将扩散模型制定为掩码自动编码器(DiffMAE)

DiffMAE 的推理过程,从随机高斯噪声迭代展开到采样输出。在训练过程中,模型学习对不同噪声级别(从顶行到底部)的输入进行降噪,并同时执行下游识别的自监督预训练。
编码的特征可以作为微调下游任务的初始化,并产生最先进的视频分类精度。值得注意的是,解码器比 MAE 更大,将使用一些额外的交叉注意力/跳过连接。
作为自监督学习器的去噪扩散自动编码器
Denoising Diffusion Autoencoders as Self-supervised Learners
视觉表征学习正在从监督学习、自然语言弱监督学习或自监督学习等各个不同方向进行改进。从现在开始使用扩散模型!
在与 Diffusion-MAE 类似的研究方向中,论文Denoising Diffusion Autoencoders are Unified Self-supervised Learners发现,即使是标准的无条件扩散模型也可以用于类似于自监督模型的表示学习。
关键思想:更具体地说,通过对无条件图像生成的预训练,扩散模型已经在其中间层中捕获了线性可分离表示,而无需进行修改。
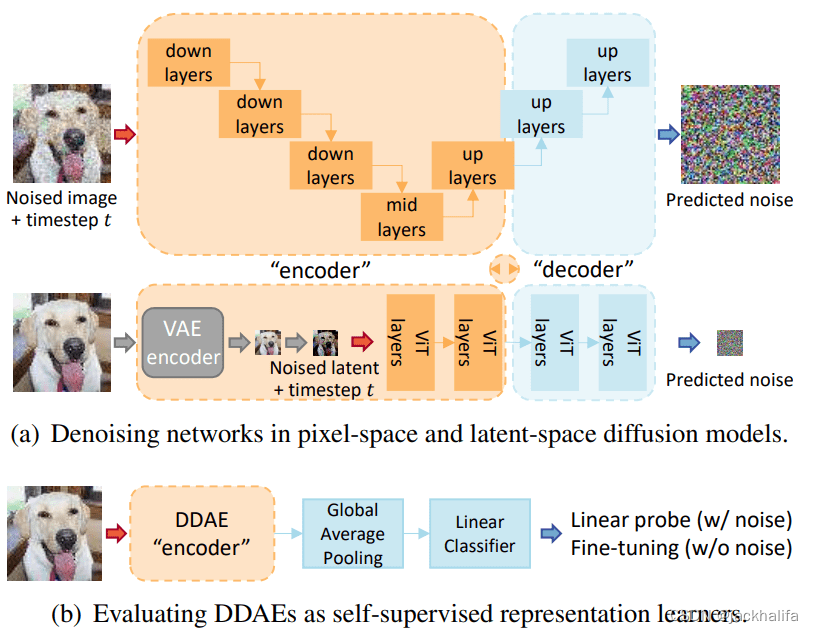
降噪扩散自动编码器(DDAE)。上图:扩散网络本质上等同于水平条件去噪自动编码器(DAE)。由于这种相似性,这些网络被命名为 DDAE。底部:通过线性探针评估,我们确认 DDAE 可以在某些中间层产生强表示。将 DDAE 作为视觉编码器进行截断和微调可进一步实现卓越的图像分类性能。
这项工作很重要,因为它统一了以前不相关的生成学习和判别学习领域。这种方法的局限性和重要因素是特征质量很大程度上取决于层深度和噪声尺度。 例如,在 CIFAR-10 上,当图像受到小噪声干扰时,最佳特征位于 Unet 解码的中间。 作者指出,训练扩散模型的成本极其高昂,而判别性表示学习的最佳实践(例如 BYOL、DINO)可能会激发进步,从而扩大扩散模型的训练规模。
最大限度地利用 DINO 注意力掩码
Leveraging DINO attention masks to the maximum
这项工作令人惊叹,因为它使用自监督方法 DINO 的注意力掩模来执行零样本无监督对象检测,甚至实例分割!
核心思想:他们提出了一个名为 Cut-and-LEaRn (CutLER) 的简单框架。他们利用自监督模型的特性在没有监督的情况下“发现”对象(在他们的注意力图中)。他们对这些掩模进行后处理,以训练最先进的本地化模型,而无需任何人工标签。后处理基于称为归一化图切割的经典计算机视觉算法,它似乎会生成非常好的掩模。
归一化切割(NCut)将图像分割问题视为图分区任务。我们通过将每个图像表示为一个节点来构造一个完全连接的无向图。每对节点通过带有权重 Wij 的边连接,该权重衡量所连接节点的相似性。
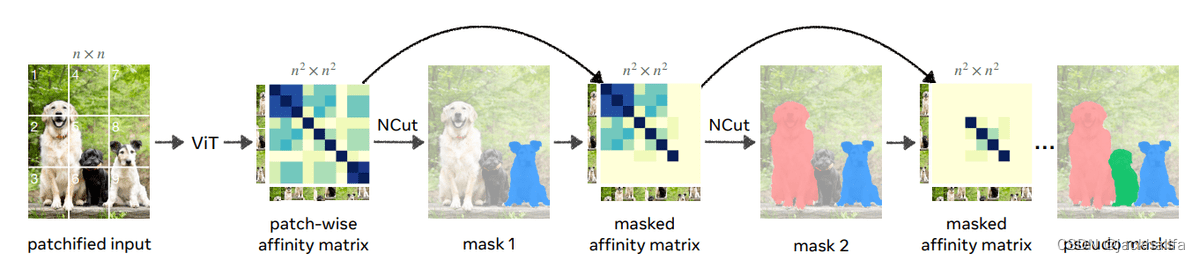
上图说明如何在没有监督的情况下发现图像中的多个对象蒙版。作者在之前的工作基础上,使用自监督 DINO 模型的特征为图像创建了一个补丁相似度矩阵。随后,他们对该矩阵应用归一化剪切并获得图像的单个前景对象蒙版。然后,他们使用前景蒙版屏蔽掉亲和力矩阵值并重复该过程,这使得算法能够在单个图像中发现多个对象蒙版。在此管道图中,此过程重复 3 次。
然后使用这些掩模训练检测器,同时自训练进一步提高性能。
图像生成学习:我们不能比 FID 做得更好吗?
Generative learning on images: can’t we do better than FID?
在生成模型替代评估的方向上,我非常喜欢HRS-Bench: Holistic, Reliable and Scalable Benchmark for Text-to-Image Models论文中的方法以及其他现有的方法,主要基于 CLIP,并且仅适用用于文本条件图像生成。
关键思想:使用 CLIP(下图中的 Image Captioner 模型 G(I))通过文本到文本对齐来测量图像质量(保真度)。
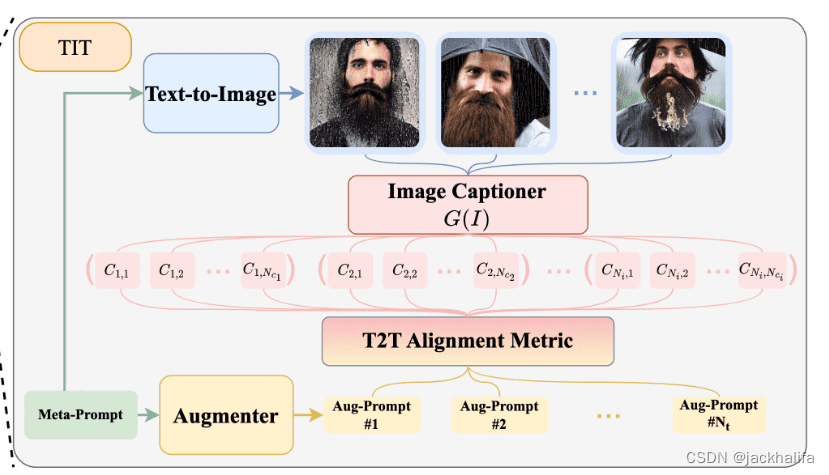
使用 CLIP 和文本到文本相似性/对齐来替代 FID 的示例。
文本到文本分数的示例包括 CIDEr 和 BLEU,它们在 NLP 文献中已得到广泛认可。我期待更多关于这个方向和针对不同类型条件的论文。
该论文对生成模型有更多的评估。
META 的 AI 瑰宝:ImageBind 和 DINOv2
META’s AI gems: ImageBind and DINOv2
注意:尽管 ImageBind 和 DINOv2 没有被 ICCV 接受,但它们还是在 Meta AI 的展位上展示了,并在会议的一周内得到了热烈的讨论。
Meta AI 在其论文ImageBind: One Embedding Space To Bind Them All中构建了一个名为 ImageBind 的开源框架,这是第一个将来自六种不同模式的信息汇集在单个嵌入空间中的人工智能模型。
关键思想:该模型学习文本、图像、音频、深度 (3D)、热(红外辐射)和惯性测量单元 (IMU) 的单个嵌入或共享表示空间。 ImageBind 创建跨多种模态的联合嵌入空间,无需使用每种不同模态组合对数据进行训练。
如何?简短的回答:使用Transformer和对比学习目标函数。
共享的嵌入形状可以实现多模态检索,这是一个令人惊叹的新工具。例如,我们可以在共享特征空间中检索在特征空间中与照片在语义上接近的声音。想象一下,您有一张带有波浪的大海的图像,并且您可以检索类似的声音,例如波浪的声音。或者甚至从深度传感器等获取 3D 形状。
传统上,每种各自的模态都有一个特定的嵌入(即,可以表示机器学习中的数据及其关系的数字向量),在这种情况下称为专家。正如我们的论文中所述,ImageBind 可以超越之前针对一种特定模式单独训练的专业模型,并且可以结合不同形式的信息。
DINOv2:数据管理对于自我监督学习 + 扩大 DINO/iBOT 很重要
DINOv2: Data curation matters for self-supervised learning + scaling up DINO/iBOT
核心思想:DINOv2 建立在另一个名为 iBOT 的框架之上,该框架将来自不同增强视图的交叉熵与掩模语言建模相结合。他们本质上找到了如何加快训练速度并扩展到更大的批量大小。
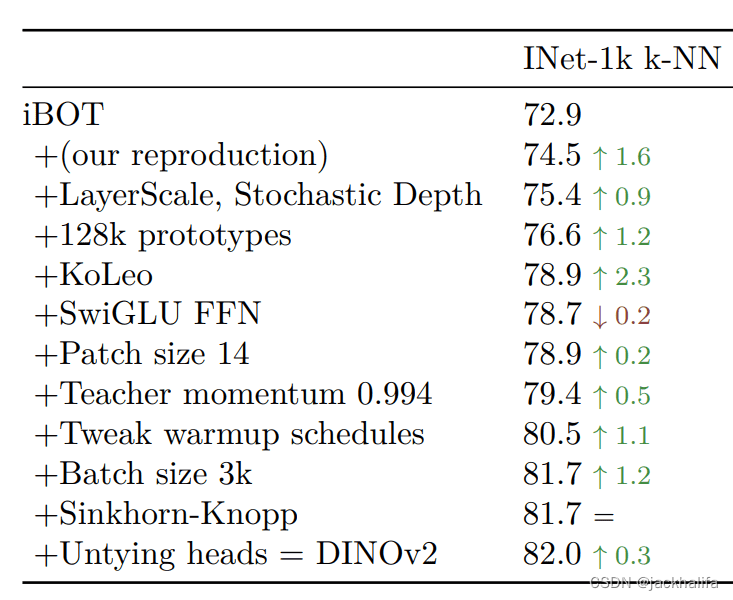
使用 iBOT 作为基线,对 ImageNet-22k 上的 ViT-Large 架构进行消融研究。作者选择k-NN分类性能来优化性能。
第二个轴围绕着整理一组未标记的图像以进行自我监督学习。这是通过在使用 DINOv2 在 ImageNet-22K 上预训练的大型 ViT 模型的特征空间上进行 k 均值聚类(+采样)或使用简单的 k 最近邻 (NN) 检索来实现的。
ICCV2023 值得注意的十篇文章
1.Sigmoid Loss for Language Image Pre-Training: CLIP 中使用的对比目标的替代方案,通过避免 softmax 归一化来进行较大批量的大规模预训练。作者提出了一种用于图像文本预训练的简单成对 sigmoid 损失。新的基于 sigmoid 的损失仅对图像-文本对进行操作,并且不需要对成对相似性进行归一化的全局视图。
2.Distilling Large Vision-Language Model with Out-of-Distribution Generalizability:本文研究了从视觉语言模型(教师)到小数据集上的轻量级学生模型的蒸馏,包括开放词汇表外分布(OOD)泛化。贡献:(i) 将教师和学生之间的对比蒸馏 (InfoNCE) 损失与均方误差 (MSE) 的另一个修改版本相结合,看起来像L=softmax(MSE(teacher(x),student(x)))为了更好的视觉对齐(ii),通过基于信息和细粒度语义文本的属性来丰富教师的语言表示,以有效地区分不同的标签。
3.Keep It SimPool: Who Said Supervised Transformers Suffer from Attention Deficit?: 一种简单的基于注意力的池化机制,替代适用于监督和自监督学习方法的卷积和 Transformer 编码器的默认机制。 SimPool 提高了预训练和下游任务的性能,并提供了在所有情况下描绘对象边界的高质量注意力图。
4.Unified Visual Relationship Detection with Vision and Language Models:这项工作的重点是训练单个视觉关系检测器(利用视觉和语言模型进行统一视觉关系检测)来预测来自多个数据集的标签空间的并集。它解决了使用对象对之间的二阶视觉语义合并来自不同数据集的标签的问题。
5.An Empirical Investigation of Pre-trained Model Selection for Out-of-Distribution Generalization and Calibration强调针对分布外泛化的预训练模型选择的重要性。经过 Imagenet 训练的监督 ConvNeXt 通常优于其他考虑的模型。分布内泛化和 OOD 泛化之间的相关性并不总是遵循线性增加模式,数据集的选择对其影响很大。
6.Discovering prototypes for dataset comparison: 允许通过简单地查看属于最常学习的原型的图像来比较数据集。方法:在 2 个(或更多)数据集的串联上使用 DINO,旨在研究学习到的原型。通过在训练后挑选最常用的集群,人们可以识别属于数据集之一或可以共享相似语义概念的数据集或数据集之一。
7.Understanding the Feature Norm for Out-of-Distribution Detection: 提出使用特征范数乘以稀疏度作为通用度量,该度量可以与 k-NN 距离相结合,通过 ResNets/CNN 进行最先进的 OOD 检测。
8.Benchmarking Low-Shot Robustness to Natural Distribution Shifts: 1)自监督 ViT 在 ID 和 OOD 变化上通常比 CNN 和监督对应物表现更好,但没有单一的初始化或模型大小在跨数据集上效果更好。 2) ImageNet 监督的 ViT 在 OOD 偏移方面显着优于 ImageNet-21k 监督的 ViT。 3)现有的鲁棒性干预方法可能无法提高除ImageNet之外的数据集的鲁棒性。
9.Distilling from Similar Tasks for Transfer Learning on a Budget: 通过使用任务相似性度量来估计每个源模型与特定目标任务的一致性,从一组源模型中找到每个预训练视觉基础模型的标量权重 w 。为此,他们假设有一小组标记数据可用。所提出的任务相似性度量独立于特征维度,因此它们可以利用任何架构的模型。根据计算出的每个模型权重w,我们可以选择最好的一个来蒸馏由 w 加权的这些模型的组合。
10.Leveraging Visual Attention for out-of-distribution Detection: 一种新的分布外检测方法,涉及训练卷积自动编码器来重建由预训练的 ViT 分类器生成的注意力热图,从而实现准确的图像重建和有效的 OOD 检测。
总结
以下是一些个人观点和总结:
扩散模型似乎是非常有前途的候选者,其用途不仅仅是根据提示生成艺术图片。
视觉自监督学习和自然语言监督(弱监督学习)似乎都很有用,并且预计有更多方法将它们结合起来而不是进行比较。
生成问题似乎仍然是一个未解决的问题,而可能需要新的数据集和基准。
基础/预训练模型是首选方法,从头开始的方法似乎很少见,但非常有价值。 以最少的计算和不同的分布来调整下游任务的预训练模型似乎是另一个关键研究方向。
目前尚不清楚为什么像 DINO ViT 这样的自监督模型的注意力会产生信息掩模,而监督模型需要特定的机制或注意力引导方法。















 266
266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









