






一. R-CNN(2014年)
1. 简介
RCNN是利用深度学习进行目标检测的开山之作,相对于传统典型的Haar特征+Adaboost,Hog特征+SVM等算法准确率有了很大的提升,将PASCAL VOC 2007数据集的检测准确率从35.1%提升到了66%(mAP)
2. 流程
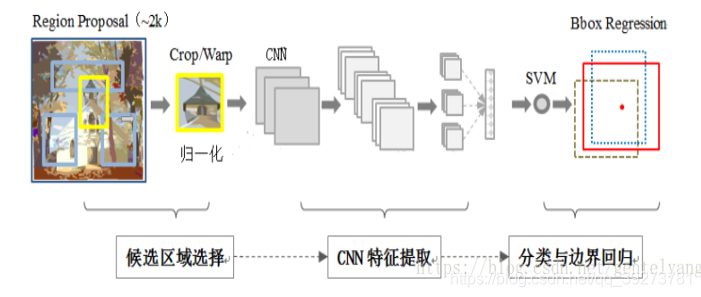
(1)候选区域选择 区域建议Region Proposal是一种传统的区域提取方法,基于启发式的区域提取方法,用的方法是SS(Selective Search),提取2000个候选框左右,然后再对提取的大小不同的候选框进行大小归一化(2272273),归一化后准备输入到预训练好的CNN网络
(2)CNN特征提取 R-CNN论文中使用的是AlexNet,训练数据集为ImageNet,采用预训练的方式,将最后的全连接层由4096->1000改为了4096->21的全连接层,代表输出的21维类别标号,其中20类目标类和一个背景类 训练过程中在PASCAL VOC数据集上对预训练好的CNN做微调,然后使用SS方法提取候选框,再用微调后的CNN网络提取候选区域特征并保存起来,训练SVM分类器
(3)分类与边界回归 有两个子步骤,一个是对前一步的输出向量进行分类(分类器需要根据特征进行训练); 第二种是通过边界回归框回归(缩写为bbox)获得精确的区域信息。其目的是准确定位和合并完成分类的预期目标,并避免多重检测,最后通过非极大值抑制(Non-maximum suppression)输出结果
3. 缺点
(1)训练步骤繁琐(微调网络+训练SVM+训练bbox)
(2)训练,测试速度都很慢,需要提取出每一个候选框再提取特征(3)训练占用空间大,提取出的特征和分类器都需要占用额外空间
4. 改进点
相对于传统检测算法,首次采用深度网络进行特征提取
5. 扩展
选择性搜索(Selective Search)通过基于图的图像分割方法初始化原始区域,就是将图像分割成很多很多的小块。然后使用贪心策略,计算每两个相邻的区域的相似度,然后每次合并最相似的两块,直到最终只剩下一块完整的图片。然后这其中每次产生的图像块包括合并的图像块我们都保存下来,这样就得到图像的分层表示了,然后再对每次合并的块打分,这样就可以根据分数筛选出需要个数的候选区域
二.Fast R-CNN(2015年)
1. 简介
同样使用大规模深度网络,Fast-RCNN和R-CNN相比,训练时间从84小时减少为9.5小时,一张图像的测试时间从47秒减少为0.32秒(不包括SS时间)。在PASCAL VOC 2007上的准确率相差不大,约在66.9%,主要优化了R-CNN在速度方面的缺陷
2. 流程
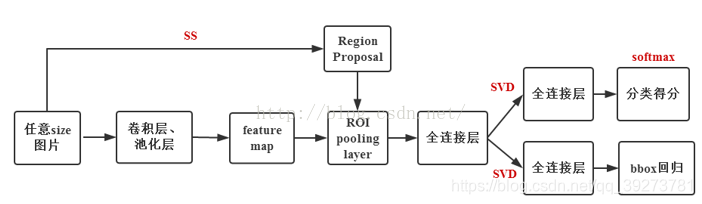
(1)测试过程
寻找一个在imagenet上训练过的预训练cnn模型(论文中用VGG16),用SS方法提取图片的2000个proposal并保存,将原图归一化后的图片输入到已经训练好的CNN 网络,在ROI pooling Layer的地方,对每一个proposal,提取到其对应的ROI,对每一个ROI, 将其划分成固定大小的网格,并且在每一个小网格中,对该网格做最大池化,得到固定大小的feture map,并将其输入到后续的fc层,最后一层输出21类别相关信息和4个bounding box的修正偏移量,对bounding box 按照上述得到的位置偏移量进行修正,再根据nms对所有的proposal进行筛选,即可得到对该张图片的bounding box预测值以及每个bounding box对应的类和score
(2)训练过程
对训练集中所有的图片,用SS提取出各图片对应的2000个proposal并保存, 对每张图片,根据图片中bounding box的ground truth信息,给该图片的2000个proposal赋类标签,并保存。(这2000个proposal,如果跟ground truth中的proposal的IoU值超过了阈值(IOU>=0.5),则把ground truth中的proposal对应的类标签赋给原始产生的这个proposal,其余的proposal(IOU [0.1, 0.5))都标为background),使用batch size=128,25%来自有非背景标签的proposal,其余来自标记为背景的proposal(最开始的理解:具体在这个过程中,mini-batch有两个层次,一个是对于同一张图片,64个proposal组成的mini-batch,另一个是完成单张图片的导数计算后,两张图片是一个mini-batch,更新的时候对两张图片求得的值取平均来更新权重),其实,就是ROI pooling layer以前,batch size=2,ROI pooling layer之后,batch size=128,训练CNN,最后一层的结果包含类信息和位置修正信息,所以用多任务的loss,一个是分类的损失函数,一个是位置的损失函数
3. 缺点
(1)依旧用SS提取RP(SS耗时2-3s,特征提取耗时0.32s)
(2)无法满足实时应用,没有真正实现端到端训练测试
(3)利用了GPU,但是区域建议方法是在CPU上实现的
4. 改进点
(1) Fast-RCNN在训练的时候,把整张图片送入CNN网络进行提取特征,不需要像R-CNN那样对每一个候选区域进行输入CNN,从而在CNN的利用上提高了很大的效率
(2) 训练速度相应提升,不需要SVM分类器对提取后的特征进行存储数据,把图片的特征和候选区域直接送入loss,不需要对硬盘进行读写的操作
(3) 对网络的利用效率,用于分类和回归调整的功能都用CNN网络来实现,不需要额外的分类器和回归器
5. 扩展
ROI pooling layer是根据输入image,将ROI映射到feature map对应位置,将映射后的区域划分为相同大小的sections,对每个sections进行max pooling操作,这样就可以从不同大小的候选框得到固定大小的feature maps
三.Faster R-CNN(2015年)
1. 简介
Faster R-CNN设计了提取候选区域的网络RPN,代替了费时的SS方法,将特征提取、proposal提取、Bounding Box Regression、Classification整合到一个网络中,使得检测速度大幅提升,一张图像的测试时间从2秒减少为0.2秒(前者包括SS时间),在PASCAL VOC 2007上的准确率基本相同,为66.9%
2. 流程
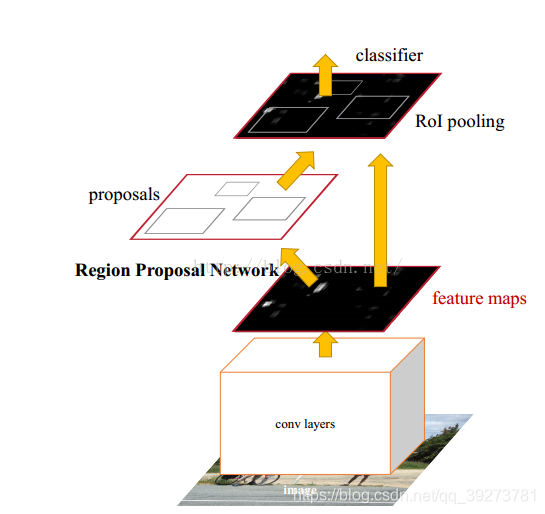
(1)Faster R-CNN和Fast R-CNN相同首先使用CNN网络提取候选图像的特征图,该特征图被共享用于后续RPN(Region Proposal Network)层和全连接(fully connection)层中
(2)RPN网络用于生成区域候选图像块,该层通过softmax判断锚点(anchors)属于前景(foreground)或者背景(background),再利用边界框回归(bounding box regression)修正anchors获得精确的proposals
(3)目标区池化(Roi Pooling),该层收集输入的特征图和候选的目标区域,综合这些信息后提取目标区域的特征图,送入后续全连接层判定目标类别
(4)利用目标区域特征图计算目标区域的类别,同时再次边界框回归获得检测框最终的精确位置
3. 缺点
(1)还是无法达到实时检测目标
(2)获取region proposal,再对每个proposal分类计算量还是比较大
4. 改进点
Faster R-CNN最大的亮点在于提出了一种有效定位目标区域的方法,然后按区域在特征图上进行特征索引,大大降低了卷积计算的时间消耗,所以速度上有了非常大的提升
5. 扩展
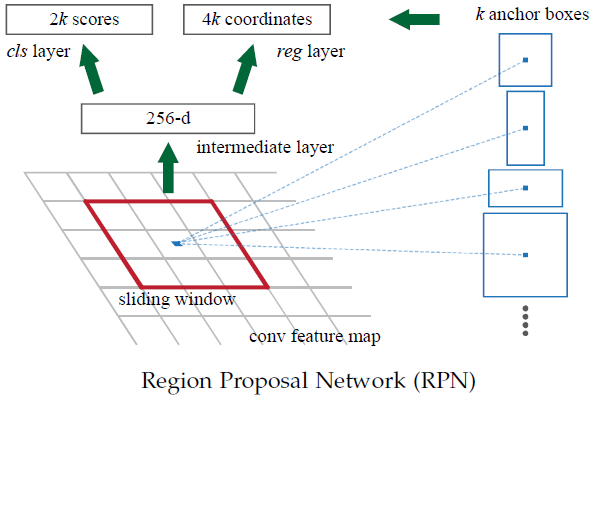
RPN网络由ZF网络的前5层得到特征图,在输入到RPN网络中,在特征图上滑动窗口,神经网络用于物体分类+框位置的回归,滑动窗口的位置提供了物体的大体位置信息,框的回归提供了框更精确的位置
四.Mask R-CNN(2017)
1. 简介
Mask RCNN可以看做是一个通用实例分割架构,Mask RCNN以Faster RCNN原型,增加了一个分支用于分割任务,Mask RCNN比Faster RCNN速度慢一些,达到了5fps,可用于人的姿态估计等其他任务
2. 流程
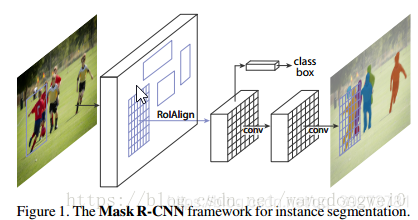
(1)首先,输入一幅你想处理的图片,然后进行对应的预处理操作,或者预处理后的图片
(2)然后,将其输入到一个预训练好的神经网络中(ResNeXt等)获得对应的feature map
(3)接着,对这个feature map中的每一点设定预定个的ROI,从而获得多个候选ROI
(4)接着,将这些候选的ROI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的ROI
(5)接着,对这些剩下的ROI进行ROIAlign操作(即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来)部分候选的ROI
(6)最后,对这些ROI进行分类(N类别分类)、BBox回归和MASK生成(在每一个ROI里面进行FCN操作)
3. 改进点
(1)分析了ROI Pool的不足,提升了ROIAlign,提升了检测和实例分割的效果
(2)将实例分割分解为分类和mask生成两个分支,依赖于分类分支所预测的类别标签来选择输出对应的mask。同时利用Binary Loss代替Multinomial Loss,消除了不同类别的mask之间的竞争,生成了准确的二值mask
(3)并行进行分类和mask生成任务,对模型进行了加速
五.Cascade R-CNN(2018)
1. 简介
深入研究了目标检测中的IoU阈值选取问题,并通过大量的实验分析验证了IoU阈值选取对检测器性能的影响,基于对以上问题的分析,提出了级联版的Faster R-CNN,也即Cascade R-CNN目标检测算法,在不使用任何trick的情况下,在MS COCO通用目标检测数据集上展现了非常出色的性能
5. 流程
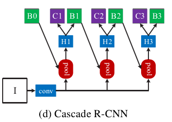
(1)前半部分和Faster R-CNN结构相同,只是在尾部添加了级联结构
(2)选用的级联结构共有多个stages, IoU阈值分别设定为递进的0.5/0.6/0.7,大于该阈值的选为正样本,其余均为负样本
5. 改进点
改进了目标检测中长期以来无人问津但非常重要的问题——IoU阈值选取问题,是极具启发性的一篇工作,结合传统方法中的cascade思想和当前主流的Faster R-CNN检测框架,将two-stage方法在现有数据集上将检测性能又提升到了一个新高度

















 2982
2982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









