









本学期选修了一门CVPR课程,最后的大作业要求结合自身的专业进行一次物体识别的作业。我的专业是电气工程,因此选择了航拍图像中的绝缘子故障识别问题。
基于FCOS的航拍巡检图像绝缘子识别
引言
应用背景
高压线路输电距离长,沿线的自然环境多样,地理环境复杂,输电线路易在恶劣环境中受到损害。如果监控不到位,发生故障无法及时处理,必将导致重大事故发生,严重威胁和影响电力系统的正常稳定运行,甚至造成系统大规模瘫痪的严重后果。对输电线路进行定期巡视检查是保证电力系统稳定运行的重要前提。绝缘子类型多、数量大、分布广,是高压输电线路中重要的组成部分,在巡检过程中,输电线路上的绝缘子是重要的检测目标. 人工巡检效率低下、危险系数高、检测结果不稳定,难以满足日常监控巡检要求,应用无人机巡检在一定程度上提高了电力巡检的效率。但绝缘子的航拍图像在训练前期筛选十分繁琐,且受拍摄条件制约,使绝缘子在整幅图像中占比小,导致人工判别强度大、效率低。在电网智能巡检的大背景下,伴随着图像处理和深度学习的不断发展,利用深度学习技术对绝缘子进行自动定位和检测成为趋势[1]。
技术背景
目标检测是指找出图像中所有感兴趣的目标(物体),确定它们的位置和大小,是计算机视觉的核心领域之一。基于深度学习的目标检测技术包括anchor-based和anchor-free两大类[2]。
经过R-CNN和Fast RCNN的积淀,Ross B. Girshick在2016年提出了新的Faster RCNN算法。随后2016年12月北卡大学教堂山分校的Wei Liu等提出SSD算法,将YOLO的回归思想和Faster R-CNN的anchor box机制结合。目前主流的目标检测算法,包括多阶段的各种RCNN和单阶段的SSD、RetinaNet上都是基于Anchor来做的。Anchor的本质是候选框,在设计了不同尺度和比例的候选框后,DNN学习如何将这些候选框进行分类:是否包含object和包含什么类别的object,对于postive的anchor会学习如何将其回归到正确的位置。它扮演的角色和传统检测算法中的滑动窗口等机制比较类似。此后anchor-based方法成为目标检测SOTA算法的常客,使用anchor机制产生密集的anchor box,使得网络可直接在此基础上进行目标分类及边界框坐标回归;密集的anchor box也可有效提高网络目标召回能力。但是anchor-based方法需要较强的先验知识,冗余框较多也会造成正负样本的不平衡。且网络实质上是看不见anchor box的,在anchor box的基础上进行边界回归更像是一种在范围比较小时候的强行记忆[3]。
anchor-free方法最早可追溯到YOLO,其用将目标区域预测和目标类别预测整合于单个神经网络模型中,理解上更加直觉。anchor-free方法主要分为基于密集预测和基于关键点估计两种。Densebox是地平线的算法工程师黄李超于2015年设计的一个端到端检测框架,它在overFeat方法的基础上,设计了一套端到端的多任务全卷积模型该模型可以直接回归出目标出现的置信度和相对位置。CornerNet则开创了另一条主线,提出了“Objects as points”的想法,CornerNet是后来很多基于关键点估计处理目标检测的算法基础,它开创性地用一对角点来检测目标。对一幅图像,预测两组heatmap,一组为top-left角点,另一组为bottom-right角点,每组heatmap有类别个通道[4]。
近两年来,anchor-free算法与anchor-based算法之间的差距被不断的减小,2019年的FCOS(Fully Convolutional One-Stage Object Detection)更是取得了SOTA的成就。事实上,anchor-based和anchor-free并不是完全独立的两类算法,其存在很多联系。Shifeng Zhang提出了ATSS算法,认为label assign问题是物体检测方法之间的差别[5]。
方法
整体框架
FCOS[6]是一个一阶段目标检测算法,它的网络结构可以分为backbone、Feature Pyramid、Detection Head三个部分。Backbone用于提取图像的底层特征,其中
C
3
,
C
4
,
C
5
C_3,C_4,C_5
C3,C4,C5表示三个不同的特征图。Feature Pyramid用于融合多个特征图,加强网络对小目标的识别能力,其中
P
3
,
P
4
,
P
5
,
P
6
,
P
7
P_3,P_4,P_5,P_6,P_7
P3,P4,P5,P6,P7表示不同的金字塔特征。Detection Head则利用小的卷积层对融合后的特征进一步处理,并同时得到物体的分类、Center-ness和边界回归信息。
 令
F
i
∈
R
H
×
W
×
C
F_i\in\mathbf{R}^{H\times W\times C}
Fi∈RH×W×C为第
i
i
i层特征图,预测的真实框为
{
B
i
}
\{ B_i \}
{Bi},其中
B
i
=
(
x
0
i
,
y
0
i
,
x
1
i
,
y
1
i
,
c
i
)
∈
R
4
×
{
1
,
2
,
.
.
.
,
C
}
B_i=(x_0^i,y_0^i,x_1^i,y_1^i,c^i)\in\mathbf{R}^4\times\{1,2,...,C\}
Bi=(x0i,y0i,x1i,y1i,ci)∈R4×{1,2,...,C}。这里的
(
x
0
i
,
y
0
i
)
(x_0^i,y_0^i)
(x0i,y0i)与
(
x
1
i
,
y
1
i
)
(x_1^i,y_1^i)
(x1i,y1i)分别表示bounding box的左上和右下角,
c
i
c^i
ci则表示物体的类别,
C
C
C为物体类别的总数。特征图上的坐标
(
x
,
y
)
(x,y)
(x,y)映射为原图上则为
(
⌊
s
2
+
x
s
⌋
,
⌊
s
2
+
y
s
⌋
)
(\lfloor\frac{s}{2}+xs\rfloor, \lfloor\frac{s}{2}+ys\rfloor)
(⌊2s+xs⌋,⌊2s+ys⌋)。当位置
(
x
,
y
)
(x,y)
(x,y)落入任何真实框,它的参数
c
∗
c^*
c∗则为真实框的对应类;否则
c
∗
=
0
c^*=0
c∗=0为背景。此外向量
t
∗
=
(
l
∗
,
t
∗
,
r
∗
,
b
∗
)
\boldsymbol{t}^*=(l^*,t^*,r^*,b^*)
t∗=(l∗,t∗,r∗,b∗)为中心点到四个方向边框的距离,也即
令
F
i
∈
R
H
×
W
×
C
F_i\in\mathbf{R}^{H\times W\times C}
Fi∈RH×W×C为第
i
i
i层特征图,预测的真实框为
{
B
i
}
\{ B_i \}
{Bi},其中
B
i
=
(
x
0
i
,
y
0
i
,
x
1
i
,
y
1
i
,
c
i
)
∈
R
4
×
{
1
,
2
,
.
.
.
,
C
}
B_i=(x_0^i,y_0^i,x_1^i,y_1^i,c^i)\in\mathbf{R}^4\times\{1,2,...,C\}
Bi=(x0i,y0i,x1i,y1i,ci)∈R4×{1,2,...,C}。这里的
(
x
0
i
,
y
0
i
)
(x_0^i,y_0^i)
(x0i,y0i)与
(
x
1
i
,
y
1
i
)
(x_1^i,y_1^i)
(x1i,y1i)分别表示bounding box的左上和右下角,
c
i
c^i
ci则表示物体的类别,
C
C
C为物体类别的总数。特征图上的坐标
(
x
,
y
)
(x,y)
(x,y)映射为原图上则为
(
⌊
s
2
+
x
s
⌋
,
⌊
s
2
+
y
s
⌋
)
(\lfloor\frac{s}{2}+xs\rfloor, \lfloor\frac{s}{2}+ys\rfloor)
(⌊2s+xs⌋,⌊2s+ys⌋)。当位置
(
x
,
y
)
(x,y)
(x,y)落入任何真实框,它的参数
c
∗
c^*
c∗则为真实框的对应类;否则
c
∗
=
0
c^*=0
c∗=0为背景。此外向量
t
∗
=
(
l
∗
,
t
∗
,
r
∗
,
b
∗
)
\boldsymbol{t}^*=(l^*,t^*,r^*,b^*)
t∗=(l∗,t∗,r∗,b∗)为中心点到四个方向边框的距离,也即
l
∗
=
x
−
x
0
i
t
∗
=
y
−
y
0
i
r
∗
=
x
1
i
−
x
b
∗
=
y
1
i
−
y
\begin{aligned} l^*&=x-x_0^i \\ t^*&=y-y_0^i \\ r^*&=x_1^i-x \\ b^*&=y_1^i-y \end{aligned}
l∗t∗r∗b∗=x−x0i=y−y0i=x1i−x=y1i−y最终的损失函数为
L
(
{
p
x
,
y
}
,
{
t
x
,
y
}
)
=
1
N
p
o
s
∑
x
,
y
L
c
l
s
(
p
x
,
y
,
c
x
,
y
∗
)
+
λ
N
p
o
s
∑
x
,
y
I
(
c
x
,
y
∗
>
0
)
L
r
e
g
(
t
x
,
y
,
t
x
,
y
∗
)
\begin{aligned} \mathcal{L}(\{\boldsymbol{p}_{x,y}\}, \{ \boldsymbol{t}_{x,y} \}) &= \frac{1}{N_{\rm pos}}\sum_{x,y}\mathcal{L}_{\rm cls}(\boldsymbol{p}_{x,y},c^*_{x,y}) \\ &+\frac{\lambda}{N_{\rm pos}}\sum_{x,y}\mathbb{I}(c_{x,y^*>0})\mathcal{L}_{\rm reg}(\boldsymbol{t}_{x,y},\boldsymbol{t}^*_{x,y}) \end{aligned}
L({px,y},{tx,y})=Npos1x,y∑Lcls(px,y,cx,y∗)+Nposλx,y∑I(cx,y∗>0)Lreg(tx,y,tx,y∗)其中
L
c
l
s
\mathcal{L}_{\rm cls}
Lcls是focal loss,
L
r
e
g
\mathcal{L}_{\rm reg}
Lreg为IoU loss,
λ
\lambda
λ是一个平衡参数,
I
(
c
x
,
y
∗
>
0
)
\mathbb{I}(c_{x,y^*>0})
I(cx,y∗>0)为指示函数。
Focal Loss
Focal Loss[7]由Kaiming He提出,主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。Focal Loss在原有交叉熵函数的基础上添加了两个参数:
L
f
l
=
{
−
α
(
1
−
y
′
)
γ
log
y
′
y
=
1
−
(
1
−
α
)
y
′
γ
log
(
1
−
y
′
)
y
=
0
\mathcal{L}_{fl}=\left\{ \begin{array}{cc} -\alpha(1-y^{\prime})^{\gamma}\log{y^{\prime}} & y=1 \\ -(1-\alpha)y^{\prime\gamma}\log{(1-y^{\prime})} & y=0 \end{array} \right.
Lfl={−α(1−y′)γlogy′−(1−α)y′γlog(1−y′)y=1y=0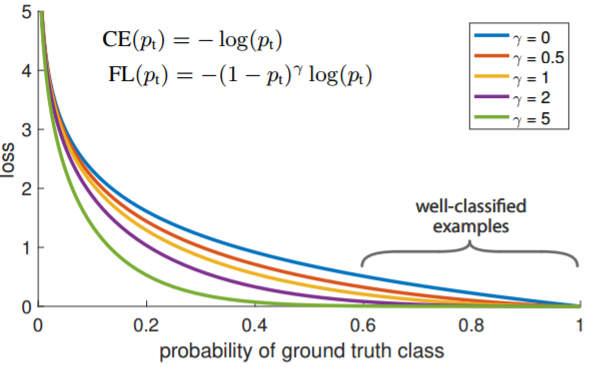
只添加
α
\alpha
α虽然可以平衡正负样本的重要性,但是无法解决简单与困难样本的问题。
γ
\gamma
γ调节简单样本权重降低的速率,当
γ
\gamma
γ为0时即为交叉熵损失函数,当
γ
\gamma
γ增加时,调整因子的影响也在增加。实验发现
γ
\gamma
γ为2是最优。
IoU Loss
IoU损失由Unitbox[8]首先提出,其公式为
L
I
o
U
(
x
,
x
~
)
=
−
ln
x
∩
x
~
x
∪
x
~
\mathcal{L}_{\rm IoU}(x,\tilde{x})=-\ln\frac{x\cap\tilde{x}}{x\cup\tilde{x}}
LIoU(x,x~)=−lnx∪x~x∩x~ 它的后向传播计算为
它的后向传播计算为
∂
L
∂
x
=
∂
∂
x
(
−
ln
I
o
U
)
=
−
1
I
o
U
∂
∂
x
(
I
o
U
)
=
1
I
o
U
I
×
∂
U
∂
x
−
U
×
∂
I
∂
x
U
2
=
1
U
∂
X
x
−
U
+
I
U
I
∂
I
∂
x
\begin{aligned} \frac{\partial\mathcal{L}}{\partial x} &= \frac{\partial}{\partial x}{(-\ln IoU)} \\ &= -\frac{1}{IoU}\frac{\partial}{\partial x}{( IoU)} \\ &= \frac{1}{IoU}\frac{I\times \frac{\partial U}{\partial x}-U\times\frac{\partial I}{\partial x}}{U^2} \\ &= \frac{1}{U}\frac{\partial X}{x}-\frac{U+I}{UI}\frac{\partial I}{\partial x} \end{aligned}
∂x∂L=∂x∂(−lnIoU)=−IoU1∂x∂(IoU)=IoU1U2I×∂x∂U−U×∂x∂I=U1x∂X−UIU+I∂x∂I
Center-ness
通过多级预测之后发现FCOS和基于锚框的检测器之间仍然存在着一定的距离,主要原因是距离目标中心较远的位置产生很多低质量的预测边框。FCOS中提出了一种简单而有效的策略来抑制这些低质量的预测边界框,而且不引入任何超参数。具体来说,FCOS添加单层分支,与分类分支并行,以预测"Center-ness"位置。
c
e
n
t
e
r
n
e
s
s
∗
=
min
(
l
∗
,
r
∗
)
max
(
l
∗
,
r
∗
)
×
min
(
t
∗
,
b
∗
)
max
(
t
∗
,
b
∗
)
{\rm centerness}^*=\sqrt{\frac{\min(l^*,r^*)}{\max(l^*,r^*)}\times\frac{\min(t^*,b^*)}{\max(t^*,b^*)}}
centerness∗=max(l∗,r∗)min(l∗,r∗)×max(t∗,b∗)min(t∗,b∗)Center-ness(可以理解为一种具有度量作用的概念,在这里称之为"中心度"),中心度取值为0,1之间,使用交叉熵损失进行训练。并把损失加入前面提到的损失函数中。测试时,将预测的中心度与相应的分类分数相乘,计算最终得分(用于对检测到的边界框进行排序)。因此,中心度可以降低远离对象中心的边界框的权重。因此,这些低质量边界框很可能被最终的非最大抑制(NMS)过程滤除,从而显着提高了检测性能。

模型推理
FCOS的模型推断也很直接。给定一张图片并将其前向输入进网络,得到每个特征图 F i F_i Fi的分类概率 p x , y \boldsymbol{p}_{x,y} px,y和回归预测 t x , y \boldsymbol{t}_{x,y} tx,y即可。
数据集与评测指标
数据集
由于保密等原因,电力巡检的图像很多未公开。这里选择Github上的数据集[9],有600张标注的绝缘子图像,其数据格式遵循VOC2007。

评测指标
指标包括 A P , A P 50 , A P 75 AP,AP50,AP75 AP,AP50,AP75和 A R AR AR,其中 A P , A R AP,AR AP,AR为 I o U = 0.50 : 0.95 IoU=0.50:0.95 IoU=0.50:0.95阈值的精度和召回, A P 50 AP50 AP50和 A P 75 AP75 AP75分别为 I o U = 0.50 IoU=0.50 IoU=0.50和 I o U = 0.75 IoU=0.75 IoU=0.75。
实验分析
数据预处理
数据集的图像大小均为 1152 × 854 1152\times854 1152×854,预处理首先进行0.9倍的随机裁剪,然后使用 m e a n = [ 0.485 , 0.456 , 0.406 ] {\rm mean}=[0.485,0.456,0.406] mean=[0.485,0.456,0.406]和 s t d = [ 0.229 , 0.224 , 0.225 ] {\rm std}=[0.229,0.224,0.225] std=[0.229,0.224,0.225]进行数据的归一化处理,同时对图像进行随机水平翻转。
网络设置
实验采用在coco上预训练完成的ResNeXt-50[10]作为backbone,训练时冷冻batch normalization层,并提取
C
3
,
C
4
,
C
5
C_3,C_4,C_5
C3,C4,C5三个特征图。采用BiFPN[11]作为特征金字塔,利用
P
3
,
P
4
,
P
5
,
P
6
,
P
7
P_3,P_4,P_5,P_6,P_7
P3,P4,P5,P6,P7作特征融合,其输出通道数为160,步数分别为
8
,
16
,
32
,
64
,
128
8,16,32,64,128
8,16,32,64,128。Detection Head则使用8通道重复3次的卷积层。以上卷积层均采用group normalization[12]处理。由于本任务只进行绝缘子的目标检测,因此最后的总类数
C
=
1
C=1
C=1。
Focal Loss的超参数设置为
α
=
0.25
,
γ
=
2.0
\alpha=0.25,\gamma=2.0
α=0.25,γ=2.0,光滑
L
1
\mathcal{L}_1
L1的参数
β
=
0.1
\beta=0.1
β=0.1。
IoU的阈值设置为
0.5
0.5
0.5,推理时
N
M
S
\rm NMS
NMS的的阈值则设置为
0.6
0.6
0.6。
损失函数的比例
λ
\lambda
λ设置为1。
训练参数
训练采用Adam优化器,其参数为 γ = 1 , m o m e n t u m = 0.9 \gamma=1,{\rm momentum}=0.9 γ=1,momentum=0.9。基础的学习率设置为 0.01 0.01 0.01,训练过程中采用多阶段线性warm up策略,warm up系数设置为 0.001 0.001 0.001,warm up次数设置为 1000 1000 1000。训练总迭代次数设置为 11000 11000 11000,迭代次数在 1000 − 6000 1000-6000 1000−6000次之间达到基础学习率 0.01 0.01 0.01。权重衰减系数设置为 0.0001 0.0001 0.0001。训练集采用510张图像,验证集采用90张图像,其比例为 0.85 : 0.15 0.85:0.15 0.85:0.15。
训练结果
训练基于四块TITAN Xp GPU,训练总时长为
1
:
38
:
13
1:38:13
1:38:13,最终的学习率曲线、ctr_loss曲线、location_loss曲线和total_loss曲线如下图所示:




验证结果
对剩余的验证集的图像进行测试,共检测出156个instance,各指标如下图所示:
| AP | AP50 | AP75 | AR |
|---|---|---|---|
| 76.504 | 96.452 | 88.066 | 0.471 |
典型的推断结果如下:

结论
FCOS对于重叠物体的检测不是很好,相似的标定框可能会漏检,因为相对小的事实标定框会被配对,但是相对大的标定框没有被回归到。因为尺寸相似只会出现在同一个FPN层,不会在其他层再次出现,从而产生漏检。
引用
- [1] 左齐.基于AI的无人机线路巡检[J].农村电气化,2021(02):19-20.
- [2] https://zhuanlan.zhihu.com/p/62103812
- [3] https://blog.csdn.net/ytusdc/article/details/107864527
- [4] https://blog.csdn.net/zhouchen1998/article/details/108032597
- [5] https://arxiv.org/pdf/1912.02424.pdf
- [6] https://arxiv.org/pdf/1904.01355.pdf
- [7] T. Lin, P. Goyal, R. Girshick, K. He and P. Dollár, “Focal Loss for Dense Object Detection,” 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017, pp. 2999-3007, doi: 10.1109/ICCV.2017.324.
- [8] Jiahui Yu, Yuning Jiang, Zhangyang Wang, Zhimin Cao, and Thomas Huang. 2016. UnitBox: An Advanced Object Detection Network. In Proceedings of the 24th ACM international conference on Multimedia (MM '16). Association for Computing Machinery, New York, NY, USA, 516–520. DOI:https://doi.org/10.1145/2964284.2967274
- [9] https://github.com/InsulatorData/InsulatorDataSet
- [10] http://export.arxiv.org/pdf/2007.02480.pdf
- [11] https://arxiv.org/pdf/1911.09070.pdf
- [12] Wu, Y., He, K. Group Normalization. Int J Comput Vis 128, 742–755 (2020). https://doi.org/10.1007/s11263-019-01198-w















 1718
1718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









