







部分内容总结自张宇和考研竞赛凯哥
概率论基础
- A B AB AB互不相容时,不仅 P ( A B C ) = 0 P(ABC)=0 P(ABC)=0,而且 P ( A B C ) = 0 P(ABC)=0 P(ABC)=0
- 一事件发生概率为1,不能断定该事件为全集。
- P ( A ) > 0 , P ( B ) > 0 P(A)>0,P(B)>0 P(A)>0,P(B)>0时互斥和独立不能同时成立
- 互斥则 P ( A ∪ B ) = P ( A ) + P ( B ) P (A\cup B)=P(A)+P(B) P(A∪B)=P(A)+P(B)
- 互斥则 A ⊆ C ‾ A\subseteq \overline C A⊆C,此时 P ( A C ‾ ) = P ( A ) P(A\overline C)=P(A) P(AC)=P(A)
条件概率
见到条件概率如果没有独立性就直接写出公式
P ( A ∣ B ) = 1 − P ( A ‾ ∣ B ) P(A|B)=1-P(\overline A| B) P(A∣B)=1−P(A∣B)
常见分布
- 几何分布的取点是离散的整数点
- 泊松分布是单位时间内独立事件发生次数的概率分布,指数分布是独立事件的时间间隔的概率分布。
二项分布概率最大项K
已知X~B(n,p),则要使 P(x=k0)最大
- 当 ( n + 1 ) p (n+1)p (n+1)p为整数时, k 0 = ( n + 1 ) p k0=(n+1)p k0=(n+1)p,或 k 0 = ( n + 1 ) p − 1 k0=(n+1)p-1 k0=(n+1)p−1
- 当 ( n + 1 ) p (n+1)p (n+1)p不是整数时, k 0 = ( n + 1 ) p 向下取整 k0=(n+1)p向下取整 k0=(n+1)p向下取整
其实就是前后项作比化简出来的
分布函数
三大性质
- 单调不减
- F ( − ∞ ) = 0 , F ( ∞ ) = 1 F(-\infty)=0,F(\infty)=1 F(−∞)=0,F(∞)=1
- 右连续
F ( x ) F(x) F(x)是分布函数,那 F ( 2 x − 1 ) F(2x-1) F(2x−1)是分布函数,但 1 − F ( − x ) 1-F(-x) 1−F(−x)不是,因为它是左连续的
【例】假设随机变量
X
X
X的绝对值不大于1,
P
{
X
=
−
1
}
=
1
8
P\{X=-1\}=\frac 18
P{X=−1}=81,
P
{
X
=
1
}
=
1
4
P\{X=1\}=\frac14
P{X=1}=41。在事件
{
−
1
<
X
<
1
}
\{-1<X<1\}
{−1<X<1}出现的条件下,
X
X
X在
(
−
1
,
1
)
(-1,1)
(−1,1)内的任一子区间上取值的条件概率与该子区间长度
成正比。试求X的分布函数
F
(
x
)
=
P
{
X
≤
x
}
F(x)=P\{X≤x\}
F(x)=P{X≤x}
【解析】
F ( x ) = { P { X < 0 } = 0 x < 1 P { X < x } − 1 ≤ x < 1 1 x ≥ 1 F(x)=\left\{ \begin{matrix} P\{X<0\}=0 &x<1 \\P\{X<x\} & -1\le x <1 \\1 & x \ge 1 \end{matrix} \right. F(x)=⎩ ⎨ ⎧P{X<0}=0P{X<x}1x<1−1≤x<1x≥1
其中 P { X < x } = P { X < − 1 } + P { X = − 1 } + P { − 1 ≤ X ≤ x } = 0 + 1 8 + P { − 1 ≤ X ≤ x } P\{X<x\}=P\{X<-1\}+P\{X=-1\}+P\{-1\le X\le x\}=0+\frac 18+P\{-1\le X\le x\} P{X<x}=P{X<−1}+P{X=−1}+P{−1≤X≤x}=0+81+P{−1≤X≤x}
而关于 P { − 1 ≤ X ≤ x } P\{-1\le X\le x\} P{−1≤X≤x}实为条件概率 P { − 1 ≤ X ≤ 1 } ⋅ P { − 1 ≤ X ≤ x ∣ − 1 ≤ X ≤ 1 } = 5 8 ⋅ x + 1 2 P\{-1\le X\le 1\}·P\{-1\le X\le x |-1\le X\le 1\}=\frac 58 ·\frac{x+1}{2} P{−1≤X≤1}⋅P{−1≤X≤x∣−1≤X≤1}=85⋅2x+1
概率密度
见到概率密度自然知道是连续型(是 F ( x ) F(x) F(x)连续),就如同见到分布律就知道是离散型一样
- f ( x ) > 0 f(x)>0 f(x)>0
- ∫ − ∞ ∞ f ( x ) d x = 1 \int_{-\infty}^\infty f(x)dx=1 ∫−∞∞f(x)dx=1
因此存在即使满足第二点 ∫ − ∞ ∞ f ( x ) d x = 1 \int_{-\infty}^\infty f(x)dx=1 ∫−∞∞f(x)dx=1也不是概率密度函数的情况。例如对于概率密度函数 f ( x ) f(x) f(x),则 2 x f ( x 2 ) 2xf(x^2) 2xf(x2)不是概率密度函数,即便它 ∫ − ∞ ∞ 2 x f ( x 2 ) d x = ∫ − ∞ ∞ f ( x 2 ) d x 2 = 1 \int_{-\infty}^\infty 2xf(x^2)dx=\int_{-\infty}^\infty f(x^2)dx^2=1 ∫−∞∞2xf(x2)dx=∫−∞∞f(x2)dx2=1,但是在 x < 0 x<0 x<0时它值是负的
- 概率密度函数从负无穷到正无穷还有e的平方幂,直接鉴定为正态分布
具有相同概率密度
X
X
X和
−
X
-X
−X有相同的概率密度
⇔
F
(
x
)
=
P
{
−
X
≤
x
}
\Leftrightarrow F(x)=P\{-X\le x\}
⇔F(x)=P{−X≤x}
期望的计算
两个独立随机变量,乘积的期望等于期望的乘积,即 E ( X Y ) = E X ⋅ E Y E(XY)=EX·EY E(XY)=EX⋅EY
上面这句话的一种经典情况是, E ( X 2 ) ≠ E X ⋅ E X E(X^2)\neq EX·EX E(X2)=EX⋅EX
证明独立
相关一定不独立,不相关只是没有线性关系,不代表不相关。得构造事件并验证 p ( A B ) = p ( A ) ⋅ p ( B ) p(AB)=p(A)·p(B) p(AB)=p(A)⋅p(B)是否成立,若成立则独立
独立性的另一个标志是: P ( B ∣ A ) = P ( B ∣ A ‾ ) P(B|A)=P(B|\overline A) P(B∣A)=P(B∣A),即不管 A A A是否发生, B B B发生的概率都一样,即二者无关,即独立
独立的充要条件是 P ( A ∣ B ) = P ( A ) P(A|B)=P(A) P(A∣B)=P(A),即条件对结果不影响,一种可能会出现的复杂形式如下(用作例子)
P ( A ∪ B ∣ C ) = P ( A ∪ B ) ⇒ P ( A ∣ C ) + P ( B ∣ C ) − P ( A B ∣ C ) = P ( A ) = P ( B ) − P ( A B ) P(A \cup B|C)=P(A \cup B)\\\Rightarrow P(A|C)+P(B|C)-P(AB|C)=P(A)=P(B)-P(AB) P(A∪B∣C)=P(A∪B)⇒P(A∣C)+P(B∣C)−P(AB∣C)=P(A)=P(B)−P(AB)
一般情况下不独立,举反例即可
函数的分布
积分为 π \pi π
∫ − ∞ ∞ e − t 2 d t = π \int_{-\infty}^\infty e^{-t^2}dt = \sqrt \pi ∫−∞∞e−t2dt=π不仅可以用标准化为正态来做,也可以用上面这个化简
那么像 f ( x ) = A e − x 2 + x f(x)=Ae^{-x^2+x} f(x)=Ae−x2+x
泊松分布与泰勒展开
λ是事件的平均发生率(单位区间内事件发生的平均发生次数)。
注意泊松分布的
k
k
k得从0开始,不从
0
0
0开始的就不是
P
{
x
=
k
}
=
λ
k
k
!
e
−
λ
,
k
=
0
,
1
,
2
,
.
.
.
P\{x=k\}=\frac{\lambda^k}{k!}e^{-\lambda},k=0,1,2,...
P{x=k}=k!λke−λ,k=0,1,2,...
对它每项相加则可得
e
−
λ
∑
k
=
0
∞
λ
k
k
!
=
e
−
λ
e
λ
=
1
e^{-\lambda}\sum_{k=0}^\infty\frac{\lambda^k}{k!}=e^{-\lambda}e^{\lambda}=1
e−λk=0∑∞k!λk=e−λeλ=1
而
e
x
e^x
ex的泰勒展开则是
∑
k
=
0
∞
x
k
k
!
=
e
x
\sum_{k=0}^{\infty}\frac{x^k}{k!}=e^x
k=0∑∞k!xk=ex
概率论:多维
二维的独立性
只有矩形区域才有可能独立
验证 f Y ( y ) ⋅ f ( X ( x ) = f ( x , y ) f_Y(y)·f(_X(x)=f(x,y) fY(y)⋅f(X(x)=f(x,y)
离散型 ( X , Y ) (X,Y) (X,Y)的分布律的计算
涉及到联合,都得先看两变量是否独立,不要默认独立。
联合分布律包含 p i j p_{ij} pij,也包含 X X X和 Y Y Y的边缘分布,要在整个表格上都体现出来。
并且这俩中的某些可能缺失,需要依靠剩下的补全。或者由其他信息推出这俩的部分信息,然后补全表格。其他信息是指,比如 X X X和 Y Y Y的协方差之类的东西,通过计算和变形得到能填入联合分布律表格中的一部分,随后利用表格性质补全即可。
不管 X X X和 Y Y Y是否独立,各自如果单独给出分布律是直接可以填在表格边上的边缘分布栏目中的。
二维条件分布的处理
- f Y ( y ) f_Y(y) fY(y)是 x x x任意的 Y Y Y的分布
- f Y ∣ X ( y ∣ x ) f_{Y|X}(y|x) fY∣X(y∣x)是 x x x固定的 y y y的分布(这里就把 x x x当常数)
例如 P { − 1 < X < 1 ∣ Y = 2 } P\{-1<X<1|Y=2\} P{−1<X<1∣Y=2}这样的是一维,但是 P { − 1 < X < 1 ∣ Y ≤ 2 } P\{-1<X<1|Y\le2\} P{−1<X<1∣Y≤2}就是二维,按照下式计算
P { − 1 < X < 1 ∣ Y ≤ 2 } = P { − 1 < X < 1 , Y ≤ 2 } P { Y ≤ 2 } = ∬ D f ( x , y ) d σ ∫ f Y ( y ) P\{-1<X<1|Y\le2\}=\frac{P\{-1<X<1,Y\le2\}}{P\{Y\le2\}}=\frac{\iint_D f(x,y)d\sigma}{\int f_Y(y)} P{−1<X<1∣Y≤2}=P{Y≤2}P{−1<X<1,Y≤2}=∫fY(y)∬Df(x,y)dσ
关于
P
{
−
1
<
X
<
1
,
Y
≤
2
}
P\{-1<X<1,Y\le2\}
P{−1<X<1,Y≤2}的处理,若
x
,
y
x,y
x,y独立,则化为
P
{
−
1
<
X
<
1
}
⋅
P
{
Y
≤
2
}
P\{-1<X<1\}·P\{Y\le2\}
P{−1<X<1}⋅P{Y≤2},若不独立则寻找积分区域按二重积分处理
关于
P
{
X
<
Y
}
P\{X<Y\}
P{X<Y}的处理,这种只能按区域二重积分
联合边缘条件直接的关系
f ( x , y ) f X ( x ) = f Y ∣ X ( y ∣ x ) \frac{f(x,y)}{f_X(x)}=f_{Y|X}(y|x) fX(x)f(x,y)=fY∣X(y∣x)
- 由 f ( x , y ) f(x,y) f(x,y)求边缘就是积分
- 只知道边缘分布得不到联合分布,必须还有条件概率才行
- 求 P { X + Y > 1 } P\{X+Y>1\} P{X+Y>1}这种还是积分(主要是定区域)
ξ = min { X , Y } \xi = \min\{X,Y\} ξ=min{X,Y}这类题目的处理
若是离散的,画表格就行,所有离散型问题的第一步都是画表格
正态分布的相加与标准化
D ( X ± Y ) = D X + D Y ± C o v ( X , Y ) D(X\pm Y)=DX+DY\pm Cov(X,Y) D(X±Y)=DX+DY±Cov(X,Y),在 X X X和 Y Y Y独立的情况下, C o v ( X , Y ) = 0 Cov(X,Y)=0 Cov(X,Y)=0。
因此在 X ∼ N ( μ 1 , σ 1 2 ) X\sim N(\mu_1,\sigma_1^2) X∼N(μ1,σ12)和 Y ∼ N ( μ 2 , σ 2 2 ) Y\sim N(\mu_2,\sigma_2^2) Y∼N(μ2,σ22)独立的情况下 X + Y ∼ ( μ 1 + μ 2 , σ 1 2 + σ 2 2 ) X+Y\sim(\mu_1+\mu_2,\sigma_1^2+\sigma_2^2) X+Y∼(μ1+μ2,σ12+σ22)
定义: X ∼ N ( μ , σ 2 ) X\sim N(\mu,\sigma^2) X∼N(μ,σ2),则 Z = X − μ σ ∼ N ( 0 , 1 ) Z=\frac{X-\mu}{\sigma}\sim N(0,1) Z=σX−μ∼N(0,1)
一切非标准化的正态分布要标准化再做题,如 P { X ≤ μ − σ 2 } P\{X\le \mu-\sigma^2\} P{X≤μ−σ2}就化为 P { X − μ σ ≤ σ } = Φ ( σ ) P\{\frac{X-\mu}{\sigma}\le \sigma\}=\Phi(\sigma) P{σX−μ≤σ}=Φ(σ)
均匀分布

直接椭圆面积/圆面积就出来了,不用积分
二维正态分布(降维思想)
设随机变量 X X X和 Y Y Y都服从正态分布,且它们不相关,则 X X X和 Y Y Y未必独立。
- 不知道 ( X , Y ) (X,Y) (X,Y)是否服从二维正态分布
- 不知道 X + Y X+Y X+Y是否服从一维正态分布
- 只有二维正态 ρ = 0 \rho = 0 ρ=0才独立
- 已知边缘分布无法获取联合分布(对应一二条)
- 但若随机变量 X X X和 Y Y Y都服从正态分布且相互独立,则 ( x , y ) (x,y) (x,y)服从二维正态分布
- (接上条)若 ( x , y ) (x,y) (x,y)服从二维正态分布,则 X + Y X+Y X+Y服从正态分布
- 服从二维正态分布的不一定 X X X和 Y Y Y相互独立
即二维到一维无条件,一维需要有条件(独立)才能升级成二维。利用降维做题
降维例题:
设
(
X
,
Y
)
∼
N
(
μ
,
μ
,
σ
2
,
σ
2
,
0
)
(X,Y)\sim N(\mu,\mu,\sigma^2,\sigma^2,0)
(X,Y)∼N(μ,μ,σ2,σ2,0),则
P
{
X
<
Y
0
}
=
P\{X<Y0\}=
P{X<Y0}=___
P { X − Y < 0 } = P { Y − X > 0 } P\{X-Y<0\}=P\{Y-X>0\} P{X−Y<0}=P{Y−X>0},相互独立则 X ∼ N ( μ , σ 2 ) , Y ∼ N ( μ , σ 2 ) X\sim N(\mu,\sigma^2),Y\sim N(\mu,\sigma^2) X∼N(μ,σ2),Y∼N(μ,σ2),则 Y − X ∼ N ( μ , 2 σ 2 ) Y-X\sim N(\mu ,2\sigma^2) Y−X∼N(μ,2σ2)(其他题如有必要可以标准化一下)
故为1/2
数字特征
E
X
=
∬
D
x
⋅
f
(
x
,
y
)
d
σ
E
X
2
=
∬
D
x
2
f
(
x
,
y
)
d
σ
EX=\iint_Dx·f(x,y)d\sigma\\\text{ } \\ EX^2=\iint_Dx^2f(x,y)d\sigma
EX=∬Dx⋅f(x,y)dσ EX2=∬Dx2f(x,y)dσ
这是积分问题
D X = E ( X 2 ) − ( E X ) 2 DX=E(X^2)-(EX)^2 DX=E(X2)−(EX)2
函数的分布率的计算
所有分布律都得列出范围 P { X = x k } = p k , k = 1 , 2 , ⋯ P\{X=x_k\}=p_k,k=1,2,\cdots P{X=xk}=pk,k=1,2,⋯
本质是反解,例如下
X
∼
B
(
n
,
p
)
X\sim B(n,p)
X∼B(n,p),则
Y
=
n
−
X
Y=n-X
Y=n−X服从的分布律为
P { Y = k } = P { n − x = k } = P { x = n − k } = C n n − k P n − k ( 1 − p ) n − ( n − k ) , k = 1 , 2 , ⋯ n P\{Y=k\}=P\{n-x=k\}=P\{x=n-k\}=C_{n}^{n-k}P^{n-k}(1-p)^{n-(n-k)},k=1,2,\cdots n P{Y=k}=P{n−x=k}=P{x=n−k}=Cnn−kPn−k(1−p)n−(n−k),k=1,2,⋯n
非独立的不要$$
Y = f ( X ) Y=f(X) Y=f(X)的计算
函数的分布函数的计算,就是发现 Y = f ( X ) Y=f(X) Y=f(X)后的处理方法,本质是把 y y y的范围转化为 x x x的范围

通过移动横线来判断 x x x的范围,按图像分段,两个点分三段,这个段是分情况下的移动横线的范围。
谁的函数给谁分段,这里是求 F Y ( y ) F_Y(y) FY(y),那就给 y y y分段,注意右连续性,即左闭右开
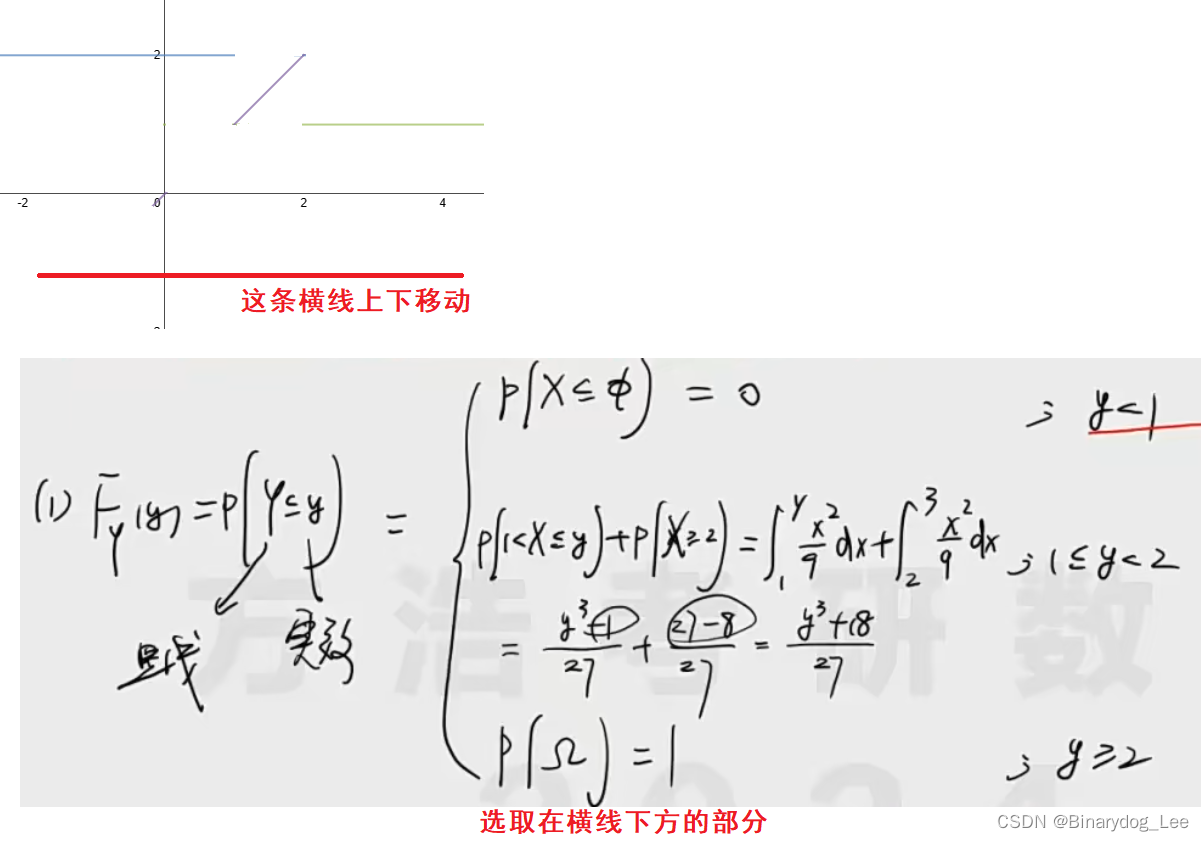
然后
P
{
X
≤
Y
}
P\{X\le Y\}
P{X≤Y}即计算
P
{
Y
−
X
≥
0
}
P\{Y-X\ge0\}
P{Y−X≥0}因此要看下式
P { Y − X } = { 2 − X X ≤ 1 0 1 < X < 2 1 − X X ≥ 2 P\{Y-X\} = \left\{\begin{aligned} 2-X & &X \le 1 \\ 0 & & 1<X<2\\ 1-X & & X \ge 2 \end{aligned} \right. P{Y−X}=⎩ ⎨ ⎧2−X01−XX≤11<X<2X≥2
前俩都是大于等于0的,符合题意 P { Y − X ≥ 0 } = P { X < 2 } P\{Y-X\ge0\}=P\{X<2\} P{Y−X≥0}=P{X<2},积一下 x x x的概率密度就可以了
Z = f ( X , Y ) Z=f(X,Y) Z=f(X,Y)的计算
卷积公式
f Z ( z ) = ∫ − ∞ ∞ f ( x , y ( x , z ) ) ∣ ∂ y ( x , z ) ∂ z ∣ d x f_Z(z)=\int_{-\infty}^\infty f(x,y(x,z))|\frac{\partial y(x,z)}{\partial z}|dx fZ(z)=∫−∞∞f(x,y(x,z))∣∂z∂y(x,z)∣dx
而范围的求法则如下:
比如说 0 < x < 1 , 0 < y < 1 , Z = X − Y 0<x<1,0<y<1,Z=X-Y 0<x<1,0<y<1,Z=X−Y,那就是下面的范围求交集
{ 0 < x < 1 ⇒ 0 < x < 1 0 < x − z < 1 ⇒ z − 1 < x < z \left\{ \begin{aligned} 0<x<1 & \Rightarrow & 0<x<1 \\ 0<x-z<1 & \Rightarrow&z-1<x<z \end{aligned} \right. {0<x<10<x−z<1⇒⇒0<x<1z−1<x<z
分别令 z − 1 z-1 z−1、 z z z等于 0 0 0和 1 1 1,得到三个分段点0、1、2(有一个重复的1),然后就开始求交集
- z < 0 z<0 z<0:没交集
- 0 < z < 1 0<z<1 0<z<1:和 0 < x < 1 0<x<1 0<x<1有交集 [ 0 , z ] [0,z] [0,z],这就是积分上下限,概率密度是 ∫ 0 z ( 2 − z ) d x \int_0^z (2-z )dx ∫0z(2−z)dx
- 1 < z < 2 1<z<2 1<z<2:和 0 < x < 1 0<x<1 0<x<1有交集 [ z − 1 , 1 ] [z-1,1] [z−1,1],概率密度是 ∫ z − 1 1 ( 2 − z ) d x \int_{z-1}^1 (2-z )dx ∫z−11(2−z)dx
- 2 < z 2<z 2<z:没交集(没交集统一写“其他”)
要是求分布函数就得分四段(三个分界点)
概率论:大数定律
依概率收敛
依概率收敛的步骤说白了就两点
- 构造 ∣ X n − a ∣ < ε |X_n-a|<\varepsilon ∣Xn−a∣<ε
- 求极限 lim n → ∞ P { ∣ X n − a ∣ < ε } \lim _{n \to \infty}P\{|X_n-a|<\varepsilon\} limn→∞P{∣Xn−a∣<ε}(此处多用夹逼准则)
然后就证出来 X n → P a X_n\xrightarrow P a XnPa
数理统计:基础
含 X i X_i Xi的期望
最基本的方法就是把 E ( f ( x ) ) E(f(x)) E(f(x))拆成多个期望相加的式子
乘积的期望不一定等于期望的乘积,除非两者独立。如果两者不独立(比如 X i X_i Xi和 X ‾ \overline{X} X)就得用别的方法,例如把下式:
E ( X i X ‾ ) = E X i ⋅ X 1 + X 2 + … + X n n = 1 n [ E X 1 2 + E X 1 X 2 + … + E X 1 X n ] E(X_i\overline{X})=EX_i·\frac{X_1+X_2+…+X_n}{n}=\frac 1n[EX_1^2+EX_1X_2+…+EX_1X_n] E(XiX)=EXi⋅nX1+X2+…+Xn=n1[EX12+EX1X2+…+EX1Xn]
其中 E X 1 2 EX_1^2 EX12的两个参数不独立,使用 D X = E ( X 2 ) − ( E X ) 2 DX=E(X^2)-(EX)^2 DX=E(X2)−(EX)2,其他的均独立,乘积的期望等于期望的乘积,即都等于 ( E X ) 2 (EX)^2 (EX)2
含 X i X_i Xi的协方差
使用协方差运算法则
C
o
v
(
X
,
X
)
=
D
X
C
o
v
(
X
,
Y
)
=
C
o
v
(
Y
,
X
)
C
o
v
(
a
X
,
b
Y
)
=
a
b
C
o
v
(
X
,
Y
)
C
o
v
(
X
+
a
,
Y
+
b
)
=
C
o
v
(
X
,
Y
)
C
o
v
(
X
1
+
X
2
,
Y
)
=
C
o
v
(
X
1
,
Y
)
+
C
o
v
(
X
2
,
Y
)
Cov(X,X)=DX\\ Cov(X,Y)=Cov(Y,X)\\ Cov(aX,bY)=abCov(X,Y)\\ Cov(X+a,Y+b)=Cov(X,Y)\\ Cov(X_1+X_2,Y)=Cov(X_1,Y)+Cov(X_2,Y)
Cov(X,X)=DXCov(X,Y)=Cov(Y,X)Cov(aX,bY)=abCov(X,Y)Cov(X+a,Y+b)=Cov(X,Y)Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y)
另一方面由于协方差描述的是两个变量总体误差的期望,即
C
o
v
(
X
,
Y
)
=
E
[
(
X
−
E
X
)
(
Y
−
E
Y
)
]
=
E
X
Y
−
E
X
E
Y
Cov(X,Y)=E[(X-EX)(Y-EY)]=EXY-EXEY
Cov(X,Y)=E[(X−EX)(Y−EY)]=EXY−EXEY,所以通常有
C
o
v
(
X
1
,
X
‾
)
=
C
o
v
(
X
2
,
X
‾
)
Cov(X_1,\overline{X})=Cov(X_2,\overline{X})
Cov(X1,X)=Cov(X2,X)
当然这里的运算依然是参考前面的内容,先展开 X ‾ \overline{X} X,之后再利用运算法则提出 1 n \frac 1n n1,随即利用分配律处理。并且由于 X i X_i Xi和 X n X_n Xn是独立同分布的,所以 C o v ( X 1 , X n ) = 0 Cov(X_1,X_n)=0 Cov(X1,Xn)=0
含 X i X_i Xi的方差
主要以使用公式 D ( X ± Y ) = D X + D Y ± 2 C o v ( X , Y ) D(X\pm Y)=DX+DY\pm 2Cov(X,Y) D(X±Y)=DX+DY±2Cov(X,Y)为主,若协方差不好求,则按上面的方法,将 X ‾ \overline X X展开处理。展开的多项式使用 D ( a X ) = a 2 D X D(aX)=a^2DX D(aX)=a2DX等方法处理
E ( S 2 ) = D X = σ 2 E(S^2)=DX=\sigma^2 E(S2)=DX=σ2的证明
S 2 S^2 S2是样本方差
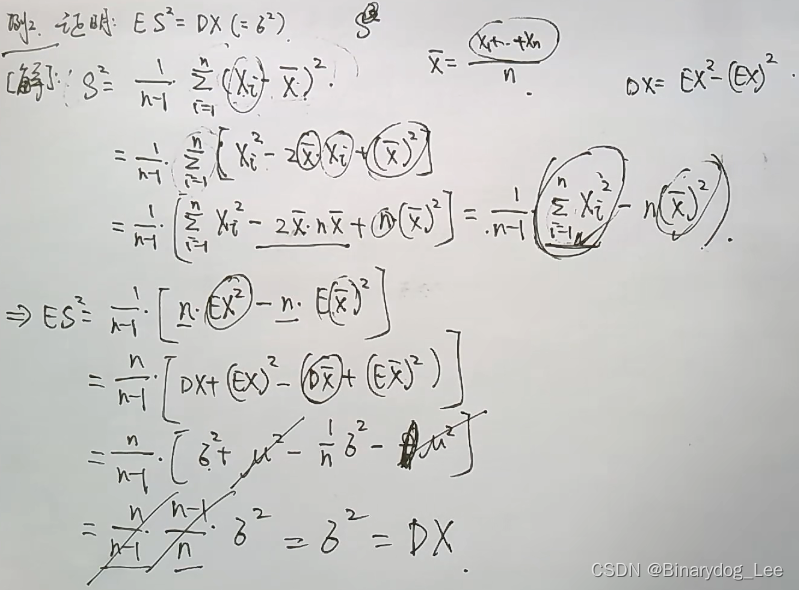
E ( S 2 ) E(S^2) E(S2)的处理
主要依靠公式: E ( S 2 ) = D X = σ 2 = E ( X 2 ) − ( E X ) 2 E(S^2)=DX=\sigma^2=E(X^2)-(EX)^2 E(S2)=DX=σ2=E(X2)−(EX)2,另一方面
E ( X 2 ) = ∫ − ∞ + ∞ x 2 f ( x ) d x E(X^2)=\int_{-\infty}^{+\infty}x^2f(x)dx E(X2)=∫−∞+∞x2f(x)dx
积分时记得利用积分性质(对称性啥的)
另一种方法参见下方的“来自一个正态总体的抽样分布”章节的结论2,可以采用它的变式
含 D X ‾ D\overline X DX的处理
D X ‾ = 1 n D X D \overline X=\frac 1n DX DX=n1DX确实成立,但是前提是 n n n项平均值。如果是 2 n 2n 2n项就不成立
2001年题
X ‾ = 1 2 n ∑ i = 0 2 n X i \overline X=\frac{1}{2n}\sum_{i=0}^{2n}X_i X=2n1i=0∑2nXi
那 D X ‾ = 1 2 n D X D \overline X=\frac 1{2n} DX DX=2n1DX
其他
Z = ∑ i = 1 n ( X i − X ‾ ) 2 ⇒ E Z = ( n − 1 ) E ( S 2 ) = ( n − 1 ) D X Z=\sum_{i=1}^n(X_i-\overline X)^2 \Rightarrow EZ=(n-1)E(S^2)=(n-1)DX Z=i=1∑n(Xi−X)2⇒EZ=(n−1)E(S2)=(n−1)DX
数理统计:三大分布
再三大分布的语境下,遇到不是标准正态分布的首先应当先标准化,即 x − μ σ ∼ N ( 0 , 1 ) \frac{x-\mu}{\sigma}\sim N(0,1) σx−μ∼N(0,1)
正态+正态不一定还是正态
- 若 X X X和 Y Y Y都是正态分布,则 X + Y X+Y X+Y不一定是正态分布
- 若 X X X和 Y Y Y都是正态分布,则 ( X + Y ) (X+Y) (X+Y)不一定是二维正态分布
- 若 ( X , Y ) (X,Y) (X,Y)是二维正态分布,则 X X X和 Y Y Y都是正态分布
- 若 X X X和 Y Y Y都是正态分布,且 X X X和 Y Y Y独立,则 X + Y X+Y X+Y是正态分布, ( X , Y ) (X,Y) (X,Y)是二维正态分布,且 ρ = 0 \rho = 0 ρ=0
- 若 X X X是正态分布,那么 a X + b ( a ≠ 0 ) aX+b\text{ }(a\neq 0) aX+b (a=0)也是正态分布
- 若对于 ∀ a X + b Y \forall aX+bY ∀aX+bY均为正态分布,则 ( X , Y ) (X,Y) (X,Y)服从二维正态分布
- 若
(
X
,
Y
)
(X,Y)
(X,Y)是二维正态分布,且
如果 U V 满足 { U = a 1 X + b 1 Y V = a 2 X + b 2 Y ⇒ 则当 ∣ a 1 b 1 a 2 b 2 ∣ ≠ 0 时, ( U , V ) 服从二次正态分布 如果UV满足\left\{ \begin{aligned} U=a_1X+b_1Y \\ V=a_2X+b_2Y \\ \end{aligned} \right. \Rightarrow 则当 \begin{gathered} \begin{vmatrix} a_1 & b_1 \\ a_2 & b_2 \end{vmatrix} \end{gathered} \neq 0 时,(U,V)服从二次正态分布 如果UV满足{U=a1X+b1YV=a2X+b2Y⇒则当 a1a2b1b2 =0时,(U,V)服从二次正态分布
那个矩阵啥意思?意思就是不是同比例的
符合某某分布,多半问题出在样本需要符合 N ( 0 , 1 ) N(0,1) N(0,1),然后问题由此展开。常用到正态分布的相加(见概率论部分的正态分布的相加小节)。并且通过某些变换(除以某些数之类的),常可以把 X 1 ± X 2 X_1\pm X_2 X1±X2这种视为一个新的 X n ∼ N ( 0 , 1 ) X_n\sim N(0,1) Xn∼N(0,1)
来自一个正态总体的抽样分布

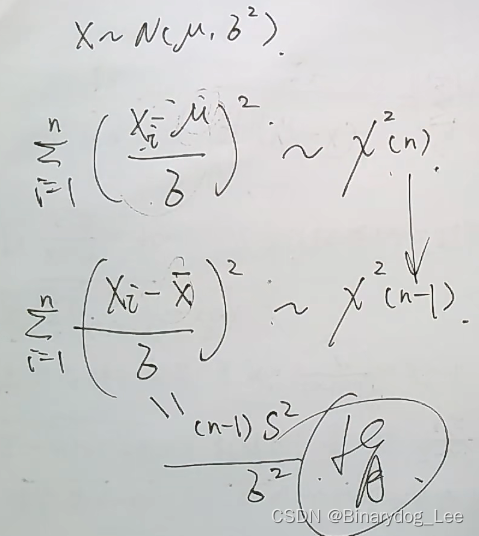
3的本质就是卡方分布的定义
区间估计
分为
σ
\sigma
σ已知和未知两种情况。

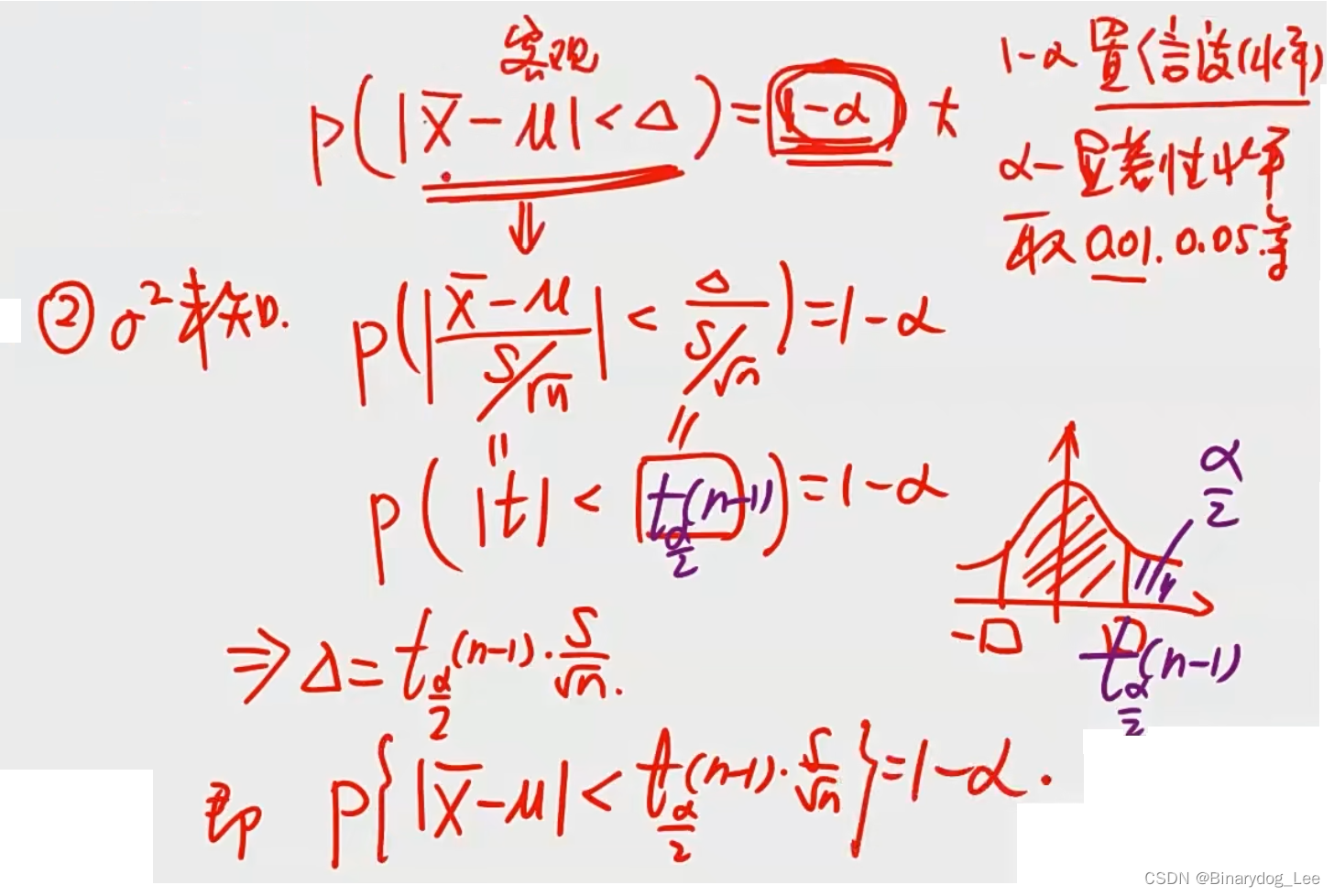
做题先看
σ
2
\sigma^2
σ2是否未知,已知用上面①图的公式,未知用上面②图的公式。
- 找样本容量 n n n、样本均值 x ‾ \overline x x等基本参数
- 明确显著性水平 α \alpha α是多少,显然 1 − α 1-\alpha 1−α即置信区间(若有求的则可套公式出)
- 找拒绝域就是求 Δ \Delta Δ(上图有)
拒绝的依据就是事实如何,假设的东西必须适用于事实才行。
显著性水平 α \alpha α的意义是原假设 H 0 H_0 H0成立,经检验被拒绝的概率,即 P { 拒绝 H 0 ∣ H 0 为真 } P\{拒绝H_0|H_0为真\} P{拒绝H0∣H0为真},即假设小概率事件不会发生,若发生了(即事实数据落入拒绝域),则拒绝 H 0 H_0 H0。
就比如你在显著性水平为 0.05 0.05 0.05下检验 H 0 : μ = 9.7 , H 1 ≠ 9.7 H_0: \mu = 9.7,H_1 \neq 9.7 H0:μ=9.7,H1=9.7,然后算出来 Δ = 0.2132 \Delta = 0.2132 Δ=0.2132,那么假设的置信区间是 9.7 ± Δ 9.7\pm \Delta 9.7±Δ,如果事实(即抽样的结果)是 x ‾ = 10 \overline x = 10 x=10,那么事实落在假设的置信区间的拒绝域,就拒绝 H 0 H_0 H0
求矩估计量/值
求 θ \theta θ的矩估计量/值
- 令 X ‾ = E X \overline X = EX X=EX
- 求出 E X EX EX(显然 E X EX EX含 θ \theta θ)
- 反解 X ‾ = E X \overline X = EX X=EX得到 θ ᨈ = f ( X ‾ ) \mathop{\theta}\limits^{ᨈ} = f(\overline X) θᨈ=f(X)
求 θ \theta θ的矩估计量则 θ ᨈ = f ( X ‾ ) \mathop{\theta}\limits^{ᨈ} = f(\overline X) θᨈ=f(X),求的是矩估计值则 θ ᨈ = f ( x ‾ ) \mathop{\theta}\limits^{ᨈ} = f(\overline x) θᨈ=f(x)
上述求 E X EX EX部分按之前的知识处理即可,不论是离散型还是连续性。
最大似然估计:离散情况
对未知参数 θ \theta θ进行估计时,在该参数可能的取值范围 I I I内选取使样本观测值概率最大的参数值 θ ᨈ \mathop{\theta}\limits^{ᨈ} θᨈ作为 θ \theta θ的估计。
对于离散型的分布,每个 X i X_i Xi的取值对应的有一个概率 p ( θ i ) p(\theta_i) p(θi),有 L ( θ ) = ∏ i = 1 n [ p ( θ i ) ] c i L(\theta)=\prod_{i=1}^n[p(\theta_i)]^{c_i} L(θ)=i=1∏n[p(θi)]ci
其中 c i {c_i} ci是 X i X_i Xi出现的次数,例如 X = 3 X=3 X=3概率是 1 − 5 θ 1-5\theta 1−5θ,且样本中 X = 3 X=3 X=3出现了3回,那就有 ( 1 − 5 θ ) 3 (1-5\theta)^3 (1−5θ)3当然也得对其他项这样做,并把结果乘一块。
然后解下式,反解出
θ
=
?
\theta = ?
θ=?
d
ln
L
(
θ
)
d
θ
=
0
\frac{d \ln L(\theta)}{d\theta}=0
dθdlnL(θ)=0














 8645
8645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









