







1. 介绍
原文链接:
Invariant and Equivariant Representations(小样本等变和不变的互补)
论文地址:
Exploring Complementary Strengths of Invariant and Equivariant Representations for Few-Shot Learning;
参考代码:
https://github.com/nayeemrizve/invariance-equivariance
针对问题:小样本学习、特征的等变和不变性增强
在许多实际问题中,收集大量标记样本是不可行的。少样本学习是在样本数量有限的情况下快速适应新类别。功能强大的特征表示对FSL算法的重要性。
作者在实验中发现,如果让网络在基类训练时保持“变换不变性(invariant)”,比如旋转不变性,平移不变性等,网络对特征的提取、概括能力会增强,但是泛化到新类上的性能会下降;如果让网络在基类训练时保持“等变性(equivariant)”,也就是说网络知道变换后的图片和变换之前的图片之间发生的是什么变换(对不同的变换形式,比如旋转、平移等可以分类辨别),泛化到新类上的能力就会增强。
文章贡献:
-
提出了一种新的训练机制,该机制可以同时增强一般几何变换集的等变性和不变性;
-
这两个对比目标的同时优化允许模型联合学习不仅独立于输入变换的特征,而且还学习编码几何变换结构的特征;
-
加入一个新的自我监督蒸馏目标来实现额外的改进,大量实验表明,即使没有知识蒸馏,我们所提出的方法也可以在五个流行的基准数据集上优于目前最先进的FSL方法。
2. 方法
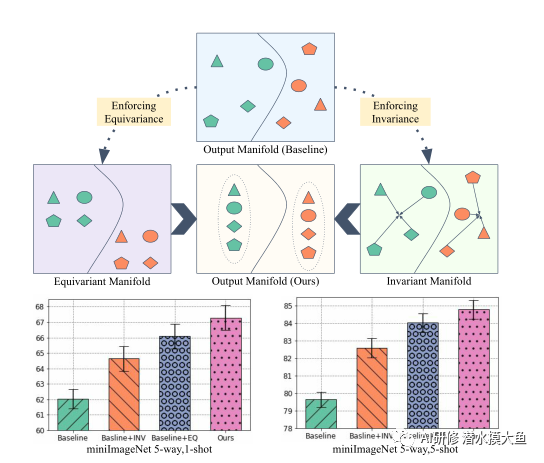
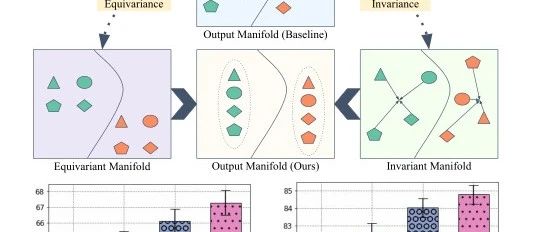
方法概述:形状表示不同的变换,颜色表示不同的类。不变特征提供了更好的区分,而等变特征帮助我们了解数据流形的内部结构。这些互补的表示有助于我们在仅使用少量训练样本的情况下更好地概括新任务。通过联合利用等变和不变特征的优势,我们的方法比基线(底层)有了显著的改进。
2.1 问题表述
少样本学习研究的问题和公式定义:

具体来说,少样本一般使用episodic training scheme,而这篇文章在整个训练集上使用普通的有监督训练方式。整个网络框架可以理解为首先利用特征提取器fΘ将输入x映射到投影空间z;然后通过一个学习器fΦ将投影向量z映射到标签空间y,以以下目标函数优化参数:

两个网络都添加了正则化:
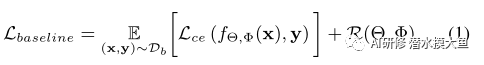
2.2 通过自监督学习SSL注意感应式偏置
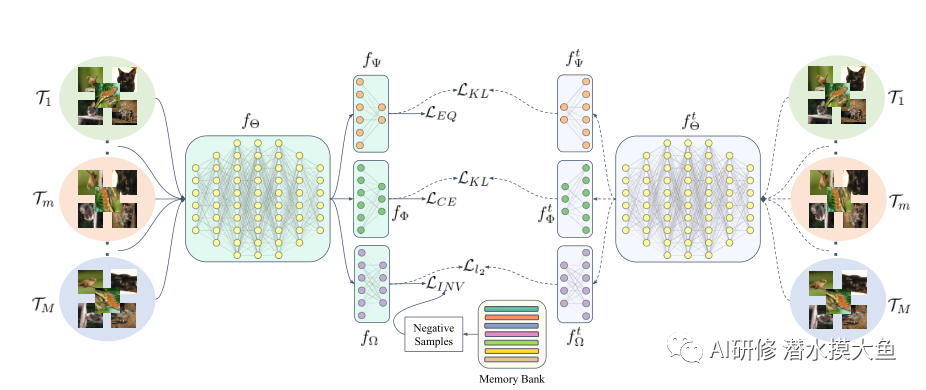
训练期间的网络架构:向共享特征提取器fΘ提供一系列转换输入(通过应用转换T1…TM进行转换)。生成的嵌入被转发到三个平行头fψ、fΦ和fΩ分别侧重于学习等变特征、区分类边界和不变特征。结果输出表示是从模型的旧副本(右侧的教师模型)跨多个头部提取的,以进一步改进编码表示。值得注意的是,负样本的专用记忆库有助于稳定我们不变的对比学习。
提出通过简单地执行自监督学习(SSL)来实现一般几何变换T的等变性和不变性。自我监督对于在不访问语义标签的情况下学习一般特征特别有用。对于表示学习,自监督方法通常旨在实现与某些输入变换的等价性,或者通过使表示不变来学习区分实例。
变换集T可以从几何变换族DT中获得;T∼ DT。这里,Dt可以解释为一系列几何变换,如欧几里德变换、相似变换、仿射变换和射影变换。所有这些几何变换都可以用具有不同自由度的R3×3矩阵表示。然而,对于连续的几何变换空间T,强制执行等变性和不变性是困难的,甚至可能导致次优解。为了克服这个问题,在这项工作中,我们量化了仿射变换的完整空间。我们通过将DT分解为M个离散变换集来近似它。这里,可以根据数据和计算预算的性质选择M。因此,输入x经M个变换首先得到变换组合:
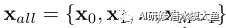
Enforcing Equivariance:
等变特征有助于我们对数据的固有结构进行编码,从而改进特征对新任务的泛化。为了训练网络,我们在没有任何人工监督的情况下创建代理标签。对于特定变换,M维一维热编码向量u为标签,使用交叉熵为loss:
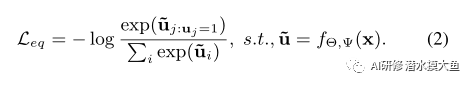
这种在等变空间U中使用代理标签的监督训练确保了输出嵌入z保留变换等变特征。
Enforcing Invariance:
虽然等变表示对数据中的结构进行编码很重要,但它们可能不适合进行类别区分。这是因为我们考虑的变换是不改变图像类的变化,因此一个好的特征提取器也应该编码独立于这些输入变化的表示。为了增强由M个量化变换组成的集合T的不变性,我们引入了另一个MLP fΩ 带参数Ω. fΩ的作用是将基本学习者z的输出嵌入投影到不变空间。
为了优化不变性,我们利用对比损失,例如辨别。我们通过最大化与变换图像对应的嵌入vm(在经历MT变换 Tm之后)和参考嵌入v0(从原始图像嵌入而不应用任何变换T)之间的相似性来实现不变性。重要的是,我们注意到,在一批中选择负样本表示不足以获得鉴别表示。我们在对比损失中使用了一个内存库,在不任意增加批处理大小的情况下对更多的负样本进行采样。其中,正样本就是原图经过变换后的图,负样本来自额外增加的负样本库。此外,内存库允许稳定的收敛行为。我们的学习目标如下:
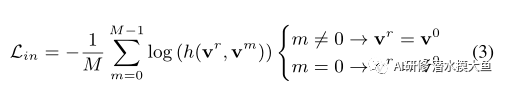
其中,m表示转换索引,~v0表示内存中保存的参考v0的前一个副本,函数h(·)定义为,
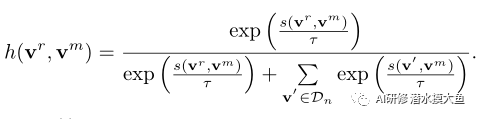
这里,可以看做1+softmax操作,+1是保证log大于0,目标函数表示相似度越大越好。s(.)是一个相似函数,τ是温度,Dn是从特定小批量的内存库中提取的一组负样本。注意,我们还最大限度地提高了参考嵌入v0与其过去表示〜v0之间的相似性,这有助于稳定学习。
Multi-head Distillation:
在我们的例子中,通过配对Logit进行的简单知识提取无法确保先前模型版本学习到的不变和等变表示的转移。因此,我们扩展了基于logit的知识提取思想,并将其应用于不变和等变嵌入。具体地说,在最小化监督分类器头fΦ软输出的Kullback-Leibler(KL)散度的同时,我们还最小化了等变分类器头fψ输出之间的KL散度。因为我们的不变头f的输出Ω这不是一个概率分布,我们最小化L2loss来提取这个头部的知识。知识提炼的总体学习目标如下:
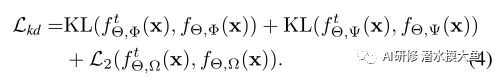
Overall Objective:
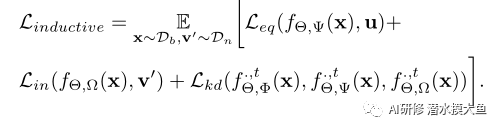
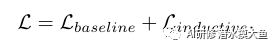
为了进行评估,我们通过从一个包含来自新课程的图像的测试集中抽样FSL任务来测试我们的基础学习者fΘ。每个FSL任务包含一个支持集和一个对应的查询集{Dsupp,Dquery};两者都包含来自相同测试类子集的图像。使用fΘ,我们获得了Dsupp和Dquery图像的嵌入。之后,我们根据图像嵌入和来自Dsupp的相应标签训练了一个简单的逻辑回归分类器。我们使用该线性分类器来推断查询嵌入的标签。
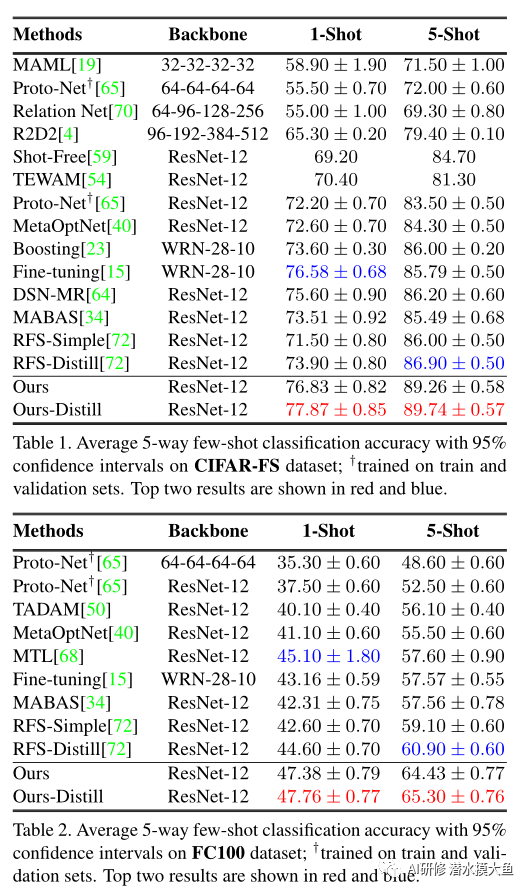
3. 实验
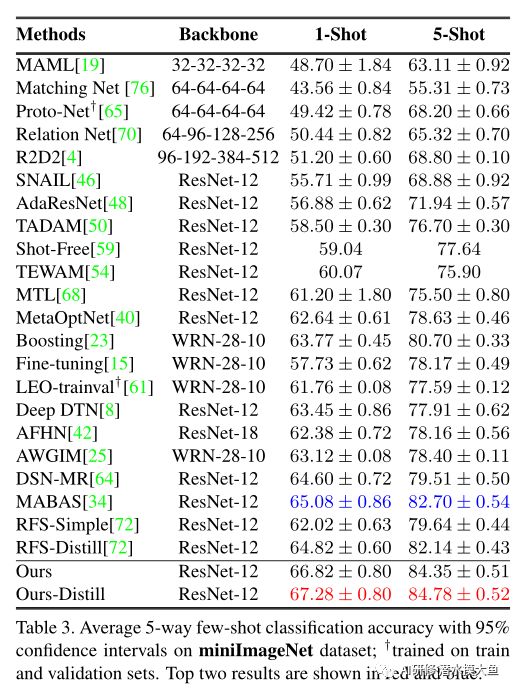
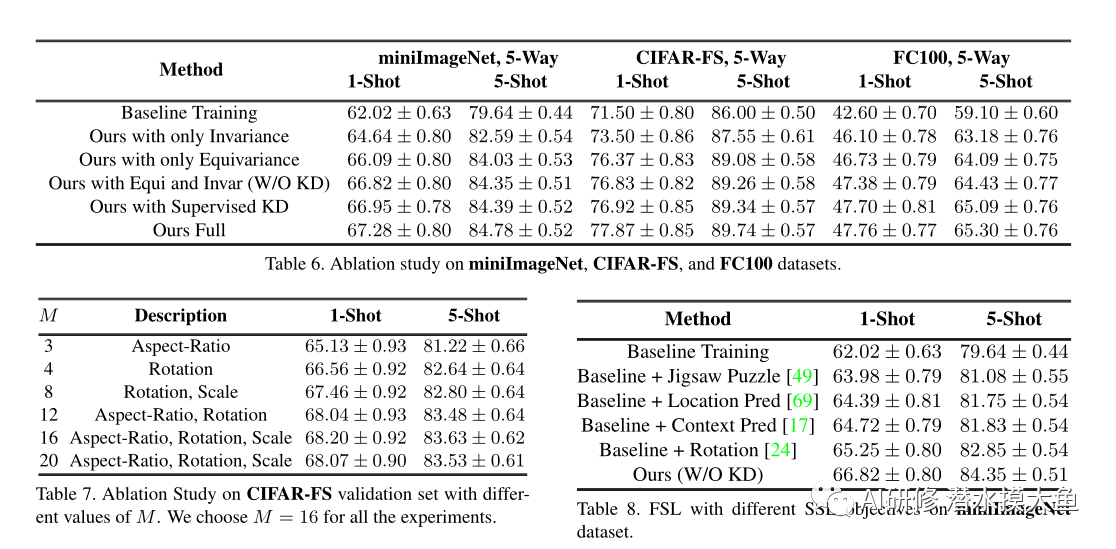















 3515
3515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









