







循环神经网络(Recurrent Neural Network,RNN)可以通过许多不同的方式建立,但就像几乎所有函数都可以被认为是前馈网络,基本上任何涉及循环的函数可以被认为是一个循环神经网络。它的基本结构以及其展开的理解如下图所示:
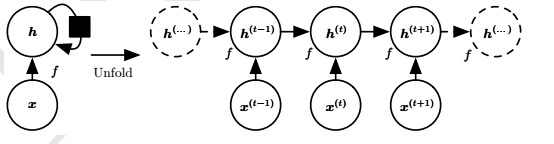
实际上这个结构的出现很自然,如果在做机器翻译,对于输入的句子的长度问题,如果普通的神经网络固定了神经元是无法处理的,那么取自卷积神经网络里的思想,适合部分那么一定适合全局,所以–滑动起来吧!
即同一网络被视为展开的计算图,其中每个节点现在与一个特定的时间实例相关联。其中U和W都是权重:
h
(
t
)
=
f
(
U
x
t
+
W
h
(
t
−
1
)
)
\mathrm h^{(t)}=f(U\mathrm{x}_t+W\mathrm h^{(t-1)})
h(t)=f(Uxt+Wh(t−1))
每一个h都可以通过softmax或者Sigmoid进行输出,即可以预测到在前几项出现了的情况下,下一项出现的概率。训练完成后,同样可以进行预测。
之前在神经网络中证明过如果加深网络的话可能会造成梯度消失或者梯度爆炸(由于梯度的计算依赖链式法则,最后相当与对梯度的不断求导,如果恒小于1or大于1都会出现梯度问题),在RNN中也是,这就导致了RNN不能处理长期依赖数据的问题,即随着时间的推移,以前的数据会影响非常小,且时间间隔非常小,很难处理超过10的序列,但是在比如翻译的应用中,往往需要处理很长的句子,梯度消失就很成问题了。不过只要有需求就会有技术!其中一个RNN的变体–Long Short-Term Memory(LSTM)的表现在处理这个问题上非常好。它主要是采用了模块记忆体,将数据给记录下来,从而可以保存比较长时间的信息,具体的结构如下:
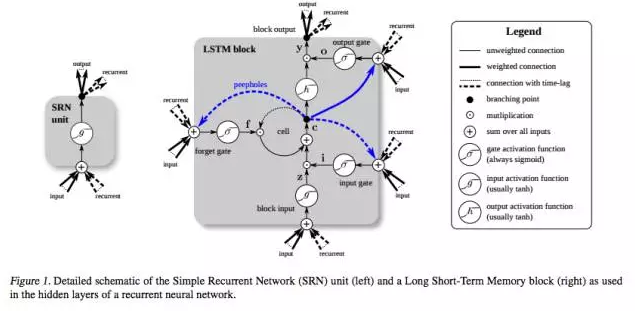
比照人脑的记忆运行,LSTM相比RNN它的结构特意的添加了:
遗忘机制(forgetting mechanism),即遗忘门,当新输入来时,它专注于需要记住哪些信息,以及需要丢弃哪些信息。
保存机制(saving mechanism),即输入门,用于保存信息。
所谓“门”用以控制输入的向量,即可以看成是一个普通的全连接层:
g
(
x
)
=
σ
(
W
x
+
b
)
g(\mathbf{x})=\sigma(W\mathbf{x}+\mathbf{b})
g(x)=σ(Wx+b)
回忆人类在面对事件时,总是依据现有事实再从以往经验中那些对当前境况有用的经验中提取有利的信息用以综合判断,解决事件。所以当新输入来时,往往需要先决定新输入中的哪部分信息是有用的,并将它们保存在自己的长期记忆体中,再搜索判断存于长期记忆体中的记忆哪些是对当前状态有用的,最后综合得出结果。于是可以看到整个结构图:
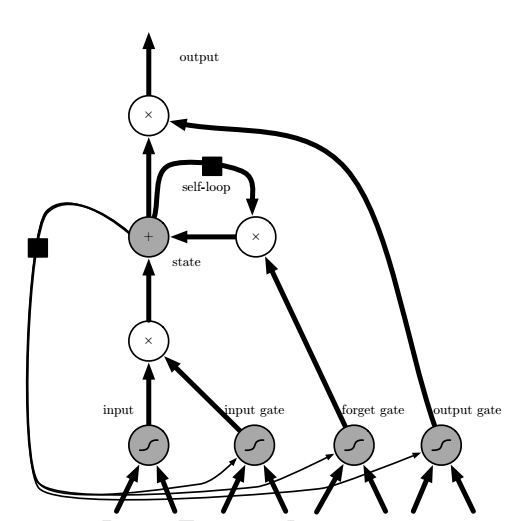
在上图中,可以看到这些细胞之间彼此循环相连用以代替一般循环网络中普通的隐藏单元,所有门控单元都具有Sigmoid非线性,而输入单元可具有任意的压缩非线性。其中黑色方块表示单个时间步的延迟。
它不仅有外部RNN的循环,还有内部状态单元的线性自环,因此它不仅仅是简单的向输入和循环单元的仿射变换之后施加一个逐元素的非线性。自环权重由循环门控制
f
i
(
t
)
=
σ
(
b
i
f
+
∑
U
f
x
(
t
)
+
∑
W
f
h
(
t
−
1
)
)
f_i^{(t)}=\sigma(b_i^f+\sum U^fx^{(t)}+\sum W^fh^{(t-1)})
fi(t)=σ(bif+∑Ufx(t)+∑Wfh(t−1))
g
i
(
t
)
=
σ
(
b
i
g
+
∑
U
g
x
(
t
)
+
∑
W
g
h
(
t
−
1
)
)
g_i^{(t)}=\sigma(b_i^g+\sum U^gx^{(t)}+\sum W^gh^{(t-1)})
gi(t)=σ(big+∑Ugx(t)+∑Wgh(t−1))
q
i
(
t
)
=
σ
(
b
i
q
+
∑
U
q
x
(
t
)
+
∑
W
q
h
(
t
−
1
)
)
q_i^{(t)}=\sigma(b_i^q+\sum U^qx^{(t)}+\sum W^qh^{(t-1)})
qi(t)=σ(biq+∑Uqx(t)+∑Wqh(t−1))
b,U,W分别是偏置,输入权重和遗忘门的循环权重。f,g,q分别是遗忘门和输入门,输出门。记忆体细胞的更新为:
c
t
=
f
t
∘
c
t
−
1
+
i
t
∘
c
~
t
\mathbf{c}_t=f_t\circ{\mathbf{c}_{t-1}}+i_t\circ{\mathbf{\tilde{c}}_t}
ct=ft∘ct−1+it∘c~t
输出为
h
t
=
σ
(
W
⋅
[
h
t
−
1
,
x
t
]
+
b
)
∘
tanh
(
c
t
)
\mathbf{h}_t=\sigma(W\cdot[\mathbf{h}_{t-1},\mathbf{x}_t]+\mathbf{b})\circ \tanh(\mathbf{c}_t)
ht=σ(W⋅[ht−1,xt]+b)∘tanh(ct)
然后通过反向传播调整参数训练网络即可。
训练技巧指南
- 隐层维度从128开始调比较好。
- batch size不是越大越好,合适最好。
- dropout最好放在输入-rnn和rnn-输出的位置。(http://arxiv.org/abs/1409.2329)
- LSTM的forget gate的bias用1或者更大做初始化,往往容易得到好结果。
- 一轮加正则,一轮不加正则。
为什么有些地方用Sigmoid,有些地方用tanh
- Sigmoid用在各种gate门上,用于产生概率(0-1)
- tanh用于转态的输出,对梯度消失有一定的作用(也可以换成别的激活函数)
LSTM的hidden和cell存储什么?
hidden存到当前时间步的所有信息,cell存将来时间步中可能需要的特定信息。
LSTM的参数个数
4(mh+h2+h),m是输入向量的尺寸,h是输出向量的尺寸。
论加法与乘法。
为什么结构图中有些地方用了
∘
\circ
∘,有些地方用了
+
+
+呢?
乘法直观来讲是作为一种对信息某种控制的操作(比如乘0就消失,1不变,其他的数作放大缩小反向等),而加法可以看作是新信息叠加旧信息,这也就是lstm为什么相对与rnn来说可以解决梯度消失的问题,+受到梯度连X的消失要小,使信息能够留得更加久一点。当然了,lstm的设置肯定不会仅仅从直观来判断,如果把两者进行比较会发现如果不这样做将没办法解决梯度问题。
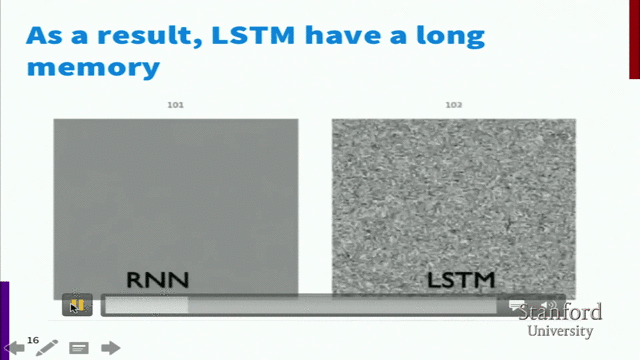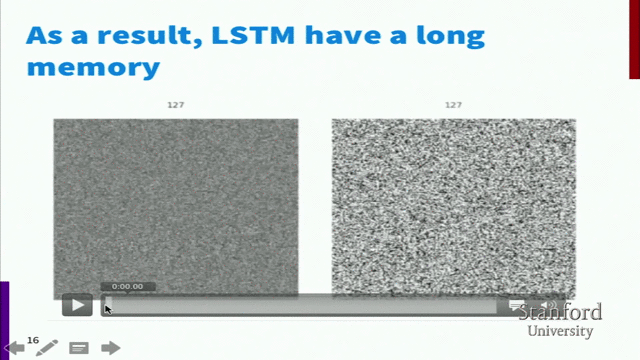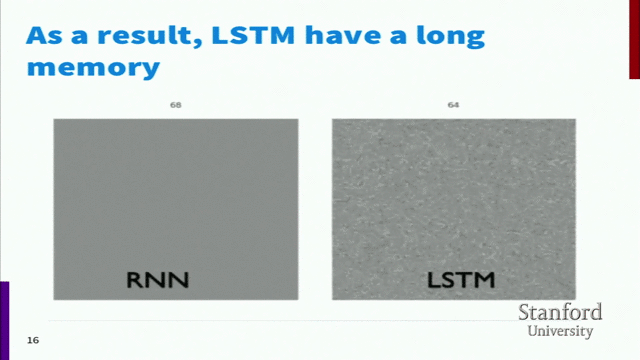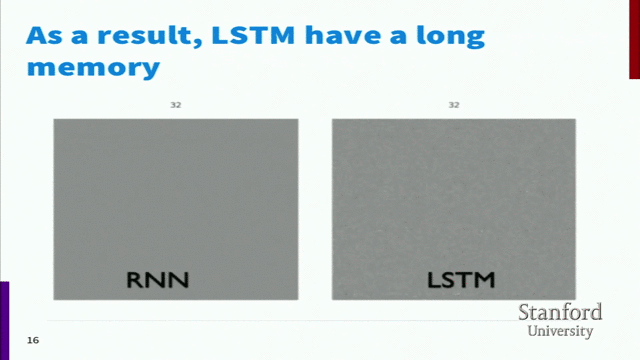
为什么记忆要分长期记忆和有利记忆,而不是直接用同一种记忆呢?
门控递归单元(Gated Recurrent Units,GRU)本质上就是一个没有输出门的LSTM,因此它在每个时间步都会将记忆单元中的所有内容写入整体网络,即直接使用了同一种记忆。具体的实现区别在于GRU单个门控同时控制遗忘因子和更新状态单元的决定。
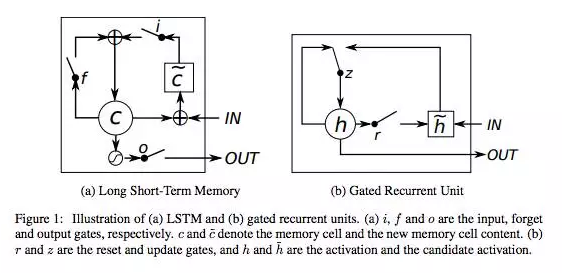
输出更新的方式变为:
h
i
(
t
)
=
u
i
(
t
−
1
)
h
i
(
t
−
1
)
+
(
1
−
u
i
(
t
−
1
)
)
σ
(
b
i
+
∑
U
x
(
t
)
+
∑
W
r
(
t
−
1
)
h
(
t
−
1
)
)
h_i^{(t)}=u_i^{(t-1)}h_i^{(t-1)}+(1-u_i^{(t-1)})\sigma(b_i+\sum Ux^{(t)}+\sum Wr^{(t-1)}h^{(t-1)})
hi(t)=ui(t−1)hi(t−1)+(1−ui(t−1))σ(bi+∑Ux(t)+∑Wr(t−1)h(t−1))其中u是更新门(Update Gate),r是复位门(Reset Gate)。
u
i
(
t
)
=
σ
(
b
i
u
+
∑
U
u
x
(
t
)
+
∑
W
u
h
(
t
)
)
u_i^{(t)}=\sigma(b_i^u+\sum U^ux^{(t)}+\sum W^uh^{(t)})
ui(t)=σ(biu+∑Uux(t)+∑Wuh(t))
r
i
(
t
)
=
σ
(
b
i
r
+
∑
U
r
x
(
t
)
+
∑
W
r
h
(
t
)
)
r_i^{(t)}=\sigma(b_i^r+\sum U^rx^{(t)}+\sum W^rh^{(t)})
ri(t)=σ(bir+∑Urx(t)+∑Wrh(t))
LSTM和GRU的不同
- LSTM三个输入,两个输出。GRU两个输入,一个输出即为state
- LSTM三个门,输入输出忘记门。GRU两个门,reset,update门
- update就类似与input和forget门
- GRU参数少,训练更快,相比之下需要的数据量少
- 但如果数据足够,LSTM的效果会更好些。
BRNN: 在很多情况下只知道以前的数据还不够,还需要有关未来的信息。
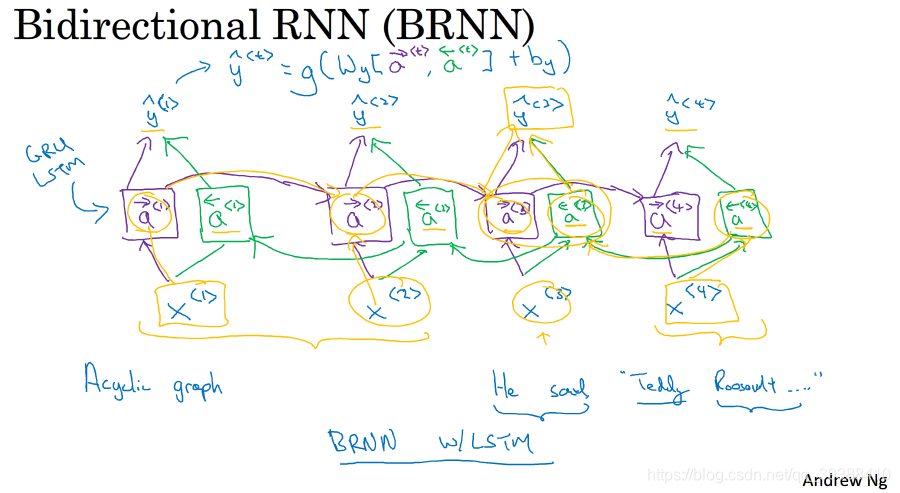
即在RNN的基础上,进行从左到右,再右到左,再才输出y,得到结果。
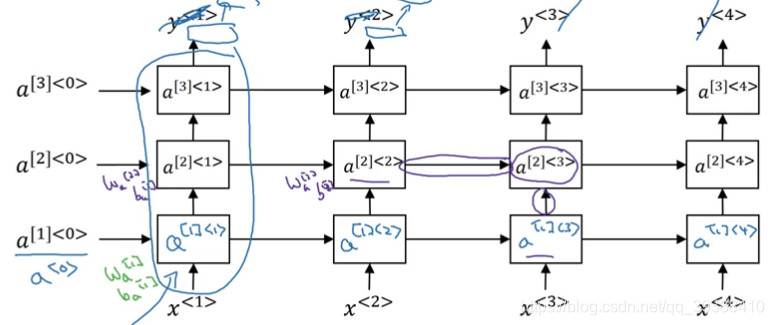
Deep RNN:
深度RNN就是累积多个单元呗。每个单元的计算都各来自有左边的箭头和下面的输入。
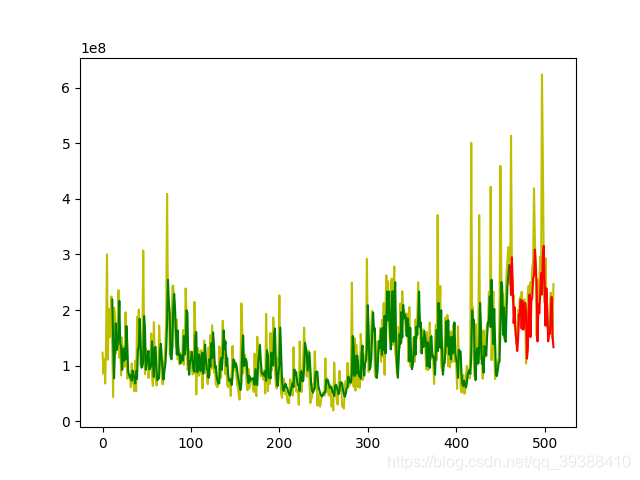
但是目前RNN的系列产品也只能在时序性问题上有出场机会了。CV被CNN牢牢占据,NLP的Transformer已经基本代替了RNN,甚至是这种记忆功能也可以使用memory network专用网络来解决。下面是博主自己的一个小项目,预测股票未来趋势线。(关于这个项目目前也有专业的量化方法,和利用强化学习等方法来实现–强化学习用于金融时序问题)
其他RNN!!
上面几种RNN都基本上属于用到不能用的模型了,几种新的变体如下:
- 加速版QRNN: https://arxiv.org/abs/1611.01576
- 并行版SRU: https://arxiv.org/abs/1709.02755
- 独立版IndRNN: https://arxiv.org/abs/1803.04831
- 遗忘门JANET: https://arxiv.org/abs/1804.04849
LSTM应用:
基于keras的时间序列预测
from keras.layers.core import Dense, Activation, Dropout
from keras.layers.recurrent import LSTM
from keras.models import Sequential
#载入自己数据,并进行基本的数据切分和归一化预处理
X_train, y_train, X_test, y_test = load_data('text.csv')
model = Sequential()
model.add(LSTM(input_shape=(None, 1), return_sequences=True, units=50))
model.add(Dropout(0.2))
model.add(LSTM(100,return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(units=1))
model.add(Activation("linear"))
model.compile(loss="mse", optimizer="rmsprop")
print ("Compilation Time : ", time.time() - start)
model.fit(X_train,y_train,batch_size=50,epochs=20,validation_split=0.05)
#重载数据用以画图
f=open('text.csv')
df=pd.read_csv(f)
data=np.array(df[kdata])
data=data[::-1]
#预测数据并画图
predicted = model.predict(X_test)
print(predicted)
predicted = np.reshape(predicted, (predicted.size,))
plt.plot(data,'y')
plt.plot(list(range(len(data),len(data)+len(X_test))),predicted,'b')
plt.show()
dongtai:https://towardsdatascience.com/animated-rnn-lstm-and-gru-ef124d06cf45

















 1506
1506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









