







 本文介绍了如何使用AzureMachineLearning(AzureML_py)环境中的Python代码训练一个线性回归模型,以预测狗狗的boot_size,基于给定的harness_size数据。作者展示了如何创建模型、拟合数据、可视化结果,并将模型保存以便后续预测。
本文介绍了如何使用AzureMachineLearning(AzureML_py)环境中的Python代码训练一个线性回归模型,以预测狗狗的boot_size,基于给定的harness_size数据。作者展示了如何创建模型、拟合数据、可视化结果,并将模型保存以便后续预测。
练习:训练一个模型, 基于适合狗的护具的大小来预测适合狗的靴子尺寸
环境: azureml_py
import pandas
!wget https://raw.githubusercontent.com/MicrosoftDocs/mslearn-introduction-to-machine-learning/main/graphing.py
!wget https://raw.githubusercontent.com/MicrosoftDocs/mslearn-introduction-to-machine-learning/main/Data/doggy-boot-harness.csv
!pip install statsmodels
# Make a dictionary of data for boot sizes and harness sizes in cm
data = {
'boot_size' : [ 39, 38, 37, 39, 38, 35, 37, 36, 35, 40,
40, 36, 38, 39, 42, 42, 36, 36, 35, 41,
42, 38, 37, 35, 40, 36, 35, 39, 41, 37,
35, 41, 39, 41, 42, 42, 36, 37, 37, 39,
42, 35, 36, 41, 41, 41, 39, 39, 35, 39
],
'harness_size': [ 58, 58, 52, 58, 57, 52, 55, 53, 49, 54,
59, 56, 53, 58, 57, 58, 56, 51, 50, 59,
59, 59, 55, 50, 55, 52, 53, 54, 61, 56,
55, 60, 57, 56, 61, 58, 53, 57, 57, 55,
60, 51, 52, 56, 55, 57, 58, 57, 51, 59
]
}
# Convert it into a table using pandas
dataset = pandas.DataFrame(data)
dataset
| boot_size | harness_size | |
|---|---|---|
| 0 | 39 | 58 |
| 1 | 38 | 58 |
| 2 | 37 | 52 |
| 3 | 39 | 58 |
| 4 | 38 | 57 |
| 5 | 35 | 52 |
| 6 | 37 | 55 |
| 7 | 36 | 53 |
| 8 | 35 | 49 |
| 9 | 40 | 54 |
| 10 | 40 | 59 |
| 11 | 36 | 56 |
| 12 | 38 | 53 |
| 13 | 39 | 58 |
| 14 | 42 | 57 |
| 15 | 42 | 58 |
| 16 | 36 | 56 |
| 17 | 36 | 51 |
| 18 | 35 | 50 |
| 19 | 41 | 59 |
| 20 | 42 | 59 |
| 21 | 38 | 59 |
| 22 | 37 | 55 |
| 23 | 35 | 50 |
| 24 | 40 | 55 |
| 25 | 36 | 52 |
| 26 | 35 | 53 |
| 27 | 39 | 54 |
| 28 | 41 | 61 |
| 29 | 37 | 56 |
| 30 | 35 | 55 |
| 31 | 41 | 60 |
| 32 | 39 | 57 |
| 33 | 41 | 56 |
| 34 | 42 | 61 |
| 35 | 42 | 58 |
| 36 | 36 | 53 |
| 37 | 37 | 57 |
| 38 | 37 | 57 |
| 39 | 39 | 55 |
| 40 | 42 | 60 |
| 41 | 35 | 51 |
| 42 | 36 | 52 |
| 43 | 41 | 56 |
| 44 | 41 | 55 |
| 45 | 41 | 57 |
| 46 | 39 | 58 |
| 47 | 39 | 57 |
| 48 | 35 | 51 |
| 49 | 39 | 59 |
我们希望使用"harness size"来估计"boot size"。这意味着’ harness_size '是我们的input。我们需要一个模型来处理输入并对boot size输出)做出自己的估计。
普通最小二乘法Ordinary Least Squares (OLS)
示例: Linear Regression Example — scikit-learn 1.4.0 documentation
这里使用一个现有的库来创建我们的模型, 但是我们还不训练它
import statsmodels.formula.api as smf
# 首先, 我们使用一种特殊语法定义公式, 说明boot_size由harness_size解释
formula = "boot_size ~ harness_size"
model = smf.ols(formula = formula, data = dataset)
# 已经创建了模型, 但它没有内部参数的设置
if not hasattr(model, 'params'):
print("Model selected but it does not have parameters set. We need to train it!")
OLS模型有两个参数(斜率和偏移量), 但这些参数还没有在我们的模型中设置。我们需要训练我们的模型来找到这些值, 这样模型就可以根据狗的护具尺寸可靠地估计狗的靴子尺寸。
fitted_model = model.fit()
# 现在已拟合, 输出我们模型的信息
print("The following model parameters have been found:\n" +
f"Line slope: {fitted_model.params[1]}\n"+
f"Line Intercept: {fitted_model.params[0]}")
The following model parameters have been found:
Line slope: 0.5859254167382711
Line Intercept: 5.719109812682577
import matplotlib.pyplot as plt
# 显示数据点的散点图, 并添加拟合线
plt.scatter(dataset["harness_size"], dataset["boot_size"])
plt.plot(dataset["harness_size"], fitted_model.params[1] * dataset["harness_size"] + fitted_model.params[0], 'r', label='Fitted line')
# 添加标签和图例
plt.xlabel("harness_size")
plt.ylabel("boot_size")
plt.legend()

# 预测护具大小为61.4时对应的靴子大小
harness_size = { 'harness_size' : [61.4] }
approximate_boot_size = fitted_model.predict(harness_size)
print("Estimated approximate_boot_size:")
print(approximate_boot_size[0])
Estimated approximate_boot_size:
41.694930400412424
输入和输出

训练的目标是改进模型, 使它可以进行高质量的估计或预测
模型不会自行训练, 它们使用数据和两段代码(目标函数和优化器)进行训练
目标函数判断模型表现得不错(正确地估计了靴子尺寸)还是糟糕
在训练期间, 模型进行预测, 目标函数计算其性能。优化器是随后更改模型参数的代码, 以便模型下次会做得更好, 通常可以使用开源框架
目标、数据和优化器只是训练模型的一种手段, 训练完成后, 就不再需要它们
训练只会改变模型内部的参数值;它不会改变使用的模型类型
练习:可视化输入和输出
这次,我们从文件加载数据,对其进行过滤,并将其绘制成图形。为了更好地了解模型构建或局限性
这里使用 Pandas 加载数据
import pandas
!wget https://raw.githubusercontent.com/MicrosoftDocs/mslearn-introduction-to-machine-learning/main/graphing.py
!wget https://raw.githubusercontent.com/MicrosoftDocs/mslearn-introduction-to-machine-learning/main/Data/doggy-boot-harness.csv
dataset = pandas.read_csv('doggy-boot-harness.csv')
# 数据很多,使用head()只打印前几行
dataset.head()
| boot_size | harness_size | sex | age_years | |
|---|---|---|---|---|
| 0 | 39 | 58 | male | 12.0 |
| 1 | 38 | 58 | male | 9.6 |
| 2 | 37 | 52 | female | 8.6 |
| 3 | 39 | 58 | male | 10.2 |
| 4 | 38 | 57 | male | 7.8 |
按列筛选数据
print("Harness sizes")
print(dataset.harness_size)
del dataset["sex"]
del dataset["age_years"]
print("\nAvailable columns after deleting sex and age information:")
print(dataset.columns.values)

Available columns after deleting sex and age information:
[‘boot_size’ ‘harness_size’]
print("TOP OF TABLE")
print(dataset.head())
print("\nBOTTOM OF TABLE")
print(dataset.tail())
print(f"We have {len(dataset)} rows of data")
is_small = dataset.harness_size < 55
print("\nWhether the dog's harness was smaller than size 55:")
print(is_small)

data_from_small_dogs = dataset[is_small]
print("\nData for dogs with harness smaller than size 55:")
print(data_from_small_dogs)
print(f"\nNumber of dogs with harness size less than 55: {len(data_from_small_dogs)}")

上面也可写作
data_from_small_dogs = dataset[dataset.boot_size < 55].copy()
对copy()的调用是可选的,但有助于避免在更复杂的场景中出现意外行为
Python 直接赋值、浅拷贝和深度拷贝
Python 字典(Dictionary) copy()方法 | 菜鸟教程 (runoob.com)
Python 直接赋值、浅拷贝和深度拷贝解析 | 菜鸟教程 (runoob.com)
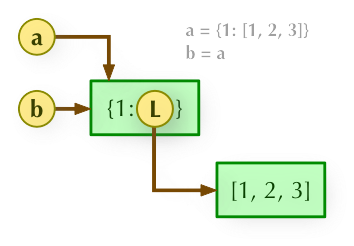
1、b = a: 赋值引用,a 和 b 都指向同一个对象。
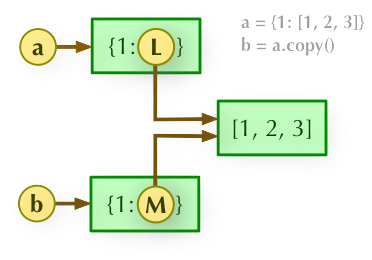
2、b = a.copy(): 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。
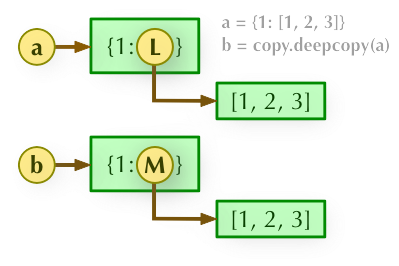
浅拷贝:深拷贝父对象(一级目录),子对象(二级目录)不拷贝,还是引用b = copy.deepcopy(a): 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。
import matplotlib.pyplot as plt
plt.scatter(data_smaller_paws["harness_size"], data_smaller_paws["boot_size"])
plt.xlabel("harness_size")
plt.ylabel("boot_size")
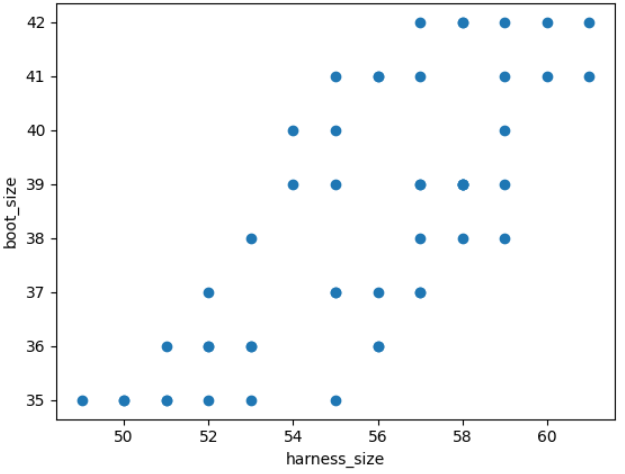
某些客户可能希望以英寸为单位,而不是以厘米为单位
那么我们需要创建新的横坐标
data_smaller_paws['harness_size_imperial'] = data_smaller_paws.harness_size / 2.54
plt.scatter(data_smaller_paws["harness_size_imperial"], data_smaller_paws["boot_size"])
plt.xlabel("harness_size_imperial")
plt.ylabel("boot_size")

如何使用模型
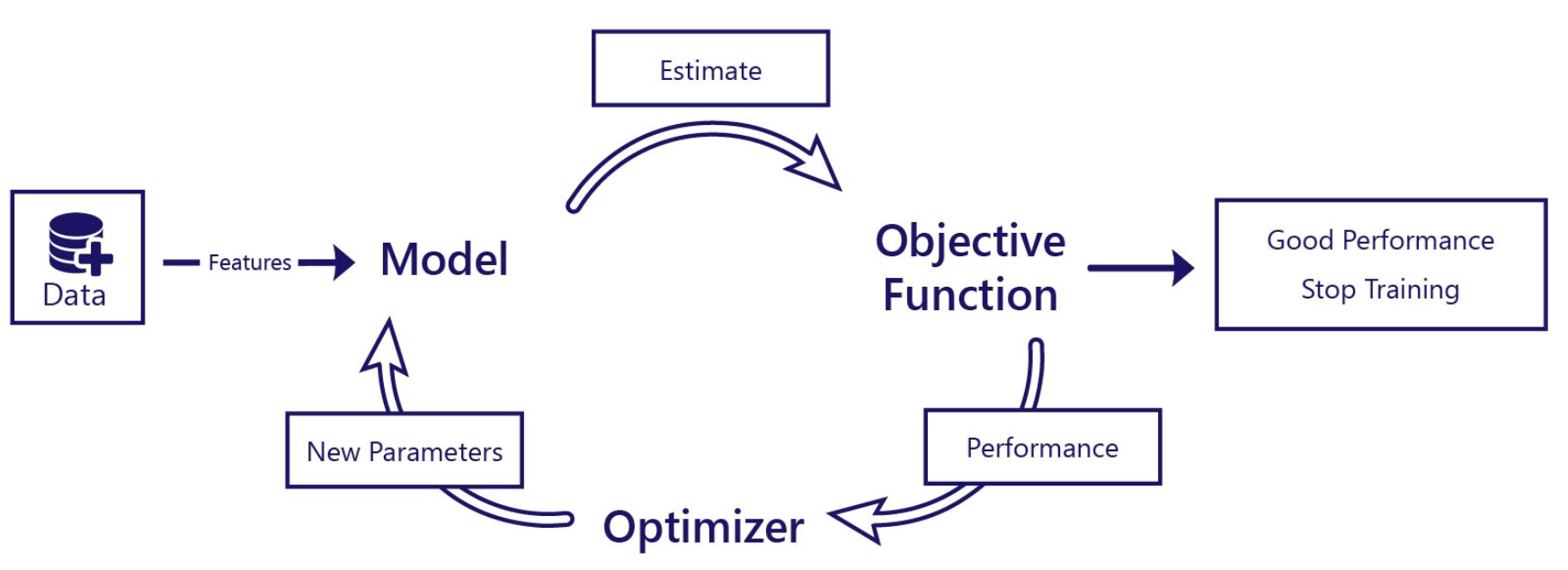
在训练过程中,目标函数通常需要知道模型的输出和正确答案是什么。这些值称为标签。在我们的场景中,如果我们的模型预测了靴子大小,则靴子大小就是我们的标签。
模型完成训练后,可以将其单独保存到文件中。我们不再需要原始数据、目标函数或模型优化器。当我们想使用模型时,我们可以从磁盘加载它,为其提供新数据,并返回预测。
对新数据使用经过训练的模型
在我们刚刚学习机器学习时,构建、训练然后使用模型是很常见的;但在现实世界中,我们不希望每次都要进行预测时就训练模型。
- 创建基本模型
- 将其保存到磁盘
- 从磁盘加载
- 使用它来预测不在训练数据集中的狗
正如我们之前所做的那样,创建一个简单的线性回归模型,并在我们的数据集上对其进行训练
import statsmodels.formula.api as smf
model = smf.ols(formula = "boot_size ~ harness_size", data = data).fit()
保存并加载模型
import joblib
model_filename = './avalanche_dog_boot_model.pkl'
joblib.dump(model, model_filename)
print("Model saved!")
Joblib: running Python functions as pipeline jobs — joblib 1.3.2 documentation
model_loaded = joblib.load(model_filename)
print("We have loaded a model with the following parameters:")
print(model_loaded.params)
We have loaded a model with the following parameters:
Intercept 5.719110
harness_size 0.585925
dtype: float64
实际应用场景
def load_model_and_predict(harness_size):
'''
This function loads a pretrained model.
It uses the model with the customer's dog's harness size
to predict the size of boots that will fit that dog.
harness_size: The dog harness size, in cm
'''
# Load the model from file and print basic information about it
loaded_model = joblib.load(model_filename)
print("We've loaded a model with the following parameters:")
print(loaded_model.params)
inputs = {"harness_size":[harness_size]}
# Use the model to make a prediction
predicted_boot_size = loaded_model.predict(inputs)[0]
return predicted_boot_size
def check_size_of_boots(selected_harness_size, selected_boot_size):
'''
Calculates whether the customer has chosen a pair of doggy boots that
are a sensible size. This works by estimating the dog's actual boot
size from their harness size.
This returns a message for the customer that should be shown before
they complete their payment
selected_harness_size: The size of the harness the customer wants to buy
selected_boot_size: The size of the doggy boots the customer wants to buy
'''
# Estimate the customer's dog's boot size
estimated_boot_size = load_model_and_predict(selected_harness_size)
# Round to the nearest whole number because we don't sell partial sizes
estimated_boot_size = int(round(estimated_boot_size))
# Check if the boot size selected is appropriate
if selected_boot_size == estimated_boot_size:
return f"Great choice! We think these boots will fit your avalanche dog well."
if selected_boot_size < estimated_boot_size:
return "The boots you have selected might be TOO SMALL for a dog as "\
f"big as yours. We recommend a doggy boots size of {estimated_boot_size}."
if selected_boot_size > estimated_boot_size:
return "The boots you have selected might be TOO BIG for a dog as "\
f"small as yours. We recommend a doggy boots size of {estimated_boot_size}."
# Practice using our new warning system
check_size_of_boots(selected_harness_size=55, selected_boot_size=39)

















 687
687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











