







MMDeploy部署实战系列【第五章】:Windows下Release x64编译mmdeploy(C++),对TensorRT模型进行推理
⭐️ ⭐️ ⭐️ 这个系列是一个随笔,是我走过的一些路,有些地方可能不太完善。如果有那个地方没看懂,评论区问就可以,我给补充。
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
目录:
0️⃣ mmdeploy源码安装 (转换faster rcnn r50/yolox为tensorrt,并进行推理)_gy77
内容:一文包含了在Linux系统下安装mmdeploy模型转换环境,模型转换为TensorRT,在Linux,Windows下模型推理,推理结果展示。
1️⃣ MMDeploy部署实战系列【第一章】:Docker,Nvidia-docker安装_gy77
内容:docker/nvidia-docker安装,docker/nvidia-docker国内源,docker/nvidia-docker常用命令。
2️⃣ MMDeploy部署实战系列【第二章】:mmdeploy安装及环境搭建_gy77
内容:mmdeploy环境安装三种方法:源码安装,官方docker安装,自定义Dockerfile安装。
3️⃣ MMDeploy部署实战系列【第三章】:MMdeploy pytorch模型转换onnx,tensorrt_gy77
内容:如何查找pytorch模型对应的部署配置文件,模型转换示例:mmcls:resnext50,mmdet:yolox-s,faster rcnn50。
4️⃣ MMDeploy部署实战系列【第四章】:onnx,tensorrt模型推理_gy77
内容:在linux,windows环境下推理,Windows下推理环境安装,推理速度对比,显存对比,可视化展示。
5️⃣ MMDeploy部署实战系列【第五章】:Windows下Release x64编译mmdeploy(C++),对TensorRT模型进行推理_gy77
内容:Windows下环境安装编译环境,编译c++ mmdeploy,编译c++ mmdeploy demo,运行实例。
6️⃣ MMDeploy部署实战系列【第六章】:将编译好的MMdeploy导入到自己的项目中 (C++)_gy77
内容:Windows下环境导入我们编译好的mmdeploy 静态/动态库。
⭐️ ⭐️ ⭐️ 配置环境变量 约定:
$env:TENSORRT_DIR = "F:\env\TensorRT"
# Windows: 上边命令代表新建一个系统变量,变量名为:TENSORRT_DIR 变量值为:F:\env\TensorRT
# Linux:
vim ~/.bashrc
#在最后一行加入
export TENSORRT_DIR=/home/gy77/TensorRT
source ~/.bashrc
$env:Path = "F:\env\TensorRT\lib"
# Windows: 上边命令代表在系统变量Path下,新加一个值为:F:\env\TensorRT\lib
# Linux:
vim ~/.bashrc
#在最后一行加入, :$PATH代表在原先PATH环境变量基础上添加/home/gy77/TensorRT/lib ,注意PATH大小写。
export PATH=/home/gy77/TensorRT/lib:$PATH
source ~/.bashrc
下面是正文:
官方教程: Win10 下构建方式 — mmdeploy 0.6.0 文档
安装torch,mmcv
打开 Anaconda Powershell Prompt
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
pip install mmcv-full==1.5.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.8/index.html
安装OpenCV
-
下载 OpenCV 3+,Releases - OpenCV 。
-
您可以下载并安装 OpenCV 预编译包到指定的目录下。也可以选择源码编译安装的方式
-
在安装目录中,找到
OpenCVConfig.cmake,并把它的路径添加到环境变量PATH中。像这样:
$env:Path = "E:\env\opencv455\opencv\build"
$env:Path = "F:\env\opencv455\opencv\build\x64\vc15\bin"
安装pplcv
pplcv 是 openPPL 开发的高性能图像处理库。 此依赖项为可选项,只有在 cuda 平台下,才需安装。
git clone https://github.com/openppl-public/ppl.cv.git
cd ppl.cv
git checkout tags/v0.7.0 -b v0.7.0
$env:PPLCV_DIR = "E:\env\ppl.cv"
mkdir pplcv-build
cd pplcv-build
cmake .. -G "Visual Studio 16 2019" -T v142 -A x64 -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=install -DPPLCV_USE_CUDA=ON -DPPLCV_USE_MSVC_STATIC_RUNTIME=OFF
cmake --build . --config Release -- /m
cmake --install . --config Release
cd ../..
可能会报错:【CUDA】No CUDA toolset found.
解决方法参考:cMake编译yolov5报错:【CUDA】No CUDA toolset found.
安装TensorRT
🔸 登录 NVIDIA 官网,从这里选取并下载 TensorRT tar 包。要保证它和您机器的 CPU 架构以及 CUDA 版本是匹配的。您可以参考这份 指南 安装 TensorRT。
🔸 这里也有一份 TensorRT 8.2 GA Update 2 在 Windows x86_64 和 CUDA 11.x 下的安装示例,供您参考。首先,点击此处下载 CUDA 11.x TensorRT 8.2.3.0。然后,根据如下命令,安装并配置 TensorRT 以及相关依赖。
cd \the\path\of\tensorrt\zip\file
Expand-Archive TensorRT-8.2.3.0.Windows10.x86_64.cuda-11.4.cudnn8.2.zip .
pip install E:\TensorRT-8.2.3.0.Windows10.x86_64.cuda-11.4.cudnn8.2\TensorRT-8.2.3.0\python\tensorrt-8.2.3.0-cp37-none-win_amd64.whl
$env:TENSORRT_DIR = "F:\env\TensorRT-8.2.3.0.Windows10.x86_64.cuda-11.4.cudnn8.2\TensorRT-8.2.3.0"
$env:Path = "F:\env\TensorRT-8.2.3.0.Windows10.x86_64.cuda-11.4.cudnn8.2\TensorRT-8.2.3.0\lib"
pip install pycuda
安装cudnn
🔸 从 cuDNN Archive 中选择和您环境中 CPU 架构、CUDA 版本以及 TensorRT 版本配套的 cuDNN。以前文 TensorRT 安装说明为例,它需要 cudnn8.2。因此,可以下载 CUDA 11.x cuDNN 8.2
🔸 解压压缩包,并设置环境变量
cd \the\path\of\cudnn\zip\file
Expand-Archive cudnn-11.3-windows-x64-v8.2.1.32.zip .
$env:CUDNN_DIR="F:\env\cudnn-11.3-windows-x64-v8.2.1.32\cuda"
$env:Path = "F:\env\cudnn-11.3-windows-x64-v8.2.1.32\cuda\bin"
编译mmdeploy
cd $env:MMDEPLOY_DIR
mkdir build
cd build
cmake .. -G "Visual Studio 16 2019" -A x64 -T v142 -DMMDEPLOY_BUILD_SDK=ON -DMMDEPLOY_TARGET_DEVICES="cuda" -DMMDEPLOY_TARGET_BACKENDS="trt" -DMMDEPLOY_CODEBASES="all" -Dpplcv_DIR="F:\env\ppl.cv\pplcv-build\install\lib\cmake\ppl" -DTENSORRT_DIR="F:\env\TensorRT-8.2.3.0.Windows10.x86_64.cuda-11.4.cudnn8.2\TensorRT-8.2.3.0" -DCUDNN_DIR="F:\env\cudnn-11.3-windows-x64-v8.2.1.32\cuda"
cmake --build . --config Release -- /m
cmake --install . --config Release
⚠️ 很大几率会报错,在F:/gy77/mmdeploy/third_party/spdlog目录下不包含CMakeLists.txt。
CMake Error at csrc/mmdeploy/core/CMakeLists.txt:15 (add_subdirectory):
The source directoryF:/gy77/mmdeploy/third_party/spdlog
does not contain a CMakeLists.txt file.
CMake Error at csrc/mmdeploy/core/CMakeLists.txt:16 (set_target_properties):
set_target_properties Can not find target to add properties to: spdlogCMake Error at cmake/MMDeploy.cmake:8 (install):
install TARGETS given target “spdlog” which does not exist.
Call Stack (most recent call first):
csrc/mmdeploy/core/CMakeLists.txt:18 (mmdeploy_export)
解决方法,把第三方库克隆下来,然后再cmake编译一下:
git clone有时候会新建个spdlog目录,导致变成 F:\gy77\mmdeploy\third_party\spdlog\spdlog… ,我们要用F:\gy77\mmdeploy\third_party\spdlog… 把目录下文件移动一下。
cd ..\third_party\spdlog
git clone https://github.com/gabime/spdlog.git
cd ..\..\build
$env:Path = "F:\\gy77\\mmdeploy\\build\\install\\bin"
cmake --build . --config Release -- /m 运行成功log
[F:\gy77\mmdeploy\build]$ cmake .. -G "Visual Studio 16 2019" -A x64 -T v142 -DMMDEPLOY_BUILD_SDK=ON -DMMDEPLOY_TARGET_DEVICES="cuda" -DMMDEPLOY_TARGET_BACKENDS="trt" -DMMDEPLOY_CODEBASES="all" -Dpplcv_DIR="F:\env\ppl.cv\pplcv-build\install\lib\cmake\ppl" -DTENSORRT_DIR="F:\env\TensorRT-8.2.3.0.Windows10.x86_64.cuda-11.4.cudnn8.2\TensorRT-8.2.3.0" -DCUDNN_DIR="F:\env\cudnn-11.3-windows-x64-v8.2.1.32\cuda"
-- CMAKE_INSTALL_PREFIX: F:/gy77/mmdeploy/build/install
-- Selecting Windows SDK version 10.0.19041.0 to target Windows 10.0.19043.
-- The C compiler identification is MSVC 19.29.30146.0
-- The CXX compiler identification is MSVC 19.29.30146.0
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working C compiler: F:/app/vs2019/VC/Tools/MSVC/14.29.30133/bin/Hostx64/x64/cl.exe - skipped
-- Detecting C compile features
-- Detecting C compile features - done
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: F:/app/vs2019/VC/Tools/MSVC/14.29.30133/bin/Hostx64/x64/cl.exe - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Found CUDA: C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.1 (found version "11.1")
-- The CUDA compiler identification is NVIDIA 11.1.74
-- Detecting CUDA compiler ABI info
-- Detecting CUDA compiler ABI info - done
-- Check for working CUDA compiler: C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.1/bin/nvcc.exe - skipped
-- Detecting CUDA compile features
-- Detecting CUDA compile features - done
-- Build TensorRT custom ops.
-- Found TensorRT headers at F:/env/TensorRT-8.2.3.0.Windows10.x86_64.cuda-11.4.cudnn8.2/TensorRT-8.2.3.0/include
-- Found TensorRT libs at F:/env/TensorRT-8.2.3.0.Windows10.x86_64.cuda-11.4.cudnn8.2/TensorRT-8.2.3.0/lib/nvinfer.lib;F:/env/TensorRT-8.2.3.0.Windows10.x86_64.cuda-11.4.cudnn8.2/TensorRT-8.2.3.0/lib/nvinfer_plugin.lib
-- Found TENSORRT: F:/env/TensorRT-8.2.3.0.Windows10.x86_64.cuda-11.4.cudnn8.2/TensorRT-8.2.3.0/include
-- OpenCV ARCH: x64
-- OpenCV RUNTIME: vc15
-- OpenCV STATIC: OFF
-- Found OpenCV: F:/env/opencv452/opencv/build (found version "4.5.2")
-- Found OpenCV 4.5.2 in F:/env/opencv452/opencv/build/x64/vc15/lib
-- You might need to add F:\env\opencv452\opencv\build\x64\vc15\bin to your PATH to be able to run your applications.
-- Build spdlog: 1.10.0
-- Performing Test CMAKE_HAVE_LIBC_PTHREAD
-- Performing Test CMAKE_HAVE_LIBC_PTHREAD - Failed
-- Looking for pthread_create in pthreads
-- Looking for pthread_create in pthreads - not found
-- Looking for pthread_create in pthread
-- Looking for pthread_create in pthread - not found
-- Check if compiler accepts -pthread
-- Check if compiler accepts -pthread - no
-- Found Threads: TRUE
-- Build type: Release
-- Found TensorRT headers at F:/env/TensorRT-8.2.3.0.Windows10.x86_64.cuda-11.4.cudnn8.2/TensorRT-8.2.3.0/include
-- Found TensorRT libs at F:/env/TensorRT-8.2.3.0.Windows10.x86_64.cuda-11.4.cudnn8.2/TensorRT-8.2.3.0/lib/nvinfer.lib;F:/env/TensorRT-8.2.3.0.Windows10.x86_64.cuda-11.4.cudnn8.2/TensorRT-8.2.3.0/lib/nvinfer_plugin.lib
-- build codebase: mmcls
-- build codebase: mmdet
-- build codebase: mmseg
-- build codebase: mmocr
-- build codebase: mmedit
-- build codebase: mmpose
-- build codebase: mmrotate
-- Configuring done
-- Generating done
-- Build files have been written to: F:/gy77/mmdeploy/build
cmake --install . --config Release 成功截图:
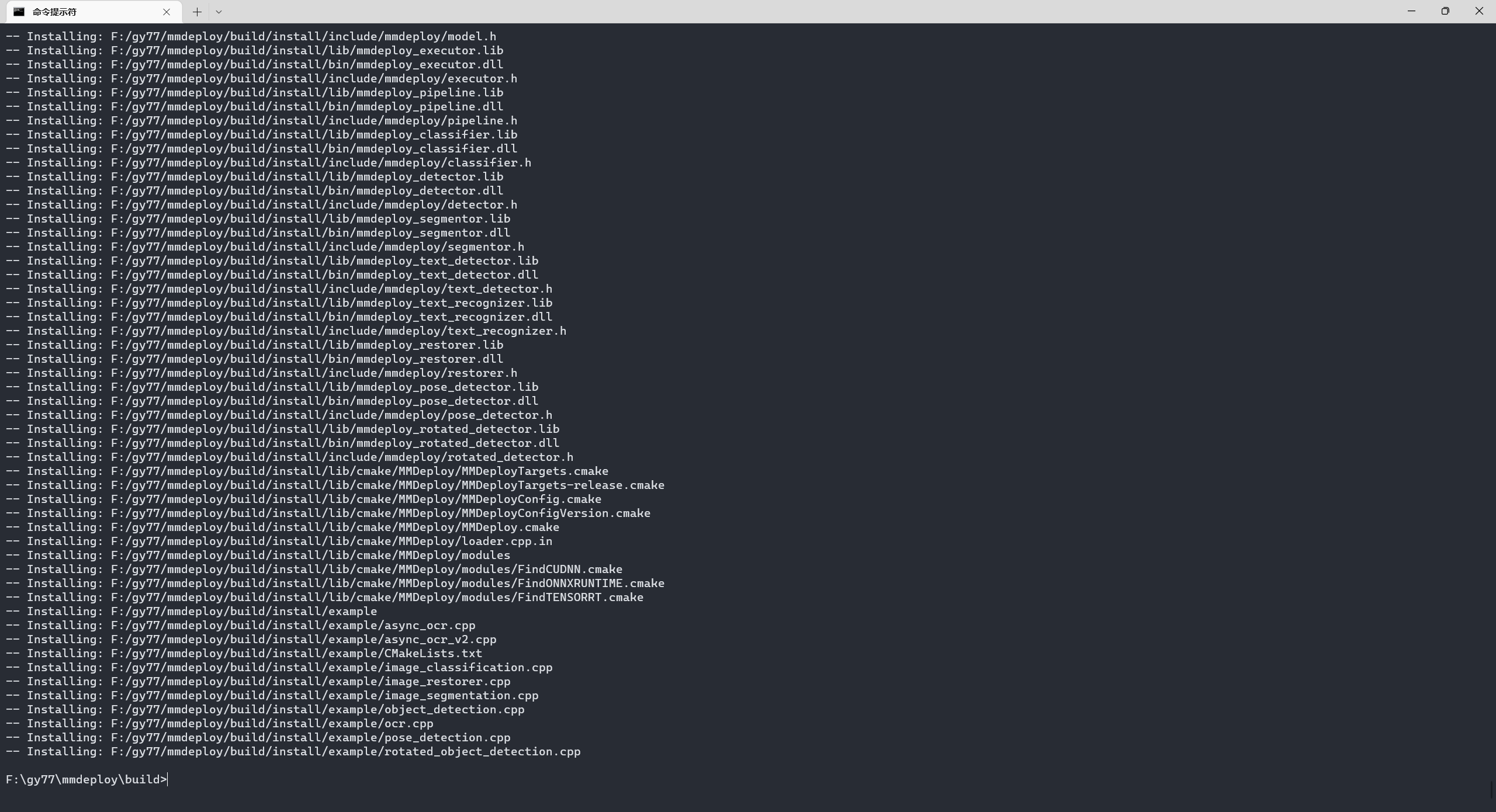
编译mmdeploy example
编译
cd $env:MMDEPLOY_DIR\build\install\example
mkdir build -ErrorAction SilentlyContinue
cd build
cmake .. -G "Visual Studio 16 2019" -A x64 -T v142 ` -DMMDeploy_DIR="F:\\gy77\\mmdeploy\\build\\install\\lib\\cmake\\MMDeploy"
cmake --build . --config Release -- /m
编译成功截图:
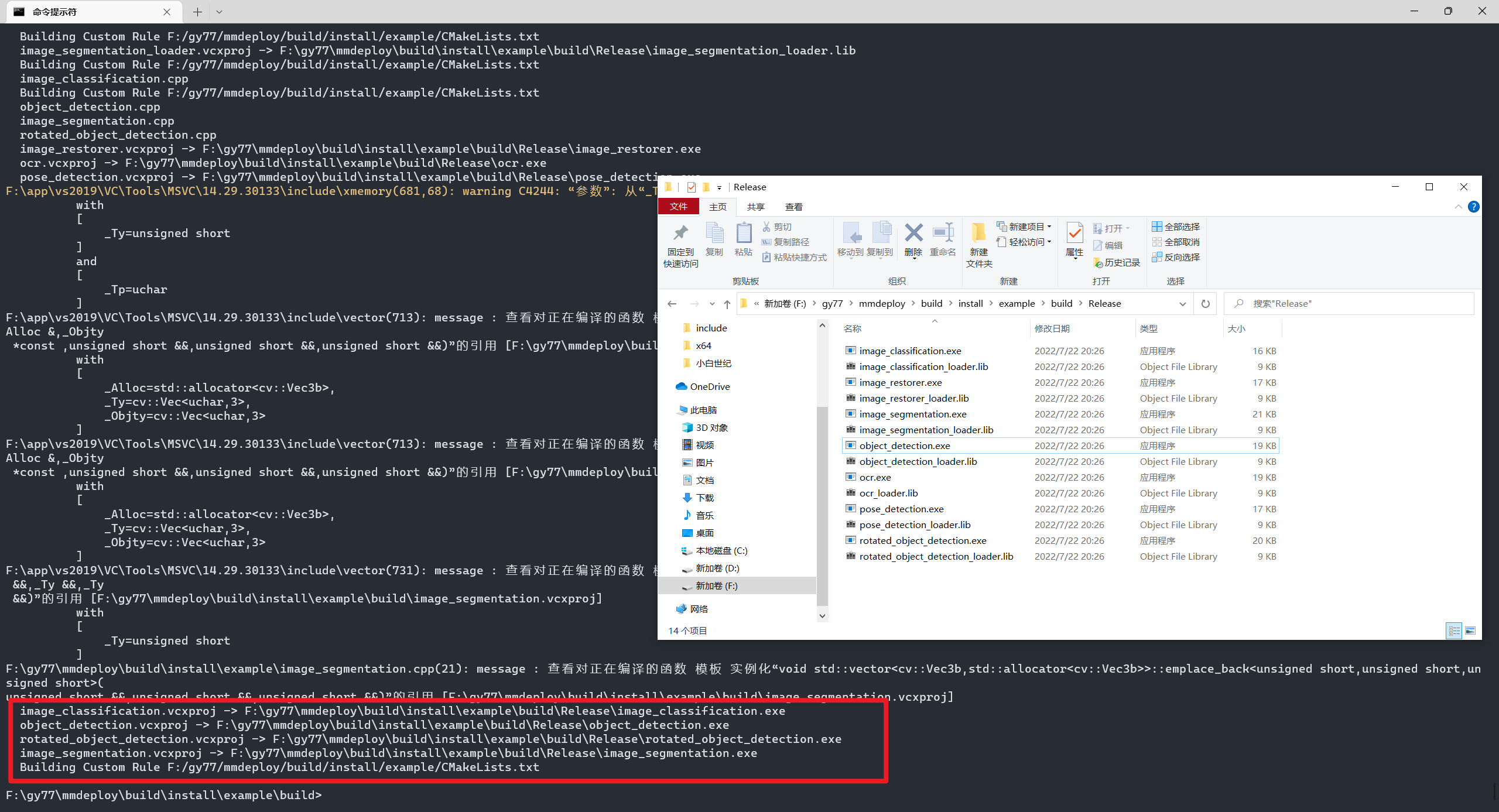
运行
传入三个参数:
运行设备:cuda
tensorrt模型文件夹:F:\mmdeploy_c_sdk_demo\models\yolox_s
要推理的图片:F:\gy77\mmdetection\demo\demo.jpg
cd Release
object_detection.exe cuda F:\mmdeploy_c_sdk_demo\models\yolox_s F:\\gy77\\mmdetection\\demo\\demo.jpg
运行成功日志:
loading mmdeploy_execution ...
loading mmdeploy_cpu_device ...
loading mmdeploy_cuda_device ...
loading mmdeploy_graph ...
loading mmdeploy_directory_model ...
[2022-07-27 09:48:07.665] [mmdeploy] [info] [model.cpp:95] Register 'DirectoryModel'
loading mmdeploy_transform ...
loading mmdeploy_cpu_transform_impl ...
loading mmdeploy_cuda_transform_impl ...
loading mmdeploy_transform_module ...
loading mmdeploy_trt_net ...
loading mmdeploy_net_module ...
loading mmdeploy_mmcls ...
loading mmdeploy_mmdet ...
loading mmdeploy_mmseg ...
loading mmdeploy_mmocr ...
loading mmdeploy_mmedit ...
loading mmdeploy_mmpose ...
loading mmdeploy_mmrotate ...
[2022-07-27 09:48:07.744] [mmdeploy] [info] [model.cpp:38] DirectoryModel successfully load model F:\mmdeploy_c_sdk_demo\models\yolox_s
[2022-07-27 09:48:08.410] [mmdeploy] [warning] [trt_net.cpp:24] TRTNet: Using an engine plan file across different models of devices is not recommended and is likely to affect performance or even cause errors.
[2022-07-27 09:48:09.007] [mmdeploy] [warning] [trt_net.cpp:24] TRTNet: TensorRT was linked against cuBLAS/cuBLAS LT 11.6.3 but loaded cuBLAS/cuBLAS LT 11.2.1
[2022-07-27 09:48:09.611] [mmdeploy] [warning] [trt_net.cpp:24] TRTNet: TensorRT was linked against cuBLAS/cuBLAS LT 11.6.3 but loaded cuBLAS/cuBLAS LT 11.2.1
bbox_count=100
box 0, left=221.97, top=176.78, right=456.58, bottom=382.68, label=13, score=0.9417
box 1, left=481.56, top=110.44, right=522.73, bottom=130.57, label=2, score=0.8955
box 2, left=431.35, top=105.25, right=484.05, bottom=132.74, label=2, score=0.8776
box 3, left=294.16, top=117.67, right=379.87, bottom=149.81, label=2, score=0.8764
box 4, left=191.56, top=108.98, right=299.04, bottom=155.19, label=2, score=0.8606
box 5, left=398.29, top=110.82, right=433.45, bottom=133.10, label=2, score=0.8603
box 6, left=608.44, top=111.58, right=637.68, bottom=137.55, label=2, score=0.8566
box 7, left=589.81, top=110.59, right=619.04, bottom=126.57, label=2, score=0.7685
box 8, left=167.67, top=110.90, right=211.25, bottom=140.14, label=2, score=0.7644
...
...
...
box 92, left=252.97, top=104.16, right=264.60, bottom=112.83, label=2, score=0.0128
box 93, left=217.55, top=103.95, right=252.98, bottom=117.21, label=2, score=0.0127
box 94, left=216.50, top=99.17, right=233.56, bottom=109.85, label=2, score=0.0125
box 95, left=482.39, top=110.96, right=506.86, bottom=128.41, label=2, score=0.0125
box 96, left=258.91, top=105.10, right=273.69, bottom=115.32, label=2, score=0.0122
box 97, left=553.22, top=103.66, right=562.15, bottom=120.34, label=2, score=0.0120
box 98, left=202.91, top=93.58, right=212.58, bottom=104.60, label=2, score=0.0118
box 99, left=397.86, top=110.84, right=433.34, bottom=133.45, label=7, score=0.0115



















 1080
1080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











