







 一、集成学习导读
一、集成学习导读

目录
2.1.1 自助采样法 (Bootstrap Sampling / Bootstrapping)
2.2.2 梯度提升 (Gradient Boosting)
2.3 堆叠法 (Stacking) 与 融合法 (Blending)
一、概述
集成学习 (ensemble learning),即分类器集成,构建多个学习器并通过某种集成方法组合它们来完成最终的学习任务,有时也被称为多分类器系统 (multi-classifier system)、基于委员会的学习 (committee-based learning) 等。一般结构是:先产生一组 “个体学习器”,再用某种策略将它们组合起来。组合策略主要有平均法、投票法和学习法等。集成学习主要用来提高模型(分类,预测,函数估计等)的性能,或用来降低模型选择不当的可能性。集成算法本身是一种监督学习算法,因为它可以被训练然后进行预测,组合的多个模型作为整体代表一个假设 (hypothesis)。
在 sklearn 官方文档 中,可以很容易找到各类集成算法 API 及其实现。
集成方法 本身并不是某种具体的方法或者是算法,只是一种训练机器学习模型的思路。它的含义只有一点,就是训练多个模型,然后将它们的结果汇聚在一起。集成方法将几种机器学习技术组合成一个预测模型的元算法,以达到减小方差 (bagging)、偏差 (boosting) 或改进预测 (stacking) 的效果。当然,也有说法 将多个分类器组合的方法 称为 集成方法 或 元算法。
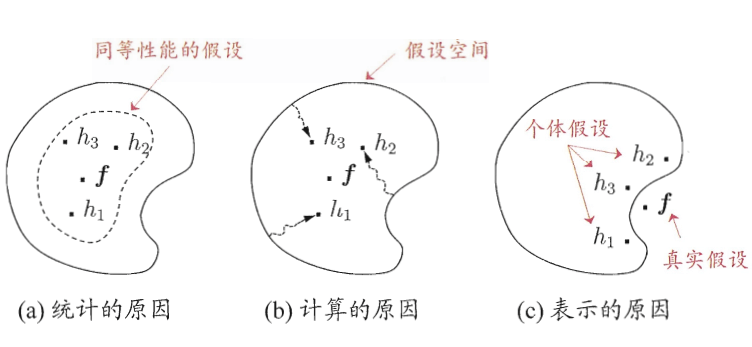
理论上,学习器的集成会从三个方面带来好处:
- 首先,从 统计 的方面看,由于学习任务的假设空间往往很大,可能有多个假设在训练集上达到相同的性能,此时若使用单学习器,可能因误选而导致 泛化性能不佳,结合多个学习器则会减少这一风险;
- 其次,从 计算 的方面看,学习算法往往会陷入 局部极小,有的局部极小点所对应的泛化性能可能很糟糕,而通过多次运行之后进行结合,可降低陷入糟糕局部极小点的风险;
- 最后,从 表示 的方面看,某些学习任务的 真实假设可能不在当前学习算法所考虑的假设空间中,此时若使用单学习器则肯定无效,而通过结合多个学习器,由于相应的假设空间有所扩大,有可能学得更好的近似。
1.1 分类器
分类器 (Classifier) 是数据挖掘中对样本进行分类的方法的统称,包括:决策树、逻辑回归、朴素贝叶斯、神经网络 等算法。分类指在已有数据的基础上学会一个分类函数或构造出一个分类模型(即分类器,以便于将数据映射到给定类别,从而用于预测。
常见的分类器:
- 决策树分类器 的构造无需任何领域的知识和任何参数设置,因此特别适合于探测式的知识发现。此外,决策树分类器 不仅可采用类似树的形式处理高维数据,还特别直观和便于理解。因此,决策树是许多商业规则归纳系统的基础。
- 素贝叶斯分类器 是一类假设数据样本特征完全独立、以贝叶斯定理为基础的简单概率分类器。
- AdaBoost 算法 的自适应在于前一个分类器产生的错误分类样本会被用来训练下一个分类器,从而提升分类准确率,但对于噪声样本和异常样本较敏感。
- 支持向量机 (SVM) 分类器 构建一个或多个高维的超平面 (样本间的分类边界) 将划分样本数据。
- K 近邻 (KNN) 分类器 是基于距离计算的分类器,其选择 K 个距离度量上最佳的样本进行分析,从而简化计算提升效率
分类器构造和实施的基本过程:
- 选定样本(包含正、负样本)并分成训练样本和测试样本两部分;
- 在训练样本上训练/拟合分类器算法,生成分类模型;
- 在测试样本上对分类模型进行测试/预测/推理,生成预测结果;
- 根据预测结果,计算必要的评估指标,评估分类模型的性能。
二、集成方法

- Bagging 又称 自助聚合法 (Bootstrap Aggregating),通常考虑的是 同质弱
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 741
741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









