







本人第在20240511 用yolov8自己训练模型成功,用70张标注文件在简单背景情况下,获得极高准确度,故记录一下步骤备忘。
本人yolo新手,如有不对还请各位老师指出。
一、环境安装
安装miniconda:Miniconda — Anaconda documentation
 下载完安装,在开始按钮处找到:Anaconda prompt,启动后在base用户下,在此窗口下输入创建命令:
下载完安装,在开始按钮处找到:Anaconda prompt,启动后在base用户下,在此窗口下输入创建命令:
conda create -n py38 python=3.8执行完后激活环境:
conda activate py38然后换个源
pip config set install.trusted-host mirrors.aliyun.com然后正常安装
pip install ultralytics安装也不快,可能要等一会
然后安装标注工具
pip install labelimg到此安装的就结束。
二、数据标注
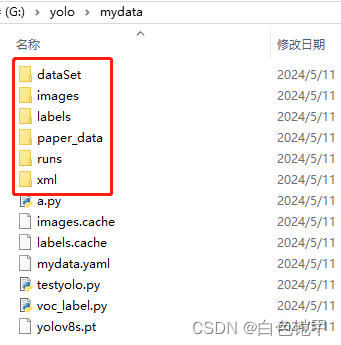
先搞个mydata文件夹,内部如下图所示再搞几个文件夹:dataSet,images,labels,paper_data,xml,runs可以不用,他是自己创建出来的
把图片放到images,先开始数据标注吧,还是那个命令行窗口:
labelimg执行完会打开一个界面:
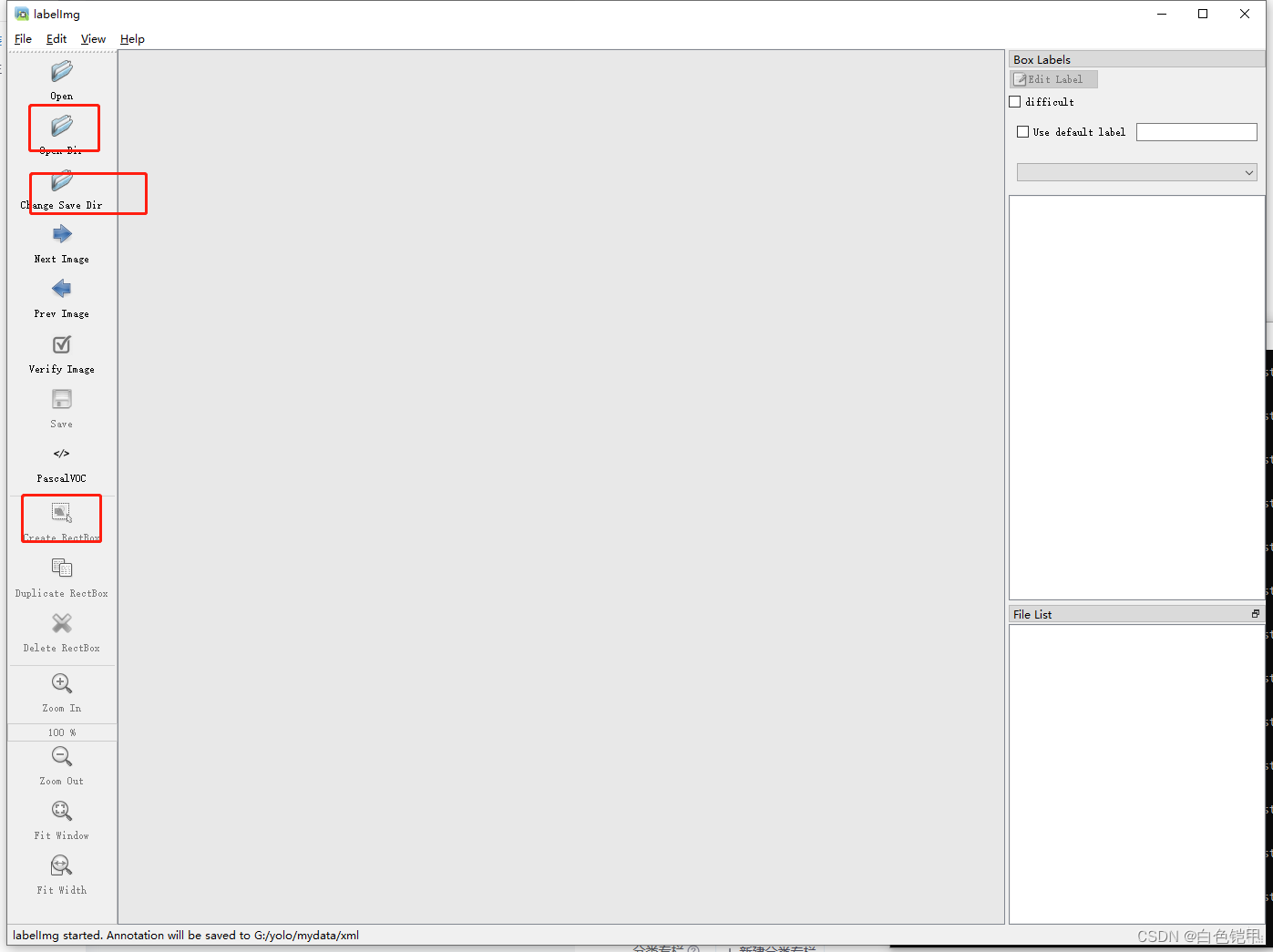
然后打开存放图片的目录,他会一个个放到这里,你就开始标注,第一次画框 他会让你创建一个标签名字,我起了一个就叫“id”的,保存的目录选xml,这样就会自动保存到那个目录了,不会标注的建议看一下这个文章:【教程】标注工具Labelimg的安装与使用 - 知乎 (zhihu.com) 差不多看一下就会了。另外,images下面图片名称很奇怪很长的话,建议改一下名字,你可以全选文件,对一个改名成空值,这样其他的就会变成(1).jpg.....(n).jpg了
然后创建一个自动划分数据的脚本,可以分成训练、测试、验证集,创建a.py
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='xml', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='dataSet', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
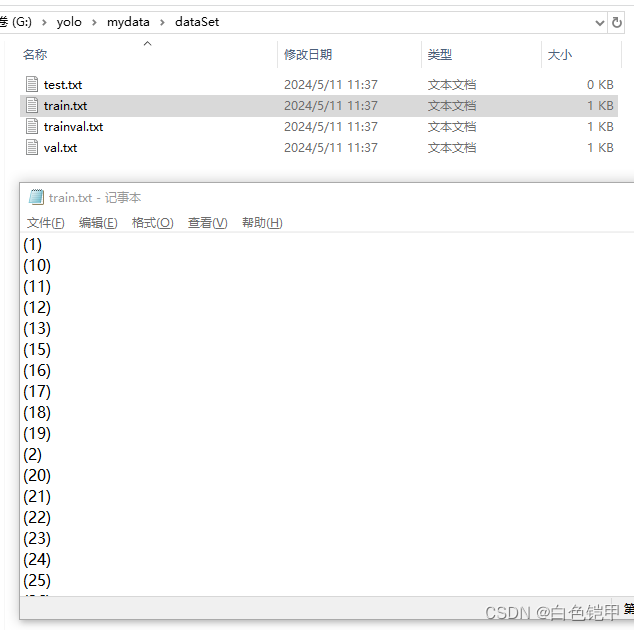
file_test.close()这个代码大家都在用,执行完后,我的txt是这样的
然后再创建一个脚本voc_label.py,内容是:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["id"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('xml/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('dataSet/%s.txt' % (image_set)).read().strip().split()
list_file = open('paper_data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
这个脚本我就改了一下类别,他在paper_data下生成了要用到的数据集 :
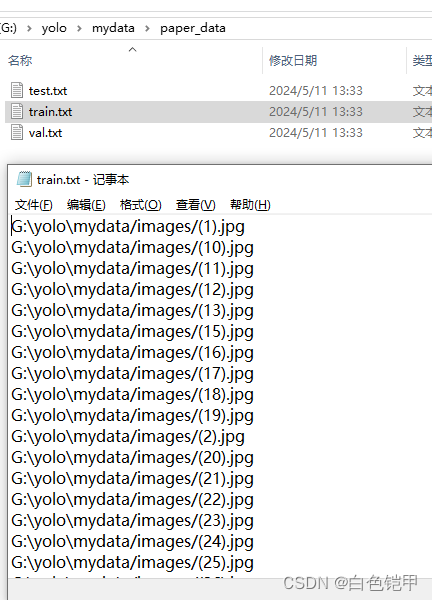
在labels下生成了从xml转来的数据文件:
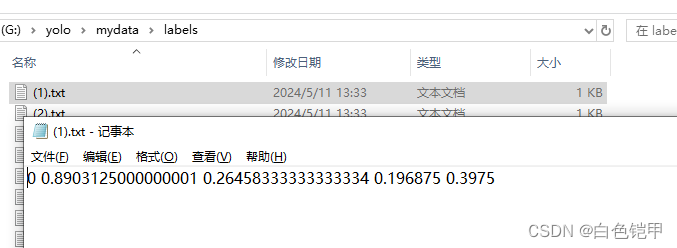
至此数据是准备完了。再改yolo的配置文件 :
在mydata目录下创建mydata.yaml文件,内容就是自己的路径和类:
train: 'G:\yolo\mydata\paper_data\train.txt'
val: 'G:\yolo\mydata\paper_data\val.txt'
#classes
names:
0: id三、训练
直接执行下面的命令就行,他自己会下载模型 ,你也可以自己下载
yolo task=detect model=yolov8s.pt data=mydata.yaml epochs=200 batch=8 device=cpu具体参数含义可以看结尾其他前辈的文章。剩下的就是等训练结束。
四、测试
等模型训练完,可以用py写一个摄像头的脚本来实时测试:
import cv2
import sys
import time
import numpy as np
from ultralytics import YOLO
# 加载模型
model = YOLO('runs/detect/train3/weights/best.pt') # 载入自定义模型
cap = cv2.VideoCapture(0) # 更改数字,切换不同的摄像头
cap.set(cv2.CAP_PROP_FRAME_WIDTH,1600)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT,1200)
# loop
while cap.isOpened():
success, frame = cap.read()
if success:
start = time.perf_counter()
# Run YOLOv8 inference on the frame
results = model(frame)
end = time.perf_counter()
total_time = end - start
fps = 1 / total_time
# visualize the results on the frame
annotated_frame = results[0].plot()
# display the annotated frame
cv2.imshow("YOLOv8 Inference:", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord('q'):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display windows
cap.release()
cv2.destroyAllWindows()
测试效果很好:

五、结尾
感谢互联网上各位老师提供的参考:
YOLOv8训练自己的数据集_yolov8 txt数据读取-CSDN博客
YOLOv8教程系列:一、使用自定义数据集训练YOLOv8模型(详细版教程,你只看一篇->调参攻略),包含环境搭建/数据准备/模型训练/预测/验证/导出等_yolov8训练自己的数据集-CSDN博客 如果我写的有什么问题,大家可以参看上述几位前辈的文章。
20240513补充:如果需要识别倾斜或旋转的物体,可以参考【【保姆级教程】YOLOv8_OBB旋转目标检测:训练自己的数据集_如何自训练旋转目标-CSDN博客】















 2170
2170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









