










图没了,大家可以移步原文网址,之前放在最后的。。。
https://www.jianshu.com/p/ab1ebddf58b1
一、资源提供:
论文链接 Faster R-CNN Towards Real-Time Object:
https://arxiv.org/pdf/1506.01497.pdf
tensorflow源码链接:
https://github.com/smallcorgi/Faster-RCNN_TF
二、FRCNN组成
Faster R-CNN是目标检测界的大神Ross Girshick 2015年提出的一个很经典的检测结构,它将传统的Selective Search提取目标的方法替换成网络训练来实现,使得全流程的检测、分类速度大幅提升。
图1是Faster R-CNN的基本结构,由以下4个部分构成:
1、特征提取部分:用一串卷积+pooling从原图中提取出feature map;
2、RPN部分:这部分是Faster R-CNN全新提出的结构,作用是通过网络训练的方式从feature map中获取目标的大致位置;
3、Proposal Layer部分:利用RPN获得的大致位置,继续训练,获得更精确的位置;
4、ROI Pooling部分:利用前面获取到的精确位置,从feature map中抠出要用于分类的目标,并pooling成固定长度的数据;

分布详解:
(1)特征提取部分:特征提取部分就是图1中输入图片和feature map间的那一串卷积+pooling,这部分和普通的CNN网络中特征提取结构没有区别,可以用VGG、ResNet、Inception等各种常见的结构实现(只使用全连接层之前的部分),这部分不再详述。
(2)RPN部分:目标识别有两个过程:首先你要知道目标在哪里,要从图片中找出要识别的前景,然后才是拿前景去分类。在Faster R-CNN提出之前常用的提取前景(本文称为提取proposal)的方法是Selective Search,简称SS法,通过比较相邻区域的相似度来把相似的区域合并到一起,反复这个过程,最终就得到目标区域,这种方法相当耗时以至于提取proposal的过程比分类的过程还要慢,完全达不到实时的目的;到了Faster R-CNN时,作者就想出把提取proposal的过程也通过网络训练来完成,部分网络还可以和分类过程共用,新的方法称为Reginal Proposal Network(RPN),速度大大提升。
图2粉色框内就是RPN,它做两件事:1、把feature map分割成多个小区域,识别出哪些小区域是前景,哪些是背景,简称RPN Classification,对应粉色框中上半分支;2、获取前景区域的大致坐标,简称RPN bounding box regression,对应下半分支;

第一步:RPN Classification
RPN Classification的过程就是个二分类的过程。先要在feature map上均匀的划分出KxHxW个区域(称为anchor,K=9,H是feature map的高度,W是宽度),通过比较这些anchor和ground truth间的重叠情况来决定哪些anchor是前景,哪些是背景,也就是给每一个anchor都打上前景或背景的label。有了labels,你就可以对RPN进行训练使它对任意输入都具备识别前景、背景的能力。
在图2上半分支可以看到rpn_cls_score_reshape模块输出的结构是[1,9*H,W,2],就是9xHxW个anchor二分类为前景、背景的概率;anchor_target_layer模块输出的是每一个anchor标注的label,拿它和二分类概率一比较就能得出分类的loss。
一个feature map有9xHxW个anchor,就是说每个点对应有9个anchor,这9个anchor有1:1、1:2、2:1三种长宽比,每种长宽比都有三种尺寸(见图3)。一般来说原始输入图片都要缩放到固定的尺寸才能作为网络的输入,这个尺寸在作者源码里限制成800x600,9种anchor还原到原始图片上基本能覆盖800x600图片上各种尺寸的坐标。
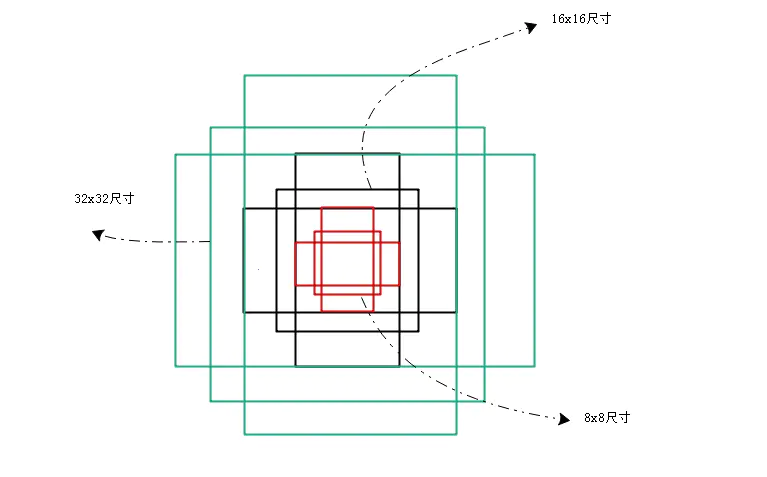
要注意的是在实际应用时并不是把全部HxWx9个anchor都拿来做label标注,这里面有些规则来去除效果不好的anchor,具体的规则如下:
覆盖到feature map边界线上的anchor不参与训练;
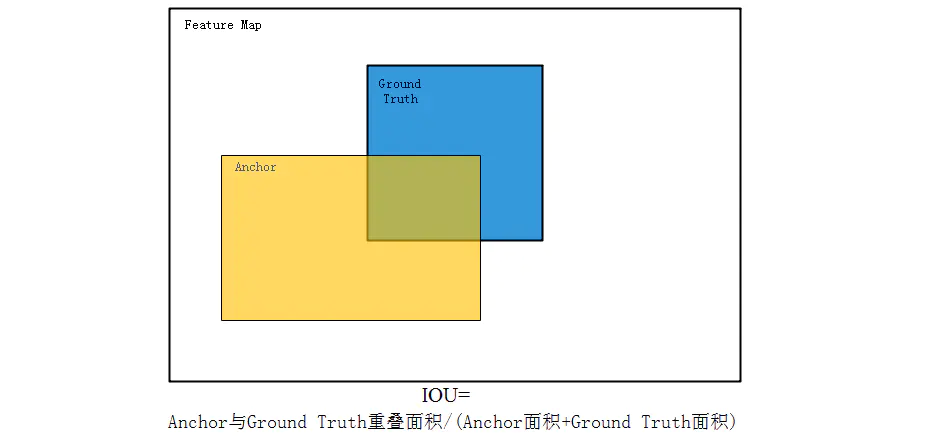
前景和背景交界地带的anchor不参与训练。这些交界地带即不作为前景也不作为背景,以防出现错误的分类。在作者原文里把IOU>0.7作为标注成前景的门限,把IOU<0.3作为标注成背景的门限,之间的值就不参与训练,IOU是anchor与ground truth的重叠区域占两者总覆盖区域的比例,见示意图4;
训练时一个batch的样本数是256,对应同一张图片的256个anchor,前景的个数不能超过一半,如果超出,就随机取128个做为前景,背景也有类似的筛选规则;
第二步:RPN bounding box regression
RPN bounding box regression用于得出前景的大致位置,要注意这个位置并不精确,准确位置的提取在后面的Proposal Layer bounding box regression章节会介绍。提取的过程也是个训练的过程,前面的RPN classification给所有的anchor打上label后,我们需用一个表达式来建立anchor与ground truth的关系,假设anchor中心位置坐标是[Ax, Ay],长高为Aw和Ah,对应ground truth的4个值为[Gx,Gy,Gw,Gh],他们间的关系可以用公式1来表示。[dx(A), dy(A), dw(A), dh(A)]就是anchor与ground truth之间的偏移量,由公式1可以推导出公式2,这里用对数来表示长宽的差别,是为了在差别大时能快速收敛,差别小时能较慢收敛来保证精度:

有了这4个偏移量,你就可以拿他们去训练图2 RPN中下面一个分支的输出。完成训练后RPN就具备识别每一个anchor到与之对应的最优proposal偏移量的能力([d'x(A), d'y(A), d'w(A), d'h(A)]),换个角度看就是得到了所有proposal的位置和尺寸。要注意的是如果一个feature map中有多个ground truth,每个anchor只会选择和它重叠度最高的ground truth来计算偏移量。
第三步:RPN的loss计算
RPN训练时要把RPN classification和RPN bounding box regression的loss加到一起来实现联合训练。公式3中Ncls是一个batch的大小256,Lcls(pi, pi*)是前景和背景的对数损失,pi是anchor预测为目标的概率,就是前面rpn_cls_score_reshape输出的前景部分score值,pi*是前景的label值,就是1,将一个batch所有loss求平均就是RPN classification的损失;公式3中Nreg是anchor的总数,λ是两种 loss的平衡比例,ti是图2中rpn_bbox_pred模块输出的[d'x(A), d'y(A), d'w(A), d'h(A)],t*i是训练时每一个anchor与ground truth间的偏移量,t*i与ti用smooth L1方法来计算loss就是RPN bounding box regression的损失:

关于Smooth L1的原理,请参考:
http://pages.cs.wisc.edu/~gfung/GeneralL1/L1_approx_bounds.pdf
(3)Proposal Layer部分
得到proposal大致位置后下一步就是要做准确位置的回归了。在RPN的训练收敛后我们能得到anchor相对于proposal的偏移量[d'x(A), d'y(A), d'w(A), d'h(A)](要注意这里是想对于proposal的,而不是相对于ground truth的),有了偏移量再根据公式1就能算出proposal的大致位置。在这个过程中HxWx9个anchor能算出HxWx9个proposal,大多数都是聚集在ground truth周围的候选框,这么多相近的proposal完全没必要反而增加了计算量,这时就要用一些方法来精选出最接近ground truth的proposal,Ross Girshick给了三个步骤:
a.先选出前景概率最高的N个proposal;
b.做非极大值抑制(NMS)
c.NMS后再次选择前景概率最高的M个proposal;
经历这三个步骤后能够得到proposal的大致位置,但这还不够,为了得到更精确的坐标,你还要利用公式2再反推出这个大致的proposal和真实的ground truth间还有多少偏移量,对这个新的偏移量再来一次回归才是完成了精确的定位。
上面的过程比较绕,反复在偏移量、anchor、ground truth间切换,下面的示意图可以加深理解:

proposal精确位置回归时计算loss的公式和公式3中RPN bounding box regression的loss计算方法完全相同,也用smooth L1方法。
(4)ROI Pooling部分
结构篇:
ROI Pooling做了两件事:1、从feature maps中“抠出”proposals(大小、位置由RPN生成)区域;2、把“抠出”的区域pooling成固定长度的输出。
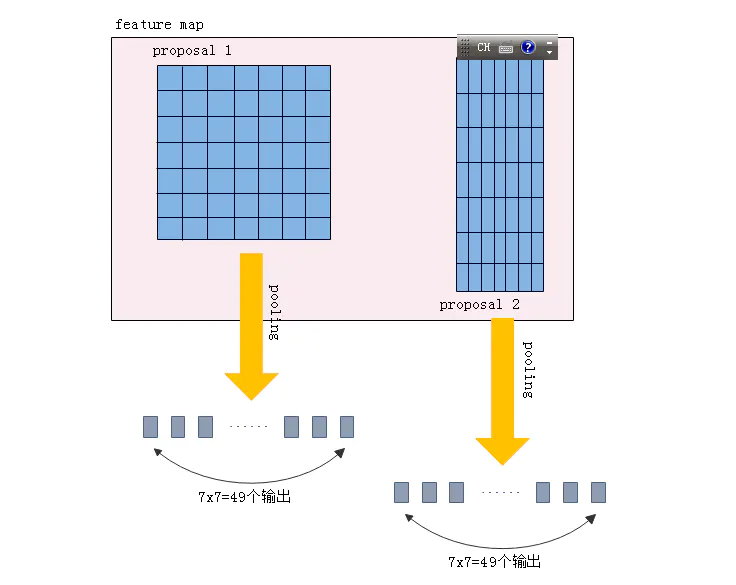
图6是pooling过程的示意图,feature map中有两个不同尺寸的proposals,但pooling后都是7x7=49个输出,这样就能为后面的全连接层提供固定长度的输入。这种pooling方式有别于传统的pooling,没有任何tensorflow自带的函数能实现这种功能,你可以自己用python写个ROI Pooling的过程,但这样就调用不了GPU的并行计算能力,所以作者的源码里用C++来实现整个ROI Pooling。
释疑篇:
为什么要pooling成固定长度的输出呢?这个其实来自于更早提出的SPP Net,RPN网络提取出的proposal大小是会变化的,而分类用的全连接层输入必须固定长度,所以必须有个从可变尺寸变换成固定尺寸输入的过程。在较早的R-CNN和Fast R-CNN结构中都通过对proposal进行拉升(warp)或裁减(crop)到固定尺寸来实现,拉升、裁减的副作用就是原始的输入发生变形或信息量丢失(图7),以致分类不准确。而ROI Pooling就完全规避掉了这个问题,proposal能完整的pooling成全连接的输入,而且没有变形,长度也固定。

源码篇:
lib\roi_pooling_layer目录下文件用来实现ROI Pooling。先来看roi_pooling_op.cc,里面有4个类:

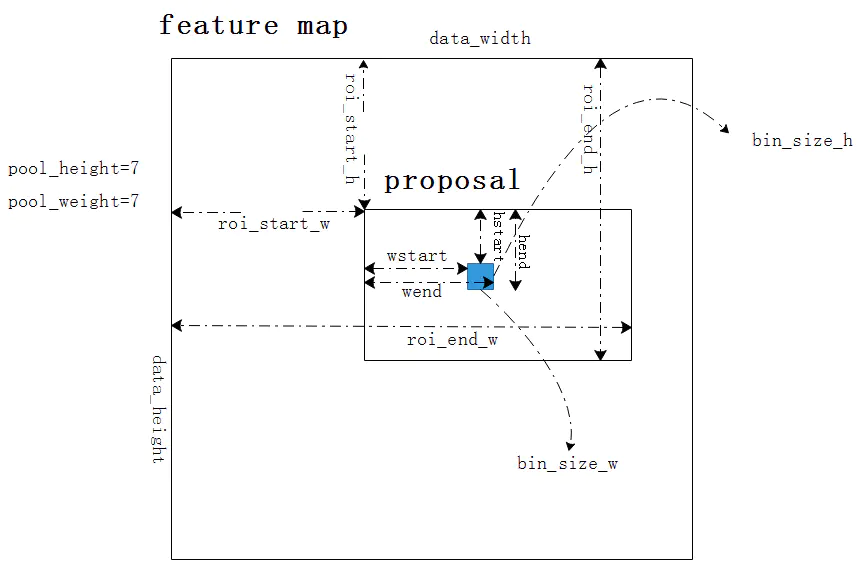
CPU和GPU版本的具体流程差异不大,只是后者通过CUDA来实现,具体的代码就不贴了,下面一张图里各个参数的名称对应着代码里前向pooling计算时参数的取名(在RoiPoolOp类的Compute()函数中),图中的proposal被分割成7x7个小方块(图中蓝色的小方块),每个蓝色的大小是bin_size_w x bin_size_h ,其中的最大值就是一个pooling的结果,一个proposal共有49个pooling输出。可以对照下图和代码来理解:
(5)训练过程
前面介绍了Faster R-CNN的结构,最后看下训练方法,为了便于说明,我们把RPN中的rpn classification和rpn bounding box regression统称为RPN训练;把proposal layer中对proposal精确位置的训练和最终的准确分类训练统称为R-CNN训练。Ross Girshick在论文中介绍了3种训练方法:
Alternating training:RPN训练和R-CNN训练交替进行,共交替两次。训练时先用ImageNet预训练的结果来初始化网络,训练RPN,用得到的proposal再训练R-CNN,之后用R-CNN训练出的参数来初始网络,再训练一次RPN,最后用RPN训练出的参数来初始化网络,最后训练次R-CNN,就完成了全部的训练过程。
Approximate joint training:这里与前一种方法不同,不再是串行训练RPN和R-CNN,而是尝试把二者融入到一个网络内一起训练。这里Approximate 的意思是指把RPN bounding box regression部分反向计算得到的梯度完全舍弃,不用做更新网络参数的权重。Approximate joint training相对于Alternating traing减少了25-50%的训练时间。
Non-approximate training:该方法和Approximate joint training基本一致,只是不再舍弃RPN bounding box regression部分得到的梯度。
本文开头提供的源码使用的是第三种方法,把4个部分的loss都加到了一起来训练,它的速度要更快。















 545
545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









