







文章目录
论文简介
论文提出了一种强大的单阶段面部检测器RetinaFace,通过联合外监督(extra-supervised)和自监督(self-supervised)多任务学习的优势,在各种规模的人脸上执行像素级人脸定位,并实现了在WIDER FACE数据集上的最佳表现(SOTA)
主要贡献
➢在WIDER FACE数据集上手动标注了五个facial landmarks,通过这种额外的辅助监督,观察到其在hard face检测方面得到显著的改善
➢添加了一个自监督网格解码器(mesh decoder)分支,用于与现有的监督分支并行地预测像素级3D形状人脸信息
➢在WIDER FACE的hard测试集上,RetinaFace的性能优于最新平均精度(AP)
1.1
%
1.1%
1.1%,达到
91.4
%
91.4%
91.4%
➢在IJB-C测试集上,RetinaFace使最先进的方法(ArcFace)能够提高它们在人脸验证中的结果(TAR =
89.59
%
89.59%
89.59%,FAR =
1
e
−
6
1e-6
1e−6)
➢通过使用轻型骨干网络,RetinaFace可以在单个CPU内核上实时运行以获取VGA分辨率的图像。
论文研读
摘要
对于许多应用程序,例如面部属性(例如表情和年龄)和面部身份识别,自动面部定位是面部图像分析的前提步骤。面部定位的狭窄定义可以参考传统的面部检测,其目的是在没有任何比例和位置的情况下估计面部边界框。然而,在本文中我们指的是面部定位的广义定义,包括人脸检测,人脸对齐,逐像素人脸解析和3D密集对应回归。这种密集的面部定位可为所有不同的尺寸提供准确的面部位置信息
受到涵盖深度学习所有最新进展的通用目标检测方法的启发,面部检测最近取得了显着进步。与普通物体检测不同,面部检测具有更小的Ratio(1:1~1:1.5),但更大的Scale(从几像素到几千像素)。最新SOTA方法专注于单阶段设计,该设计可以密集地采样特征金字塔上的脸部位置和比例,与两阶段相比,其产生了更好的性能和更快的速度。沿着这条路线,我们改进了单阶段人脸检测框架,并通过利用来自强监督和自监督信号的多任务损失,提出了一种SOTA密集人脸定位方法。具体想法在下图得到展现

上图所提出的单阶段像素级人脸定位方法采用了与现有的框分类和回归分支并行的外监督和自监督多任务学习。每个positive anchor有四部分输出:(1)面部得分,(2)面部框,(3)五个面部标志,(4)投影在图像平面上的密集3D面部顶点
人脸检测训练过程包含分类损失和框回归损失。《D. Chen, S. Ren, Y . Wei, X. Cao, and J. Sun. Joint cascade face detection and alignment. 》基于对齐的面部形状为面部分类提供更好特征,提出在联合级联框架中将脸部检测和对齐结合起来。受《D. Chen, S. Ren, Y . Wei, X. Cao, and J. Sun. Joint cascade face detection and alignment. 》的启发,MTCNN和STN同时检测人脸和5个面部标志。由于训练数据的限制,JDA 、MTCNN和STN还没有验证微型人脸检测是否可以受益于五个面部标志的额外监督。本文旨在回答的一个问题是,我们是否可以通过使用由五个面部标志构建的额外监督信号,在WIDER FACE的hard测试集上推进当前的最佳性能(
90.3
90.3%
90.3)
在Mask R-CNN中,通过添加分支来预测掩膜并与现有分支并行进行边界框识别和回归,可以大大提高检测性能。这证实了密集像素级标签也有助于提高检测。不幸的是,对于WIDER FACE具有挑战性的面孔,不可能进行密集的面孔标注(无论是以更多的Landmarks或semantic segments的形式)。由于有监督的信号不容易获得,问题是我们是否可以应用无监督的方法进一步提高人脸检测
在FAN(《J. Wang, Y . Y uan, and G. Y u. Face attention network: an effective face detector for the occluded faces.》)
中,提出了一种锚级(anchor-level)注意力图(attention map)来改善遮挡人脸检测。然而,所提出的注意力图相当粗糙,且并不包含语义信息。最近,自我监督的3D可变形模型(3DMM)已经在野外数据集上取得了较好的性能。特别地,网格解码器(Mesh Decoder)在联合形状和纹理上使用图卷积实现了超实时速度。然而,将网格解码器应用到单阶段检测器中的主要挑战是:(1)摄像机参数难以精确估计,(2)从单个特征向量(特征金字塔上的
1
×
1
1×1
1×1卷积)而不是RoI池化特征来预测联合的潜在形状和纹理表示,这具有特征偏移的风险。在本文中,我们使用网格解码器分支通过自监督学习,与现有的监督分支并行预测像素级3D人脸形状
总之,我们的主要贡献是:
•在单阶段设计的基础上,提出了一种新的基于像素的人脸定位方法——RetinaFace,该方法采用多任务学习策略同时预测人脸分数、人脸框、五个人脸Landmarks以及每个人脸像素的三维位置和对应关系
•在WIDER FACE的hard子集上,RetinaFace的性能比最先进的两阶段方法(ISRN)高1.1%(AP等于91.4%)
•在IJB-C数据集上,RetinaFace有助于提高ArcFace的验证准确性(当TAR等于89.59%时FAR=1e-6)。这表明更好的人脸定位可以显着改善人脸识别能力
•通过使用轻型骨干网络,RetinaFace可以在单个CPU内核上实时运行以获取VGA分辨率的图像
•已经发布了额外的标签和代码,以方便将来的研究
相关工作
图像金字塔与特征金字塔
两阶段与单阶段
上下文建模
为了增强模型的上下文推理能力以捕获微小的面孔,SSH和PyramidBox在特征金字塔上应用了上下文模块,以扩大来自欧几里得网格(Euclidean grids)的接收范围。为了增强CNN的非刚性变换建模能力,可变形卷积网络(DCN)采用了一种新型的可变形层来对几何变换进行建模。 WIDER Face Challenge 2018的冠军解决方案表明,刚性(扩展)和非刚性(变形)上下文建模对于提高检测性能来说是互补且正交的
多任务学习
由于对齐的面部形状为面部分类提供了更好的功能,因此联合的面部检测和对齐被广泛使用。在Mask R-CNN中,通过增加一个分支与现有分支并行预测对象掩模,大大提高了检测性能。 Densepose采用Mask R-CNN的结构来获得密集区域标签和每个选定区域内的坐标。然而,《R. Alp Güler, N. Neverova, and I. Kokkinos. Densepose: Dense human pose estimation in the wild.》和《K. He, G. Gkioxari, P . Dollár, and R. Girshick. Mask r-cnn.》中的密集回归分支是通过监督学习进行训练的。另外,密集分支是应用于每个RoI的小FCN,以预测像素到像素的密集映射
RetinaFace
多任务损失
对于每一个训练anchor
i
i
i,我们最小化以下多任务损失函数:
L
=
L
c
l
s
(
p
i
,
p
i
∗
)
+
λ
1
p
i
∗
L
b
o
x
(
t
i
,
t
i
∗
)
+
λ
2
p
i
∗
L
p
t
s
(
l
i
,
l
i
∗
)
+
λ
3
p
i
∗
L
p
i
x
e
l
L = {L_{cls}}({p_i},p_i^*) + {\lambda _1}p_i^*{L_{box}}({t_i},t_i^*) + {\lambda _2}p_i^*{L_{pts}}({l_i},l_i^*) + {\lambda _3}p_i^*{L_{pixel}}
L=Lcls(pi,pi∗)+λ1pi∗Lbox(ti,ti∗)+λ2pi∗Lpts(li,li∗)+λ3pi∗Lpixel
➢
L
c
l
s
(
p
i
,
p
i
∗
)
{L_{cls}}({p_i},p_i^*)
Lcls(pi,pi∗)表示人脸分类损失,其中
p
i
p_i
pi为anchor
i
i
i预测为人脸的概率,
p
i
∗
p_i^*
pi∗则为
0
0
0(negative anchor),
1
1
1(positive anchor)。分类损失
L
c
l
s
L_{cls}
Lcls是二分类(是否为人脸)的softmax损失
➢人脸框回归损失
L
b
o
x
(
t
i
,
t
i
∗
)
{L_{box}}({t_i},t_i^*)
Lbox(ti,ti∗),其中
t
i
=
{
t
x
,
t
y
,
t
w
,
t
h
}
i
t_i=\{t_x, t_y, t_w, t_h\}_i
ti={tx,ty,tw,th}i,
t
i
∗
=
{
t
x
∗
,
t
y
∗
,
t
w
∗
,
t
h
∗
}
i
t_i^*=\{t_x^*, t_y^*, t_w^*, t_h^*\}_i
ti∗={tx∗,ty∗,tw∗,th∗}i表示与positive anchor相关的预测框坐标及其ground-truth。我们按照《R. Girshick. Fast r-cnn.》归一化框回归目标(即中心位置,宽度和高度)并使用
L
b
o
x
(
t
i
,
t
i
∗
)
=
R
(
t
i
−
t
i
∗
)
{L_{box}}({t_i},t_i^*)=R(t_i-t_i^*)
Lbox(ti,ti∗)=R(ti−ti∗),其中
R
R
R是《R. Girshick. Fast r-cnn.》定义的鲁棒性损失函数(
smooth -
L
1
{\text{smooth - }}{{\text{L}}_{\text{1}}}
smooth - L1)
➢Facial landmarks回归损失
L
p
t
s
(
l
i
,
l
i
∗
)
{L_{pts}}({l_i},l_i^*)
Lpts(li,li∗),其中
l
i
=
{
l
x
1
,
l
y
1
,
.
.
.
,
l
x
5
,
l
y
5
}
i
l_i=\{l_{x_1},l_{y_1},...,l_{x_5},l_{y_5}\}_i
li={lx1,ly1,...,lx5,ly5}i以及
l
i
=
{
l
x
1
∗
,
l
y
1
∗
,
.
.
.
,
l
x
5
∗
,
l
y
5
∗
}
i
l_i=\{l_{x_1}^*,l_{y_1}^*,...,l_{x_5}^*,l_{y_5}^*\}_i
li={lx1∗,ly1∗,...,lx5∗,ly5∗}i代表与positive anchor关联的五个Facial landmark的预测结果及ground-truth。类似于框中心回归,五个Facial landmarks回归还基于anchor中心采用目标归一化
➢密集回归损失
L
p
i
x
e
l
L_{pixel}
Lpixel。损失平衡参数
λ
1
−
λ
3
λ1-λ3
λ1−λ3设置为0.25、0.1和0.01,这意味着我们从监督信号中提高了更好的框和landmark位置的重要性
密集回归分支
网格解码器(Mesh Decoder)
我们直接使用【《Y . Zhou, J. Deng, I. Kotsia, and S. Zafeiriou. Dense 3d face decoding over 2500fps: Joint texture and shape convolutional mesh decoders.》和《A. Ranjan, T. Bolkart, S. Sanyal, and M. J. Black. Generating 3d faces using convolutional mesh autoencoders.》】中的网格解码器(网格卷积和网格上采样),这是一种基于快速局部频谱滤波的图卷积方法。为了获得进一步的加速,与《A. Ranjan, T. Bolkart, S. Sanyal, and M. J. Black. Generating 3d faces using convolutional mesh autoencoders.》中仅解码形状的方法相反,我们也使用类似于《Y . Zhou, J. Deng, I. Kotsia, and S. Zafeiriou. Dense 3d face decoding over 2500fps: Joint texture and shape convolutional mesh decoders.》中方法的联合形状和纹理解码器
下面我们将简要解释图卷积的概念,并概述为什么它们可以用于快速解码。如下图(a)所示,二维卷积运算是欧几里德网格接收场内的“kernel-weighted neighbour sum”。类似地,如下图(b)所示,图卷积也采用相同的概念

(a) 2D Convolution is kernel-weighted neighbour sum within the Euclidean grid receptive field. Each convolutional layer has K e r n e l H × K e r n e l W × C h a n n e l i n × C h a n n e l o u t Kernel_H×Kernel_W×Channel_{in}×Channel_{out} KernelH×KernelW×Channelin×Channelout parameters. (b) Graph convolution is also in the form of kernel-weighted neighbour sum, but the neighbour distance is calculated on the graph by counting the minimum number of edges connecting two vertices. Each convolutional layer has K × C h a n n e l i n × C h a n n e l o u t K ×Channel_{in}× Channel_{out} K×Channelin×Channelout parameters and the Chebyshev coefficients θ i , j ∈ R K θ_{i,j}∈ R^K θi,j∈RKare truncated at order K.
但是,邻居距离是通过计算连接两个顶点的最小边数来计算的。我们遵循《Y . Zhou, J. Deng, I. Kotsia, and S. Zafeiriou. Dense 3d face decoding over 2500fps: Joint texture and shape convolutional mesh decoders.》来定义彩色的面部网格 G = ( υ , ε ) G = (\upsilon ,\varepsilon ) G=(υ,ε),其中 υ ∈ R n × 6 \upsilon \in {\mathbb{R}^{n \times 6}} υ∈Rn×6是一组包含形状和纹理信息的面部顶点, ε ∈ { 0 , 1 } n × n \varepsilon \in {\{ 0,1\} ^{n \times n}} ε∈{0,1}n×n是一组编码顶点之间连接状态的稀疏邻阶矩阵。图拉普拉斯函数定义为 L = D − ε ∈ R n × n L = D - \varepsilon \in {\mathbb{R}^{n \times n}} L=D−ε∈Rn×n,其中 D ∈ R n × n D \in {\mathbb{R}^{n \times n}} D∈Rn×n是一个对角矩阵,其中 D i i = ∑ j ε i j {D_{ii}} = \sum\nolimits_j {{\varepsilon _{ij}}} Dii=∑jεij
根据【《M. Defferrard, X. Bresson, and P . V andergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. 》、《A. Ranjan, T. Bolkart, S. Sanyal, and M. J. Black. Generating 3d faces using convolutional mesh autoencoders.》、《Y . Zhou, J. Deng, I. Kotsia, and S. Zafeiriou. Dense 3d face decoding over 2500fps: Joint texture and shape convolutional mesh decoders. 》】,具有kernel为
g
θ
{g_\theta }
gθ的图卷积可以写成一个递归的
K
K
K阶截断切比雪夫多项式
y
=
g
θ
(
L
)
x
=
∑
k
=
0
K
−
1
θ
k
T
k
(
L
~
)
x
y = {g_\theta }(L)x = \sum\limits_{k = 0}^{K - 1} {{\theta _k}{T_k}(\tilde L)} x
y=gθ(L)x=k=0∑K−1θkTk(L~)x
其中
θ
∈
R
K
\theta \in {\mathbb{R}^K}
θ∈RK是切比雪夫系数的向量,
T
k
(
L
~
)
∈
R
n
×
n
{T_k}(\tilde L)\in{\mathbb{R}^{n×n}}
Tk(L~)∈Rn×n是一个按拉普拉斯算子
L
~
\tilde L
L~刻画的
K
K
K阶切比雪夫多项式。
x
ˉ
k
=
T
k
(
L
~
)
x
∈
R
n
{{\bar x}_k} = {T_k}(\tilde L)x \in {\mathbb{R}^n}
xˉk=Tk(L~)x∈Rn,我们可以反复计算
x
ˉ
k
=
2
L
~
x
ˉ
k
−
1
−
x
ˉ
k
−
2
{{\bar x}_k} = 2\tilde L{{\bar x}_{k - 1}} - {{\bar x}_{k - 2}}
xˉk=2L~xˉk−1−xˉk−2,其中
x
ˉ
0
=
x
,
x
ˉ
1
=
L
~
x
{{\bar x}_0} = x,{{\bar x}_1} = \tilde Lx
xˉ0=x,xˉ1=L~x,整个滤波操作以及
K
K
K个稀疏矩阵向量乘法和一个密集矩阵向量乘法是非常有效的,
y
=
g
θ
(
L
)
x
=
[
x
ˉ
0
,
.
.
.
,
x
ˉ
K
−
1
]
θ
y = {g_\theta }(L)x = [{{\bar x}_0},...,{{\bar x}_{K - 1}}]\theta
y=gθ(L)x=[xˉ0,...,xˉK−1]θ
可微的渲染器(Differentiable Renderer)
在我们预测了形状和纹理参数
P
S
T
∈
R
128
P_{ST} \in \mathbb{R}^{128}
PST∈R128之后,我们使用了一个高效的可微分3D网格渲染器将彩色网格
D
P
S
T
D_{P_{ST}}
DPST投影到2D图像平面,其中相机参数
P
c
a
m
=
[
x
c
,
y
c
,
z
c
,
x
′
c
,
y
′
c
,
z
′
c
,
f
c
]
P_{cam}=[x_c,y_c,z_c,{{x'}_c},{{y'}_c},{{z'}_c},f_c]
Pcam=[xc,yc,zc,x′c,y′c,z′c,fc](即相机位置,相机姿态和焦距)以及照度参数
P
i
l
l
=
[
x
l
,
y
l
,
z
l
,
r
l
,
g
l
,
b
l
,
r
a
,
g
a
,
b
a
]
P_{ill}=[x_l,y_l,z_l,r_l,g_l,b_l,r_a,g_a,b_a]
Pill=[xl,yl,zl,rl,gl,bl,ra,ga,ba](即点光源的位置、颜色值和环境照明的颜色)
密集回归损失(Dense Regression Loss)
一旦我们得到渲染的2D脸
R
(
D
P
S
T
,
P
c
a
m
,
P
i
l
l
)
R(D_{P_{ST}},P_{cam},P_{ill})
R(DPST,Pcam,Pill),我们使用以下函数比较渲染图像和原始2D脸的像素差异:
L
p
i
x
e
l
=
1
W
∗
H
∑
i
W
∑
j
H
∥
R
(
D
P
S
T
,
P
c
a
m
,
P
i
l
l
)
i
,
j
−
I
i
,
j
∗
∥
1
{L_{pixel}} = \frac{1}{{W*H}}\sum\limits_i^W {\sum\limits_j^H {{{\left\| {R{{({D_{{P_{ST}}}},{P_{cam}},{P_{ill}})}_{i,j}} - I_{i,j}^*} \right\|}_1}} }
Lpixel=W∗H1i∑Wj∑H∥∥∥R(DPST,Pcam,Pill)i,j−Ii,j∗∥∥∥1
其中
W
W
W和
H
H
H分别是
I
i
,
j
∗
I_{i,j}^*
Ii,j∗上裁剪下的anchor宽高
实验
数据集
WIDER FACE数据集由32203幅图像和393703个面部边界框组成,且在比例、姿势、表情、遮挡和照明方面具有高度可变性。通过从61个场景类别中随机取样,WIDER FACE数据集被分成训练集(40%)、验证集(10%)和测试集(50%)。基于EdgeBox的检测率,通过增量合并hard样本,定义了三个难度级别(即Easy、Medium和Hard)
额外标签(Extra Annotations)
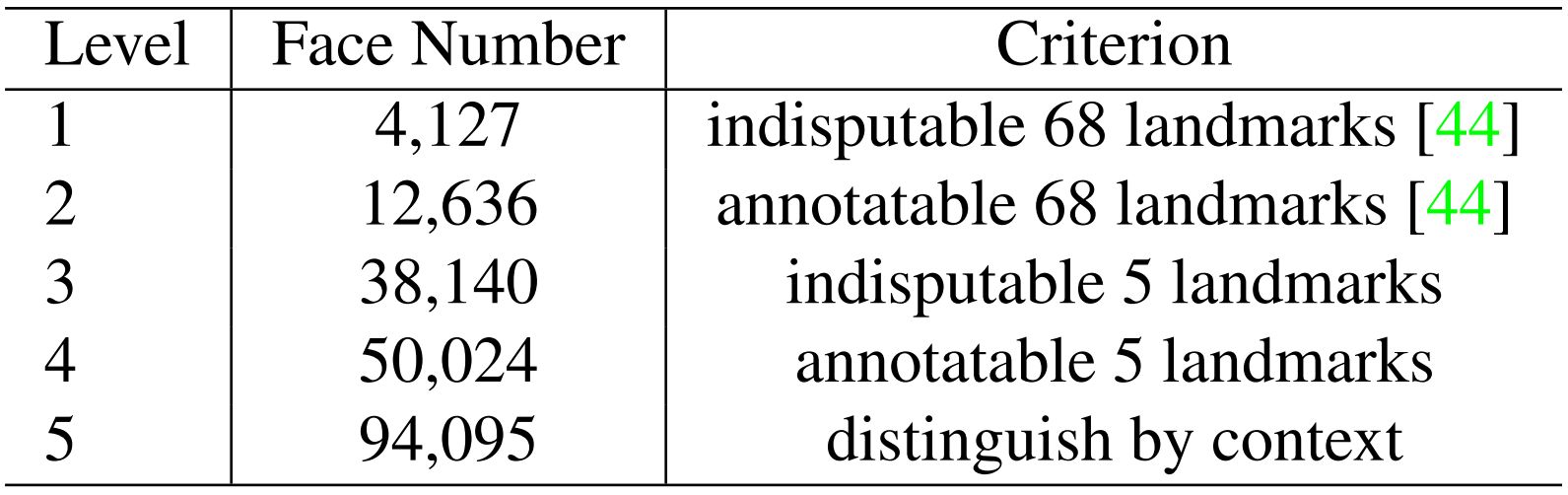
如下图和下表所示,我们根据标注Landmarks的困难程度将人脸图像质量分为五个层次,对于每张人脸,我们标注五个Landmarks,分别是每个眼睛的中心、鼻尖以及嘴角两边。其中训练集共标注了
84.6
k
84.6k
84.6k张脸,验证集则有
18.5
k
18.5k
18.5k

实现细节
特征金字塔(Feature Pyramid)
RetinaFace采用从
P
2
P_2
P2到
P
6
P_6
P6的特征金字塔等级,其中
P
2
P_2
P2到
P
5
P_5
P5是根据相应的ResNet残差阶段(
C
2
C_2
C2至
C
5
C_5
C5)的输出计算而来,使用自上而下和横向连接进行计算的,如【《T.-Y . Lin, P . Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection.》、《T.-Y . Lin, P . Goyal, R. Girshick, K. He, and P . Dollár. Focal loss for dense object detection. 》】所示。
P
6
P_6
P6是通过
C
5
C_5
C5上的步长为
2
2
2的
3
×
3
3×3
3×3卷积计算而来。
C
1
C_1
C1到
C
5
C_5
C5是在ImageNet-11k数据集上预先训练的ResNet-152分类网络,而P_6是用“Xavier”方法随机初始化
上下文模块(Context Module)
受SSH和PyramidBox的启发,我们还在五个特征金字塔级别上应用独立的上下文模块,以增加感受野并增强刚性上下文建模能力。借鉴WIDER Face挑战赛2018冠军,我们还用可变形卷积网络(DCN)替换了横向连接和上下文模块中的所有
3
×
3
3×3
3×3卷积层,这进一步增强了非刚性上下文建模能力
损失头(Loss Head)
对于negative anchors,仅应用分类损失函数。对于positive anchors,则计算所提出的多任务损失函数。我们在不同的特征图
H
n
×
W
n
×
256
,
n
∈
{
2
,
.
.
.
,
6
}
Hn×Wn×256,n\in\{2,...,6\}
Hn×Wn×256,n∈{2,...,6}中共享loss head(1×1卷积),对于网格解码器(mesh decoder),我们应用《 Y . Zhou, J. Deng, I. Kotsia, and S. Zafeiriou. Dense 3d face decoding over 2500fps: Joint texture and shape convolutional mesh decoders. 》中的预训练模型,这样可以减小计算开销并获取高效率的推理
锚点设置(Anchor Settings)
如下表所示,我们在从
P
2
P_2
P2到
P
6
P_6
P6的特征金字塔级别上使用特定比例的anchors。在这里,
P
2
P_2
P2旨在通过平铺小的anchors来捕获微小的面部,但要花费更多的计算时间以及更具风险的假阳率(FP,false positive)。我们将步长比例设置为
2
1
3
{2^{\frac{1}{3}}}
231,纵横比设置为
1
:
1
1:1
1:1。输入图像大小为
640
×
640
640 × 640
640×640,anchors在特征金字塔级别上可以覆盖从
16
×
16
16 × 16
16×16到
406
×
406
406 × 406
406×406的范围。总共有
102300
102300
102300个anchors,其中
75
%
75\%
75%来自
P
2
P_2
P2
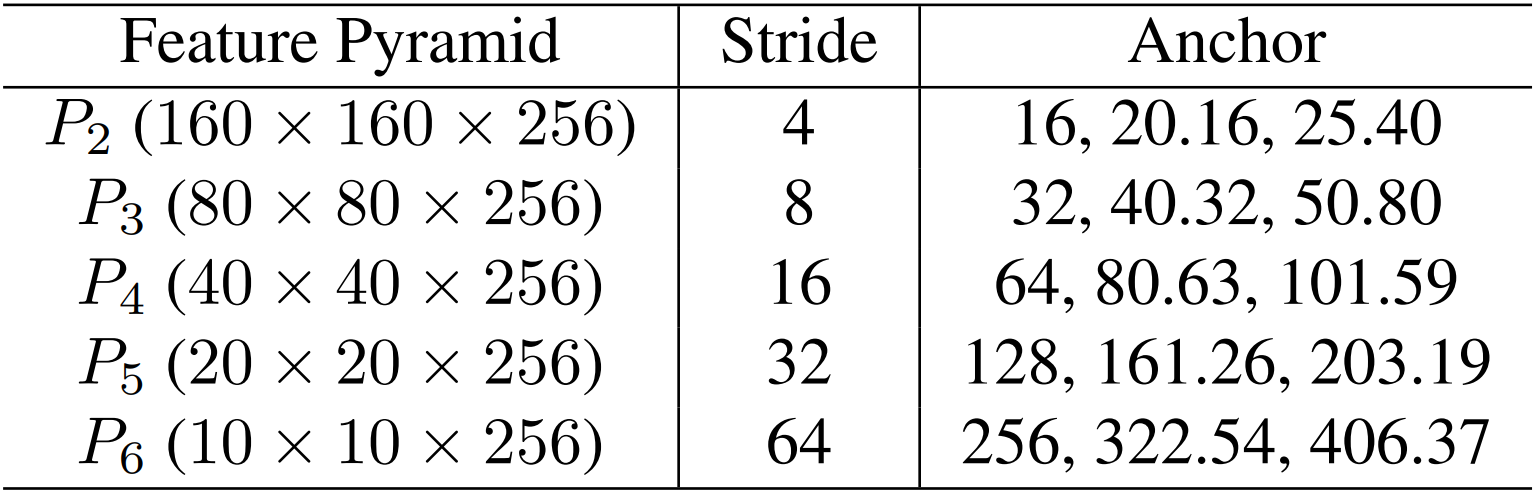
The details of feature pyramid, stride size, anchor in RetinaFace. For a 640 × × × 640 input image, there are 102,300 anchors in total, and 75 % 75\% 75% of these anchors are tiled on P 2 P_2 P2.
•从上面的描述中可以看出作者对anchor选取的细节,作者选取的anchor纵横比为1,即是一个正方形的框,对于anchor的尺寸,作者从初始的 16 × 16 16×16 16×16按照 2 1 3 {2^{\frac{1}{3}}} 231扩增,依次得到 20.16 , 25.40 , . . . , 406.37 20.16,25.40,...,406.37 20.16,25.40,...,406.37等等,这样的精妙之处在于对特征金字塔的每一个level,可以选取三种不同尺寸的anchor,且每一个level的初始anchor均为 2 2 2的幂次方
在训练过程中,当IoU大于
0.5
0.5
0.5时,anchor与ground-truth box匹配,当IoU小于
0.3
0.3
0.3时,anchor与背景匹配。训练时忽略不匹配的anchor。由于大多数anchor(> 99%)在匹配步骤后是negative,我们采用OHEM标准来减轻正和负训练示例之间的显著不平衡。更具体地说,我们根据损失值对negative anchor进行排序,并选择最上面的anchor,以便负样本和正样本之间的比率至少为3:1
数据增强(Data Augmentation)
由于在WIDER FACE训练集中大约有
20
20%
20的微小人脸,我们遵循【《S. Zhang, X. Zhu, Z. Lei, H. Shi, X. Wang, and S. Z. Li. S3fd: Single shot scale-invariant face detector. 》、《 X. Tang, D. K. Du, Z. He, and J. Liu. Pyramidbox: A context-assisted single shot face detector.》】,从原始图像中随机裁剪正方形patch,并将这些面片大小调整为
640
×
640
640× 640
640×640,以生成更大的训练人脸。更具体地说,从原始图像中裁剪出正方形patch,其随机尺寸介于原始图像短边的
0.3
→
1
0.3\to1
0.3→1之间。对于裁剪边界上的人脸,如果它的中心在裁剪区域内,我们会保留人脸框的重叠部分。除了随机裁剪,我们还以
0.5
0.5
0.5概率的随机水平翻转以及光度颜色失真
训练细节(Training Details)
我们使用SGD优化器(动量为
0.9
0.9
0.9,权重衰减为
0.0005
0.0005
0.0005,batch size为
8
×
4
8 × 4
8×4)在四个NVIDIA Tesla P40(24GB)GPU上训练RetinaFace。学习率从
1
0
−
3
10^{-3}
10−3开始,5个epoch后上升到
1
0
−
2
10^{-2}
10−2,然后在55和68个epoch时除以
10
10
10,训练过程在80个epochs时结束
测试细节(Testing Details)
对于在WIDER FACE上的测试,我们遵循【《 M. Najibi, P . Samangouei, R. Chellappa, and L. S. Davis. Ssh: Single stage headless face detector. 》、《S. Zhang, X. Zhu, Z. Lei, H. Shi, X. Wang, and S. Z. Li. S3fd: Single shot scale-invariant face detector. 》】的标准实践,并采用翻转和多尺度(图像的短边在[500,800,1100,1400,1700]处)策略。Box投票应用于预测人脸框的并集,IoU阈值为
0.4
0.4
0.4
消融研究
为了更好地理解所提出的RetinaFace,我们进行了大量的消融实验,以检查所标注的五个facial landmarks和所提出的密集回归分支如何定量地影响面部检测的性能。除了在Easy,Medium和Hard子集上IoU=
0.5
0.5
0.5时的average precision(AP)评估指标之外,我们还利用了WIDER Face Challenge 2018的development server(Hard验证集),该server采用了更严格的评价指标
I
o
U
=
0.5
:
0.05
:
0.95
IoU=0.5:0.05:0.95
IoU=0.5:0.05:0.95的mAP,以奖励更精确的人脸检测器
如下表所示,我们评估了几种不同设置在WIDER FACE验证集上的性能,并重点观察了Hard集上的AP和mAP。通过应用SOTA技术(即FPN、上下文模块和可变卷积),我们建立了一个强baseline(
91.286
91.286%
91.286),略好于ISRN(
90.9
90.9%
90.9)。添加五个facial landmark回归分支显著提高了Hard集上的面部框AP (
0.408
%
0.408\%
0.408%)和mAP (
0.775
%
0.775\%
0.775%),这表明landmarks定位对于提高面部检测的准确性至关重要。相比之下,添加密集回归分支会增加Easy和Medium子集上的人脸面框AP,但会略微降低其在Hard子集上的表现,这表明在挑战性场景下,密集回归存在的困难。然而,与仅添加landmarks回归相比,学习landmarks和密集回归共同实现了进一步的改进。这表明landmarks回归确实有助于密集回归,进而进一步提高人脸检测性能
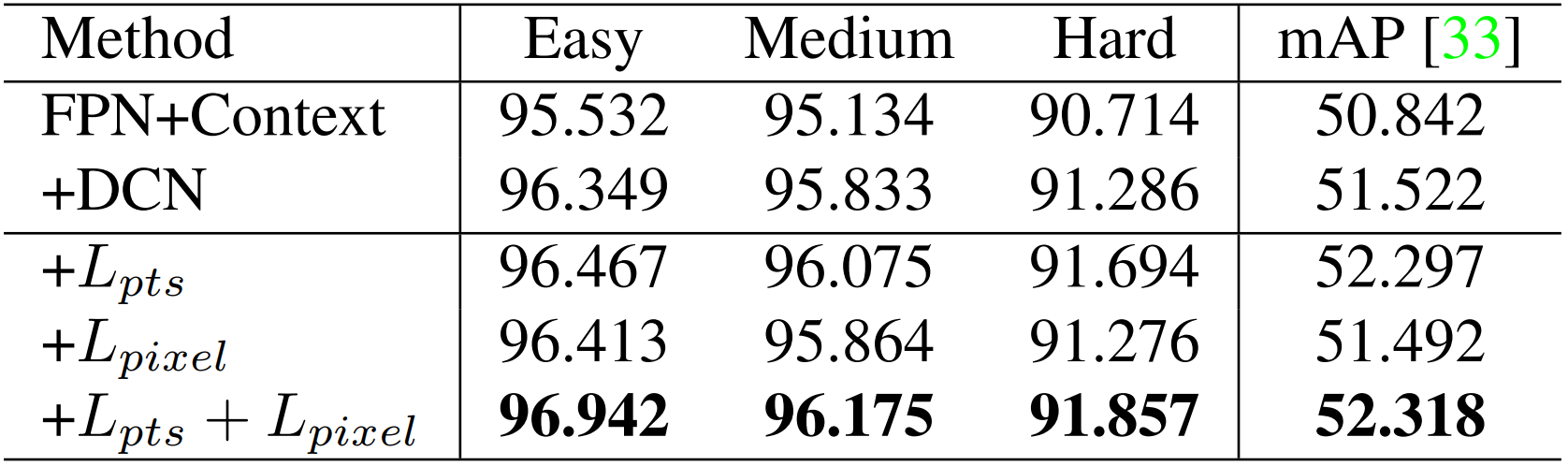
•从上面的表中可以看出对于表中第三行数据,其增加了 L p t s L_{pts} Lpts分支并获得了 91.694 % 91.694\% 91.694%的成绩,而对于其上一行仅采用FPN+Context+DCN所获得 91.286 % 91.286\% 91.286%相比,提高了 0.408 % 0.408\% 0.408%的AP和 0.775 % 0.775\% 0.775%mAP
人脸框准确率
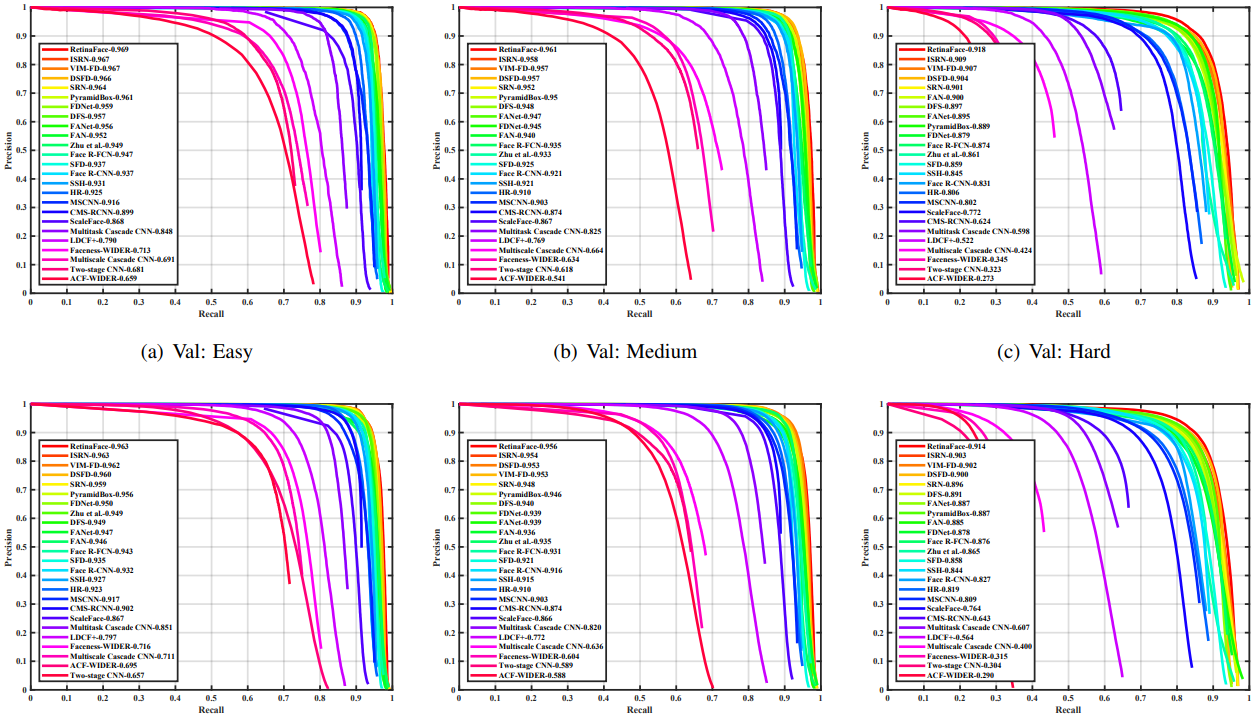
遵循WIDER FACE数据集的标准评估协议,我们只在训练集上训练模型,并在验证集和测试集上进行测试。为了获得在测试集的评估结果,我们将检测结果提交给组织人员进行评估。如下图所示,我们将提出的RetinaFace与其他
24
24
24种最SOTA人脸检测算法进行比较(Multiscale Cascade CNN, Two-stage CNN, ACF-WIDER, Faceness-WIDER, Multitask Cascade CNN, CMS-RCNN, LDCF+《E. Ohn-Bar and M. M. Trivedi. To boost or not to boost? on the limits of boosted trees for object detection.》, HR, Face R-CNN [54], ScaleFace, SSH, SFD, Face R-FCN [57], MSCNN [4], FAN, Zhu et al., Pyramid-Box [49], FDNet, SRN, FANet, DSFD, DFS, VIM-FD, ISRN)。就AP而言,我们的方法优于这些SOTA方法。更具体地是,在验证集和测试集的所有子集中,RetinaFace产生了最佳AP,即验证集
96.9
%
96.9\%
96.9%(Easy)、
96.1
%
96.1\%
96.1%(Medium)和
91.8
%
91.8\%
91.8%(Hard),测试集为
96.3
%
96.3\%
96.3%(Easy)、
95.6
%
95.6\%
95.6%(Medium)和
91.4
%
91.4\%
91.4%(Hard)。与最近表现最好的方法《S. Zhang, R. Zhu, X. Wang, H. Shi, T. Fu, S. Wang, and T. Mei. Improved selective refinement network for face detection.》相比,RetinaFace在包含大量微小人脸的Hard子集上实现了最佳性能(
91.4
%
v
.
s
.
90.3
%
91.4\% v.s. 90.3\%
91.4%v.s.90.3%)
在下图中,我们用一张密集面孔自拍来定性说明结果。在报告的
1151
1151
1151张人脸中,RetinaFace成功地找到了大约900张人脸(
t
h
r
e
s
h
o
l
d
=
0.5
threshold=0.5
threshold=0.5)。除了精确的边界框,RetinaFace预测的五个facial landmarks在姿态、遮挡和分辨率变化的情况下也具有鲁棒性。尽管在严重遮挡的情况下存在一些密集人脸定位失败的情况,但在一些清晰的大脸上,密集回归的结果是好的,甚至能适应不同的表情变化

五个面部标志的准确性
为了评估五个facial landmarks定位的准确性,我们在AFLW数据集(
24386
24386
24386张人脸)以及WIDER FACE验证集(
18.5
k
18.5k
18.5k个面部)上比较了RetinaFace和MTCNN。在这里,我们使用face box尺寸(
W
×
H
\sqrt {W \times H}
W×H)作为标准化距离。如下图(a)所示,我们在AFLW数据集上给出了每个facial landmark的平均误差。与MTCNN相比,RetinaFace可以将标准化平均误差(NME, normalised mean errors)从
2.72
%
2.72%
2.72%降到
2.21
%
2.21%
2.21%。在下图(b)中,我们显示了WIDER FACE验证集上的累积误差分布(CED, cumulative error distribution)曲线。与MTCNN相比,RetinaFace将失败率从
26.31
%
26.31%
26.31%显着降到
9.37
%
9.37%
9.37%(NME阈值为
10
%
10%
10%)
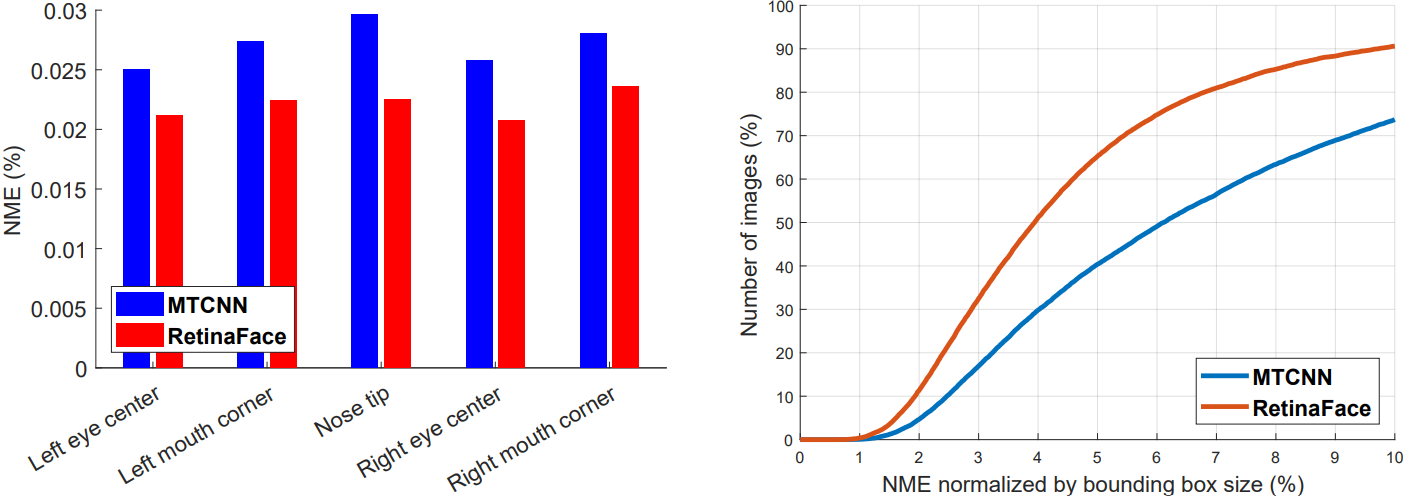
密集面部地标精度
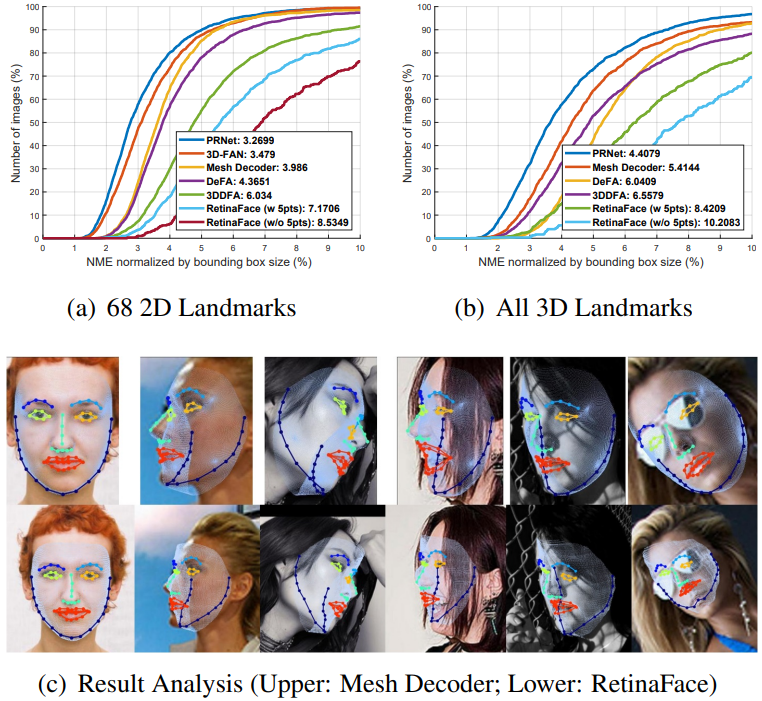
除了box和五个facial landmarks外,RetinaFace还输出密集的面部对应关系,但是密集回归分支仅通过自我监督学习进行训练。根据【《Y . Feng, F. Wu, X. Shao, Y . Wang, and X. Zhou. Joint 3d face reconstruction and dense alignment with position map regression network.》、《Y . Zhou, J. Deng, I. Kotsia, and S. Zafeiriou. Dense 3d face decoding over 2500fps: Joint texture and shape convolutional mesh decoders. 》】,我们考虑(1)具有2D投影坐标的68 landmarks和(2)所有3D坐标的landmarks,在AFLW2000-3D数据集上评估密集facial landmark定位的准确性。在这里,平均误差仍通过边界框大小归一化[75]。在下图(a)和(b)中,我们展示了SOTA方法和RetinaFace的CED曲线。即使在监督和自监督方法之间存在性能差距,RetinaFace的密集回归结果仍可与这些SOTA方法相媲美。更具体地说,我们观察到(1)五个facial landmarks回归可以减轻密集回归分支的训练难度,并显着改善密集回归结果。(2)使用单阶段特征(如RetinaFace)来预测密集的对应参数比采用(Region of Interest)RoI特征(如Mesh Decoder)要困难得多。如上图©所示,RetinaFace可以轻松处理具有姿势变化的脸部,但在复杂场景则会变得困难。这表明未对齐和过于紧凑的特征表示(RetinaFace中的
1
×
1
×
256
1×1×256
1×1×256)阻碍了单阶段框架实现高精度密集回归输出。然而,如在消融研究部分所证实的那样,在密集的回归分支中投影的面部区域仍具有注意力的作用,这可以帮助改善面部检测。
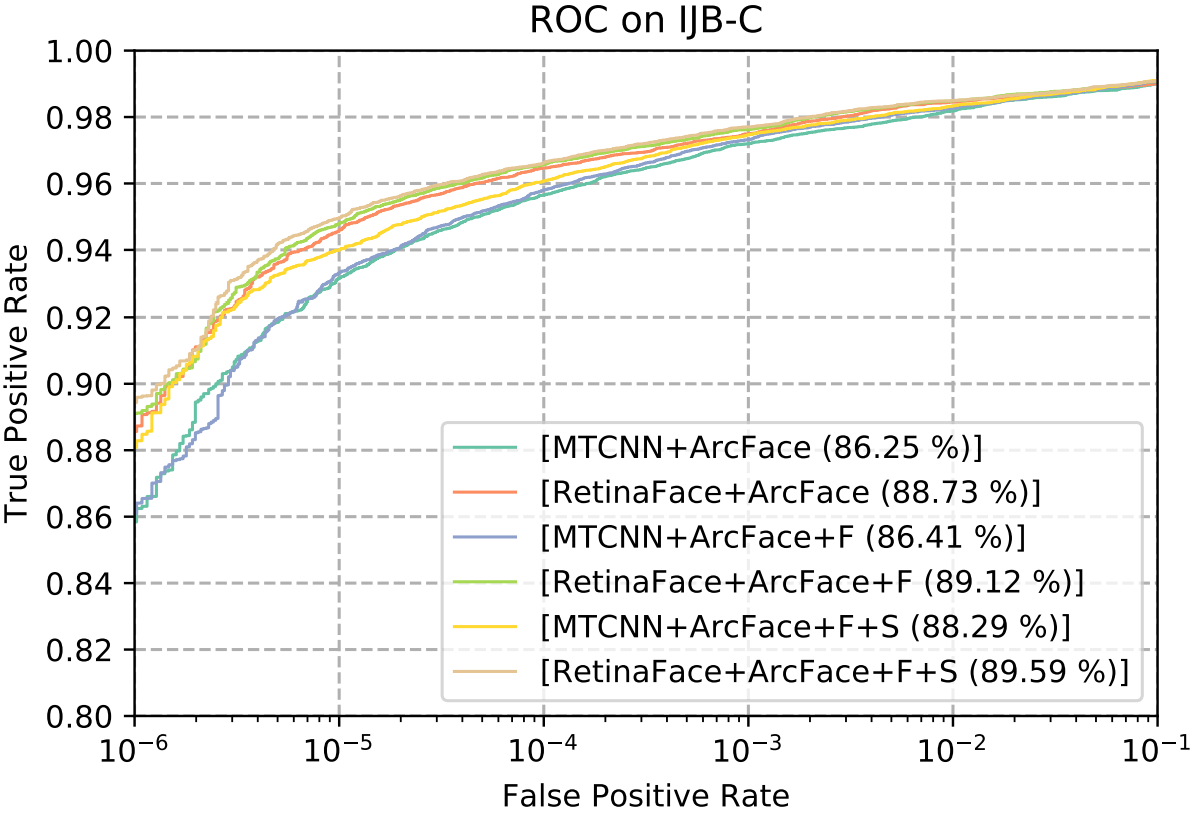
人脸识别精度
人脸检测在鲁棒的人脸识别中起着至关重要的作用,但其效果很少得到明确测量。在本文中,我们演示了我们的人脸检测方法如何提高最先进的公开可用人脸识别方法(即ArcFace)的性能。 ArcFace研究了深度卷积神经网络训练过程中的不同方面(即训练集的选择,网络和损失函数)是如何影响大规模人脸识别性能。但是,ArcFace论文并没有仅将MTCNN用于检测和对齐来研究面部检测的影响。在本文中,我们用RetinaFace代替MTCNN以检测并对齐所有训练数据(即MS1M)和测试数据(即LFW,CFP-FP,AgeDB-30和IJBC),并保持嵌入网络(即ResNet100)和损失函数(additive angular margin)与ArcFace完全相同
在下表中,我们通过比较广泛使用的MTCNN和提出的RetinaFace,显示了面部检测和对齐对深层面部识别(即ArcFace)的影响。 CFP-FP上的结果表明,RetinaFace可以将ArcFace的验证准确性从
98.37
%
98.37%
98.37%提高到
99.49
%
99.49%
99.49%。该结果表明,frontal-profile人脸验证的性能现在已接近frontal-frontal人脸验证的性能(例如,LFW上为
99.86
%
99.86%
99.86%)

在下图中,我们在每个图例的末尾显示了IJB-C数据集上的ROC曲线以及
F
A
R
=
1
e
−
6
FAR = 1e-6
FAR=1e−6的
T
A
R
TAR
TAR。我们采用两种技巧(即翻转测试和面部检测得分来权衡模板中的样本)来逐步提高面部验证的准确性。经过公平的比较,只需用RetinaFace代替MTCNN,
T
A
R
TAR
TAR(在
F
A
R
=
1
e
−
6
FAR = 1e-6
FAR=1e−6时)就可以从
88.29
%
88.29%
88.29%显着提高到
89.59
%
89.59%
89.59%。这表明(1)人脸检测和对齐严重影响人脸识别性能,(2)对于人脸识别应用来说,RetinaFace是一个比MTCNN强得多的baseline
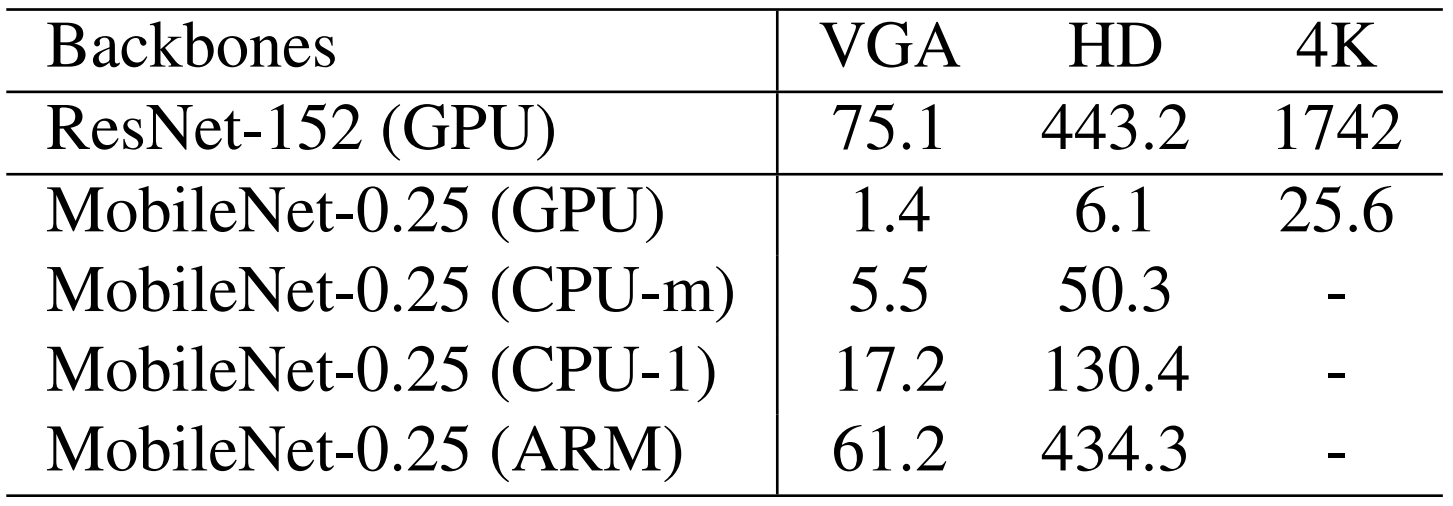
推理效率
在测试过程中,RetinaFace在单阶段执行人脸定位,这既灵活又高效。除了上述探索的重量级模型(ResNet-152,大小为262MB,在WIDER FACE的hard数据集上的AP为
91.8
%
91.8%
91.8%)外,我们还采用了轻量级模型(MobileNet-0.25,大小为1MB) ,在WIDER FACE的hard数据集上AP为
78.2
%
78.2%
78.2%)以加快推理速度
对于轻量级模型,我们可以通过在输入图像以及
P
3
P3
P3,
P
4
P4
P4和
P
5
P5
P5上平铺的密集anchor使用
s
t
r
i
d
e
=
4
stride = 4
stride=4的
7
×
7
7×7
7×7卷积并移除deformable layers来快速减小数据大小。此外,通过固定ImageNet预训练模型初始化的前两个卷积层以实现更高的精度
下表给出了两个模型关于不同输入大小的推理时间。我们忽略了密集回归分支上的时间成本,因此时间统计信息与输入图像的面部密度无关。我们利用TVM来加快模型推理,并分别在NVIDIA Tesla P40 GPU,Intel i76700K CPU和ARM-RK3399上测试推理速度。 RetinaFace-ResNet-152专为高度精确的人脸定位而设计,运行VGA图像(
640
×
480
640×480
640×480)能达到13FPS。相比之下,RetinaFace-MobileNet-0.25专为高效的人脸定位而设计,可在
4
K
4K
4K图像(
4096
×
2160
4096×2160
4096×2160)的GPU上跑出40FPS的实时速度,在HD图像(
1920
×
1080
1920×1080
1920×1080)的多线程CPU上跑出20 FPS的实时速度。 ),在单线程CPU上输入VGA图像(
640
×
480
640×480
640×480)提供能达到60 FPS。更令人印象深刻的是,ARM上输入VGA图像(
640
×
480
640×480
640×480)能达到16 FPS,这允许在移动设备上快速运行
结论
本文研究了图像中任意比例人脸的同时密集定位和对准的挑战性问题,并且本文第一个提出了单阶段解决方案(RetinaFace)。在当前最具挑战性的人脸检测基准中,我们的解决方案优于最先进的方法。此外,当RetinaFace与SOTA人脸识别实践相结合时,它明显提高了准确性。本文的数据和模型已公开提供,以促进对该专题的进一步研究
Acknowledgements
Jiankang Deng acknowledges financial support from the Imperial President’s PhD Scholarship and GPU donations from NVIDIA. Stefanos Zafeiriou acknowledges support from EPSRC Fellowship DEFORM (EP/S010203/1), FACER2VM (EP/N007743/1) and a Google Faculty Fellowship.
获取更多
资源地址
RetinaFace PyTorch版本
RetinaFace Caffe版本
RetinaFace PaddlePaddle版本【待定】
关于作者

| 姓名 | 郭权浩 |
|---|---|
| 学校 | 电子科技大学硕士研究生 |
| 研究方向 | 计算机视觉,CV方向 |
| 主页 | DeepHao的主页 |
| 如有错误,请及时留言纠正,非常蟹蟹!后续会有更多论文研读系列推出,欢迎大家有问题留言交流学习,共同进步成长! |














 49
49











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









