







 NT-Xent是SimCLR中提出的对比学习损失函数,它通过最大化正样本对之间的相似度和最小化负样本对之间的相似度来训练模型。在softmax基础上,NT-Xent考虑了温度参数,当温度小于1时,预测更确定;大于1时,预测更分散。最终目标是使同类样本聚集,异类样本分离。
NT-Xent是SimCLR中提出的对比学习损失函数,它通过最大化正样本对之间的相似度和最小化负样本对之间的相似度来训练模型。在softmax基础上,NT-Xent考虑了温度参数,当温度小于1时,预测更确定;大于1时,预测更分散。最终目标是使同类样本聚集,异类样本分离。
NT-Xent (the normalized temperature-scaled cross entropy loss)
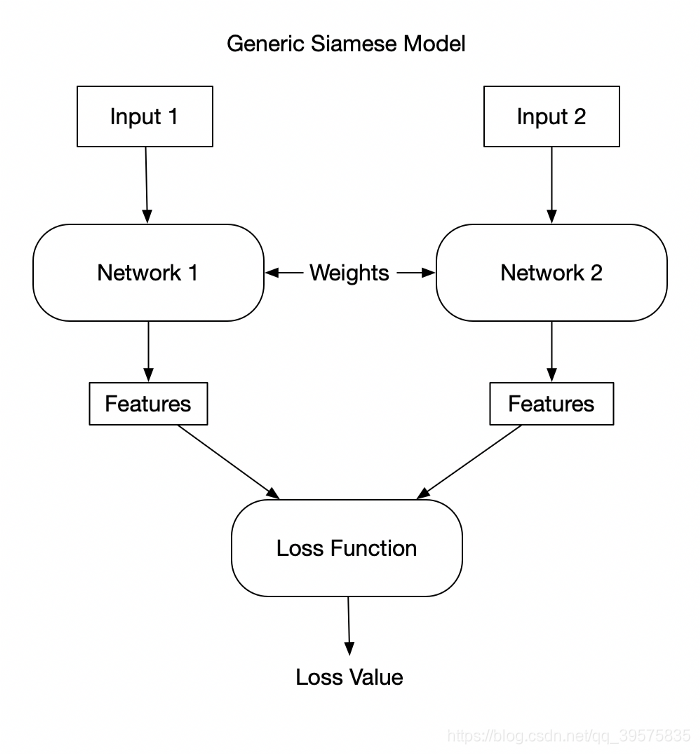
- NT-Xent
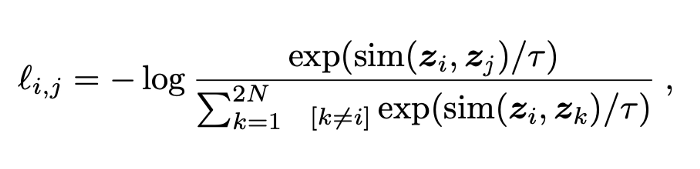
NT-Xent 出自Simclr。一个batch N 个samples,因为有两条分支就是2N个samples,除了对应的augmented image和自己,其余2N-2都应该被视作negative pair。上式中,i,j 是positive pair,分母是negative pair。
NT-Xent 看起来像softmax函数。 这是因为,加上向量相似度和温度归一化因子。 相似度函数只是余弦距离。 另一个不同之处是分母中的值是从正例到负样本的符号距离。 与CrossEntropyLoss没有太大区别。 直觉是我们希望我们的相似向量尽可能接近1,因为-log(1)= 0,这是最佳损失。 我们希望否定示例接近0,因为任何非零值都将减少相似向量的值。
温度系数
If the temperature is less than 1, the softmax predictions become more confident. This is also referred to as “hard” softmax probabilities. If T is greater than 1, then the predictions are less confident (also called “soft” probabilities). Softer probabilities provide more information from the network as to which classes seem similar to the target class.
如果温度小于 1,softmax 预测变得更有信心。 这也称为“硬”softmax 概率(我理解会sharpen输出)。 如果 T 大于 1,则预测的可信度较低(也称为“软”概率)。 较软的概率从网络中提供了更多关于哪些类看起来与目标类相似的信息。
- 最后得到的效果
同类相聚,异类相离
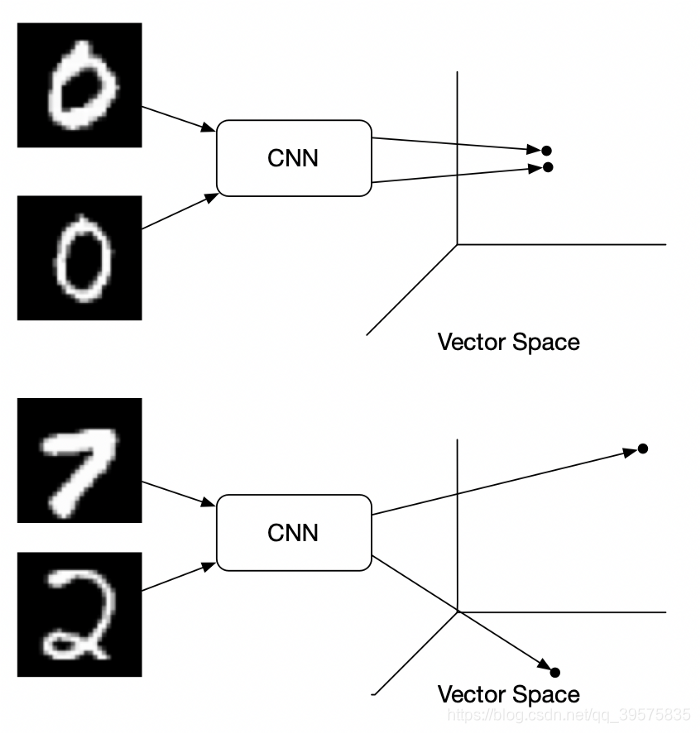
reference:
https://towardsdatascience.com/contrastive-loss-explaned-159f2d4a87ec

















 1567
1567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









