







摘要
我们介绍了Jukebox,这是一个在原始音频领域生成带有歌唱的音乐的模型。我们使用多尺度VQ-VAE来压缩原始音频的长上下文到离散代码,并使用自回归Transformer来建模这些代码。我们展示了,大规模的组合模型可以生成高保真度和多样性的歌曲,其连贯性可达数分钟。我们可以根据艺术家和流派来引导音乐和歌唱风格,并根据未对齐的歌词来使歌唱更加可控。我们发布了数千个未经挑选的样本,以及模型权重和代码。
1.引言
音乐是人类文化的一个组成部分,从人类文明的最早时期就存在,并演变成多种形式。它在创作中唤起了独特的人类精神,计算机是否能够捕捉这一创作过程的问题已经吸引了计算机科学家数十年。我们已经有算法生成钢琴乐谱(Hiller Jr & Isaacson, 1957; Moorer, 1972; Hadjeres et al., 2017; Huang et al., 2017),数字声码器生成歌手的声音(Bonada & Serra, 2007; Saino et al., 2006; Blaauw & Bonada, 2017),以及合成器产生各种乐器的音色(Engel et al., 2017; 2019)。每个都捕捉了音乐生成的一个特定方面:旋律、作曲、音色和人类歌唱的声音。然而,一个能够完成所有这些任务的单一系统仍然难以捉摸。
生成模型领域在过去几年取得了巨大进展。生成建模的一个目标是捕捉数据的显著方面,并生成与真实数据无法区分的新实例。假设通过学习生成数据,我们可以学习数据的最佳特征1。我们被视觉、音频和文本领域的高度复杂分布所包围,近年来我们在文本生成(Radford et al.)、语音生成(Xie et al., 2017)和图像生成(Brock et al., 2019; Razavi et al., 2019)方面取得了进展。这个领域的进展速度很快,仅仅几年前我们还有算法生成模糊的面孔(Kingma & Welling, 2014; Goodfellow et al., 2014),但现在我们可以生成与真实面孔无法区分的高分辨率面孔(Zhang et al., 2019b)。
生成模型也被应用于音乐生成任务。早期的模型以钢琴卷的形式符号化地生成音乐,钢琴卷指定了每个音符的播放时间、音高、力度和乐器(Yang et al., 2017; Dong et al., 2018; Huang et al., 2019a; Payne, 2019; Roberts et al., 2018; Wu et al., 2019)。符号化方法通过在低维空间中处理问题使建模问题变得更容易。然而,它将可以生成的音乐限制为特定的音符序列和固定的乐器集来渲染。与此同时,研究人员一直在追求非符号化方法,他们尝试直接生成音频形式的音乐。这使得问题更具挑战性,因为原始音频的空间极其高维,具有大量的信息内容需要建模。已经取得了一些成功,模型在原始音频领域(Oord et al., 2016; Mehri et al., 2017; Yamamoto et al., 2020)或频谱图领域(Vasquez & Lewis, 2019)生成钢琴曲。关键瓶颈是直接建模原始音频引入了极长的依赖关系,使得学习音乐的高级语义在计算上具有挑战性。降低难度的一种方法是学习音频的低维编码,目标是丢失不太重要的信息,但保留大部分音乐信息。这种方法在生成仅限于几种乐器的短乐器曲目方面已经展示了一些成功(Oord et al., 2017; Dieleman et al., 2018)。
在这项工作中,我们展示了我们可以使用最先进的深度生成模型来生成一个能够在原始音频领域生成多样化高保真音乐的单一系统,其长距离连贯性跨越数分钟。我们的方法使用分层VQ-VAE架构(Razavi et al., 2019)将音频压缩到离散空间,损失函数设计为保留最大量的音乐信息,同时在增加压缩级别的情况下这样做。我们使用自回归稀疏Transformer(Child et al., 2019; Vaswani et al., 2017)在这个压缩空间上进行最大似然估计训练,并且还训练自回归上采样器以在每个压缩级别上重建丢失的信息。
我们展示了我们的模型可以生成来自高度多样化音乐流派(如摇滚、嘻哈和爵士)的歌曲。它们可以捕捉旋律、节奏、长距离作曲和各种乐器的音色,以及歌手的风格和声音与音乐一起生成。我们还可以生成现有歌曲的新颖完成。我们的方法允许影响生成过程的选项:通过用条件先验替换顶部先验,我们可以根据歌词来告诉歌手唱什么,或者根据midi来控制作曲。我们在https://github.com/openai/jukebox发布了我们的模型权重以及训练和采样代码。
2. 背景
我们考虑将原始音频域中的音乐表示为连续波形 x ∈ [ − 1 , 1 ] T \mathbf{x}\in[-1,1]^T x∈[−1,1]T,其中样本数 T T T 是音频时长与采样率(通常从16 kHz到48 kHz)的乘积。对于音乐来说,CD质量的音频,即44.1 kHz采样率并以16位精度存储的音频,通常足以捕捉人类可感知的频率范围。例如,一个四分钟长的音频段将具有约1000万个输入长度,其中每个位置可以包含16位信息。相比之下,一个高分辨率的RGB图像,具有 1024 × 1024 1024\times 1024 1024×1024像素,其输入长度约为300万,每个位置包含24位信息。这使得学习音乐生成模型在计算上极为苛刻,尤其是随着时长的增加;我们必须捕捉从音色到全局连贯性的广泛音乐结构,同时建模大量的多样性。
2.1 VQ-VAE
为了使这一任务可行,我们使用VQ-VAE(Oord等,2017;Dieleman等,2018;Razavi等,2019)将原始音频压缩到低维空间。一维VQ-VAE学习使用一系列离散标记 z = ⟨ z s ∈ [ K ] ⟩ s = 1 S z=\langle z_s\in[K]\rangle_{s=1}^{S} z=⟨zs∈[K]⟩s=1S 来编码输入序列 x = ⟨ x t ⟩ t = 1 T \mathbf{x}=\langle\mathbf{x}_{t}\rangle_{t=1}^{T} x=⟨xt⟩t=1T,其中 K K K 表示词汇大小,我们称比率 T / S T/S T/S 为跳跃长度。它由一个编码器 E ( x ) E(\mathbf{x}) E(x) 组成,该编码器将 x \mathbf{x} x 编码为一系列潜在向量 h = ⟨ h s ⟩ s = 1 S \mathbf{h}=\langle\mathbf{h}_{s}\rangle_{s=1}^{S} h=⟨hs⟩s=1S,一个瓶颈通过将每个 h s \mathbf{h}_s hs 映射到其最近的向量 e z s \mathbf{e}_{z_{s}} ezs 从码本 C = { e k } k = 1 K C=\{\mathbf{e}_{k}\}_{k=1}^{K} C={ek}k=1K 来量化 h s ↦ e z s \mathbf{h}_s\mapsto\mathbf{e}_{z_s} hs↦ezs,以及一个解码器 D ( e ) D(\mathbf{e}) D(e),该解码器将嵌入向量解码回输入空间。因此,它是一个具有离散化瓶颈的自编码器。VQ-VAE使用以下目标进行训练:
L = L r e c o n s + L c o d e b o o k + β L c o m m i t L r e c o n s = 1 T ∑ t ∥ x t − D ( e z t ) ∥ 2 2 L c o d e b o o k = 1 S ∑ s ∥ s g [ h s ] − e z s ∥ 2 2 L c o m m i t = 1 S ∑ s ∥ h s − s g [ e z s ] ∥ 2 2 \begin{aligned}\mathcal{L}&=\:\mathcal{L}_{\mathrm{recons}}+\mathcal{L}_{\mathrm{codebook}}+\beta\mathcal{L}_{\mathrm{commit}}\\\mathcal{L}_{\mathrm{recons}}&=\:\frac{1}{T}\sum_{t}\|\mathbf{x}_{t}-D(\mathbf{e}_{z_{t}})\|_{2}^{2}\\\mathcal{L}_{\mathrm{codebook}}&=\:\frac{1}{S}\sum_{s}\|\mathrm{sg}\:[\mathbf{h}_{s}]-\mathbf{e}_{z_{s}}\|_{2}^{2}\\\mathcal{L}_{\mathrm{commit}}&=\:\frac{1}{S}\sum_{s}\|\mathbf{h}_{s}-\mathrm{sg}\:[\mathbf{e}_{z_{s}}]\|_{2}^{2}\end{aligned} LLreconsLcodebookLcommit=Lrecons+Lcodebook+βLcommit=T1t∑∥xt−D(ezt)∥22=S1s∑∥sg[hs]−ezs∥22=S1s∑∥hs−sg[ezs]∥22
其中,sg表示停止梯度操作,在反向传播期间传递零梯度。重建损失 L recons \mathcal{L}_\text{recons} Lrecons 惩罚输入 x \mathbf{x} x 和重建输出 x ^ = D ( e z ) \widehat{\mathbf{x}}=D(\mathbf{e}_{z}) x =D(ez)之间的距离,而 L c o d e b o o k \mathcal{L}_\mathrm{codebook} Lcodebook 惩罚码本中编码 h \mathbf{h} h 与其最近邻 e z \mathbf{e}_z ez 之间的距离。为了稳定编码器,我们还添加了 L c o m m i t \mathcal{L}_\mathrm{commit} Lcommit 以防止编码波动过大,其中权重 β \beta β 控制此损失的贡献量。为了加速训练,码本损失 L c o d e b o o k \mathcal{L}_\mathrm{codebook} Lcodebook 改为使用码本变量的EMA更新。Razavi等(2019)将其扩展为分层模型,他们训练单个编码器和解码器,但将潜在序列 h \mathbf{h} h 分解为多级表示 [ h ( 1 ) , ⋯ , h ( L ) ] [\mathbf{h}^{(1)},\cdots,\mathbf{h}^{(L)}] [h(1),⋯,h(L)],序列长度递减,每个级别学习自己的码本 C ( l ) C^{(l)} C(l)。他们使用非自回归编码器-解码器,并使用简单的均方损失联合训练所有级别。
3. 音乐VQ-VAE
受分层VQ-VAE模型(Razavi等,2019)在图像领域成果的启发,我们考虑将相同的技术应用于建模原始音频,使用三种不同的抽象级别,如图1所示。在每一级别,我们使用由WaveNet风格的非因果一维扩张卷积组成的残差网络,并与下采样和上采样一维卷积交错以匹配不同的跳跃长度。架构的详细描述见附录B.1。与(Oord等,2017;Razavi等,2019)中的VQ-VAE相比,我们对VQ-VAE进行了多项修改,如下文所述。
3.1. 嵌入的随机重启
VQ-VAE已知会遭受码本崩溃的问题,即所有编码都被映射到单个或少数几个嵌入向量,而码本中的其他嵌入向量未被使用,从而降低了瓶颈的信息容量。为了防止这种情况,我们使用随机重启:当码本向量的平均使用率低于某个阈值时,我们将其随机重置为当前批次中的一个编码器输出。这确保了码本中的所有向量都被使用,因此具有学习的梯度,从而缓解了码本崩溃的问题。
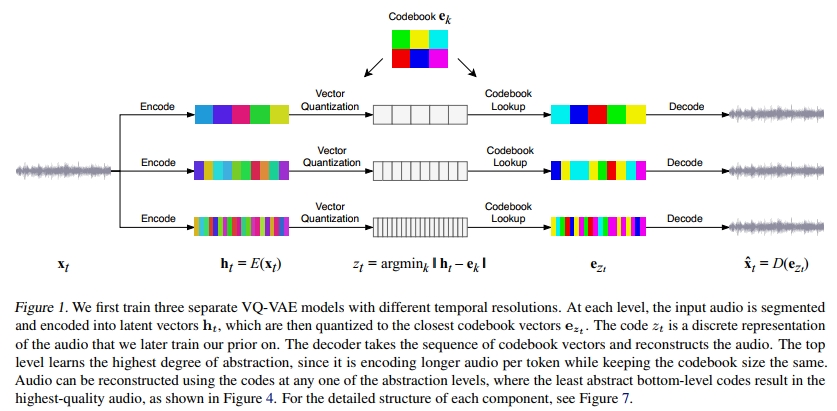
3.2. 分离的自编码器
当使用(Razavi等,2019)中的分层VQ-VAE处理原始音频时,我们观察到瓶颈化的顶层利用率非常低,有时甚至完全崩溃,因为模型决定通过瓶颈较小的较低层级传递所有信息。为了最大化每一层级存储的信息量,我们简单地训练具有不同跳跃长度的独立自编码器。每一层级的离散代码可以被视为输入在不同压缩级别下的独立编码。
3.3. 频谱损失
当仅使用样本级重建损失时,模型仅学习重建低频部分。为了捕捉中高频部分,我们添加了频谱损失,其定义为:
L s p e c = ∥ ∣ S T F T ( x ) ∣ − ∣ S T F T ( x ^ ) ∣ ∥ 2 \mathcal{L}_{\mathrm{spec}}=\||\mathrm{STFT}(\mathbf{x})|-|\mathrm{STFT}(\widehat{\mathbf{x}})|\|_{2} Lspec=∥∣STFT(x)∣−∣STFT(x )∣∥2
它鼓励模型匹配频谱成分,而无需关注相位(相位更难学习)。这与在训练原始音频的并行解码器时使用的功率损失(Oord等,2018)和频谱收敛(Arık等,2018b)类似。后一种方法与我们的方法之间的一个区别在于,我们不再优化频谱信噪比;对于大部分静音的输入,除以信号的幅度会导致数值不稳定。为了防止模型对特定STFT参数选择过拟合,我们使用在多个STFT参数上计算的频谱损失 L spec L_{\text{spec}} Lspec 的总和,这些参数在时间和频率分辨率之间进行权衡(Yamamoto等,2020)。
4. 音乐先验和上采样器
在训练完VQ-VAE之后,我们需要在压缩空间上学习一个先验分布 p ( z ) p(\mathbf{z}) p(z) 以生成样本。我们将先验模型分解为:
p ( z ) = p ( z t o p , z m i d d l e , z b o t t o m ) = p ( z t o p ) p ( z m i d d l e ∣ z t o p ) p ( z b o t t o m ∣ z m i d d l e , z t o p ) \begin{aligned}p(\mathbf{z})&=p(\mathbf{z^{top}},\mathbf{z^{middle}},\mathbf{z^{bottom}})\\&=p(\mathbf{z^{top}})p(\mathbf{z^{middle}}|\mathbf{z^{top}})p(\mathbf{z^{bottom}}|\mathbf{z^{middle}},\mathbf{z^{top}})\end{aligned} p(z)=p(ztop,zmiddle,zbottom)=p(ztop)p(zmiddle∣ztop)p(zbottom∣zmiddle,ztop)
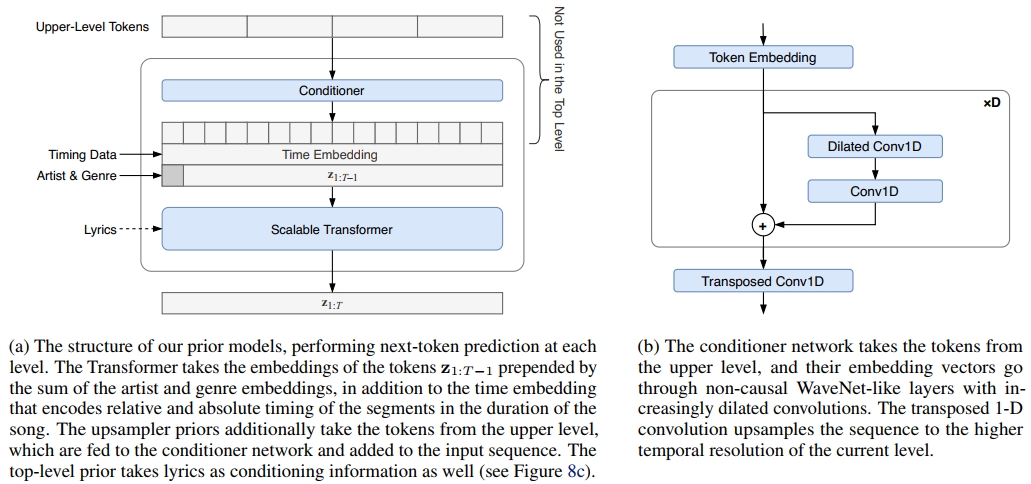
并为顶层先验 p ( z t o p ) p(\mathbf{z}^{\mathrm{top}}) p(ztop) 和上采样器 p ( z m i d d l e ∣ z t o p ) p(\mathbf{z}^{\mathrm{middle}}|\mathbf{z}^{\mathrm{top}}) p(zmiddle∣ztop) 以及 p ( z b ^ o t t o m ∣ z m ^ i d d l e , z t o p ) p(\mathbf{z}^{\mathbf{\hat{b}}\mathrm{ottom}}|\mathbf{z}^{\mathbf{\hat{m}}\mathrm{iddle}},\mathbf{z}^{\mathrm{top}}) p(zb^ottom∣zm^iddle,ztop) 分别训练独立的模型。这些都是VQ-VAE生成的离散标记空间中的自回归建模问题。我们使用具有稀疏注意力机制的Transformer(Vaswani等,2017;Child等,2019),因为它们是当前自回归建模领域的最先进技术。我们提出了一种简化版本,称为可扩展Transformer,它更易于实现和扩展(详见附录A)。
对于上采样器,我们需要为自回归Transformer提供来自上层代码的条件信息。为此,我们使用深度残差WaveNet(Xie等,2017),后接一个上采样步幅卷积和层归一化(Ba等,2016),并将其输出作为额外的位置信息添加到当前层级的嵌入中。我们仅将下层条件限制在与原始音频相同片段对应的上层代码块上。在每一层级,我们在相同上下文长度的离散代码上使用Transformer,这对应于随着跳跃长度的增加而增加的原始音频长度,并在更高层级上建模更长的时间依赖性,同时保持每一层级训练的计算开销不变。由于我们的VQ-VAE是卷积的,因此可以使用相同的VQ-VAE为任意长度的音频生成代码。
4.1. 艺术家、流派和时间条件
通过在训练时提供额外的条件信号,我们的生成模型可以变得更加可控。对于我们的初始模型,我们为歌曲提供了艺术家和流派标签。这有两个优点:首先,它降低了音频预测的熵,因此模型能够在任何特定风格中实现更好的质量。其次,在生成时,我们能够引导模型生成我们选择的风格。此外,我们在训练时为每个片段附加了一个时间信号。该信号包括作品的总时长、该特定样本的开始时间以及歌曲已经播放的比例。这使得模型能够学习依赖于整体结构的音频模式,例如口语或乐器介绍以及作品结束时的掌声。
4.2. 歌词条件
虽然上述条件模型能够生成多种流派和艺术风格的歌曲,但这些模型生成的歌声,尽管通常以引人入胜的旋律演唱,但大多由无意义的音节组成,很少产生可识别的英语单词。为了能够通过歌词控制生成模型,我们在训练时通过为模型提供与每个音频片段对应的歌词来提供更多上下文,使模型能够同时生成音乐和歌声。
歌词到歌声(LTS)任务:条件信号仅包括歌词的文本,没有时间或发声信息。因此,我们必须建模歌词和歌声的时间对齐、艺术家的声音以及根据音高、旋律、节奏甚至歌曲流派的不同演唱方式的多样性。条件数据并不精确,因为歌词数据通常包含对重复部分(如“合唱”)的文本引用,或者歌词与相应音乐部分不匹配的部分。目标音频中也没有主唱、伴唱和背景音乐的分离。这使得歌词到歌声(LTS)任务比相应的文本到语音(TTS)任务更具挑战性。
为音频块提供歌词:我们的数据集包括歌曲级别的歌词,但为了使任务更容易,我们在较短的(24秒)音频块上进行训练。为了在训练期间提供与音频对应的歌词,我们从一个简单的启发式方法开始,


将歌词的字符线性对齐到每首歌曲的持续时间,并在训练期间传递以当前片段为中心的固定大小字符窗口。虽然这种线性对齐的简单策略效果出奇地好,但我们发现它对于某些流派(如快节奏歌词的嘻哈音乐)会失败。为了解决这个问题,我们使用Spleeter(Hennequin等,2019)从每首歌曲中提取人声,并在提取的人声上运行NUS AutoLyricsAlign(Gupta等,2020)以获得歌词的单词级对齐,使我们能够更准确地为给定的音频块提供歌词。我们选择一个足够大的窗口,以确保实际歌词有很大概率出现在窗口内。
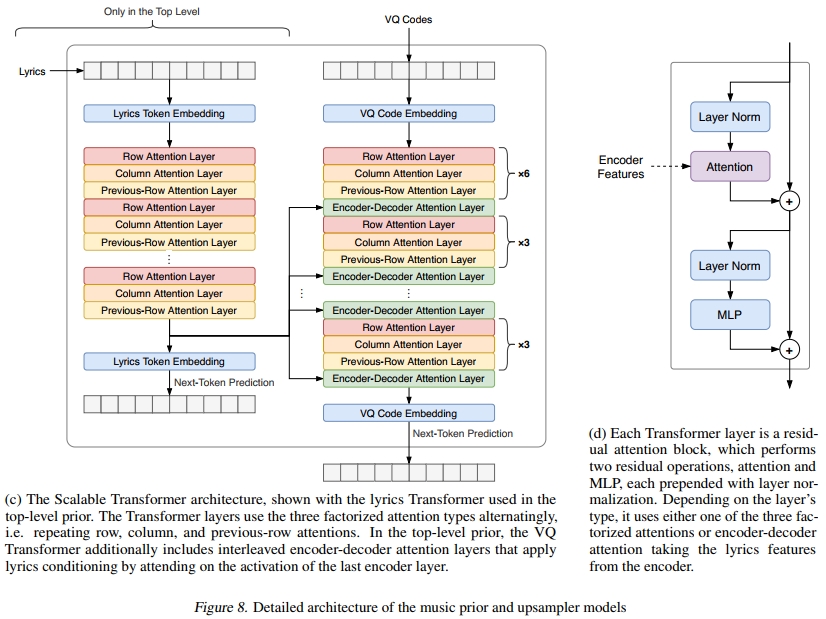
编码器-解码器模型:我们使用编码器-解码器风格的模型来对歌词字符进行条件处理,编码器从歌词中生成特征,解码器生成顶级音乐标记并关注这些特征。歌词编码器是一个具有自回归建模损失的Transformer,其最后一层用作歌词的特征。在音乐解码器中,我们交错了一些额外的层,这些层具有编码器-解码器注意力机制,其中来自音乐标记的查询只能关注来自歌词标记的键和值。这些层关注歌词编码器最后一层的激活(见图8c)。在图3中,我们看到这些层之一学习到的注意力模式对应于歌词和歌声之间的对齐。
4.3. 解码器预训练
为了减少训练歌词条件模型所需的计算量,我们使用预训练的无条件顶级先验作为解码器,并通过模型手术(Berner等,2019)引入歌词编码器。我们将MLP中的输出投影权重和这些残差块的注意力层权重初始化为零(Zhang等,2019a),以便添加的层在初始化时执行恒等函数。因此,在初始化时,模型的行为与预训练的解码器完全相同,但仍然存在关于编码器状态和参数的梯度2,使模型能够学习使用编码器。
4.4. 采样
在训练完VQ-VAE、上采样器和顶级先验后,我们可以使用它们来采样新歌曲。
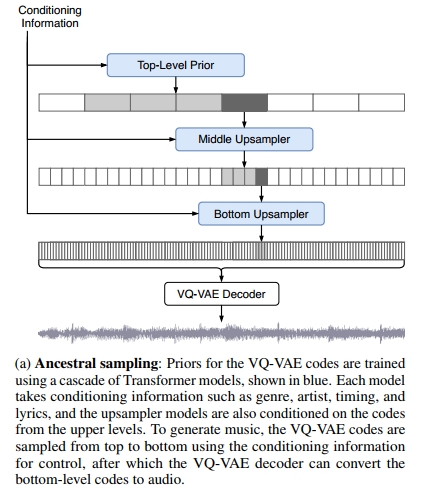
祖先采样:我们首先通过通常的祖先采样过程一次生成一个顶级标记(见图2a):生成第一个标记,然后将所有先前生成的标记作为输入传递给模型,并输出基于所有先前标记的下一个标记。

然后,我们在顶级标记上运行条件WaveNet以生成中级条件信息,并从中进行祖先采样,对底层也执行相同的操作。
窗口采样:为了采样比上下文长度更长的片段,我们使用窗口采样,将采样窗口向前移动一半上下文长度,并继续基于这一半上下文进行采样(见图2b)。我们可以通过在此处使用较小的跳跃长度来在速度和质量之间进行权衡。
预置采样:与其从模型中采样整个标记序列,我们还可以运行VQ-VAE的前向传递以获得与实际歌曲片段对应的顶级、中级和底层标记,如图2c所示。我们可以将这些作为祖先采样过程中的初始标记,并继续从中采样以生成歌曲的新颖完成部分。
5. 实验
5.1. 数据集
我们抓取了一个包含120万首歌曲的新数据集(其中60万首为英文歌曲),并与来自LyricWiki的歌词和元数据配对。元数据包括艺术家、专辑、流派、发行年份以及每首歌曲相关的常见情绪或播放列表关键词。我们使用32位、44.1 kHz的原始音频进行训练,并通过随机下混左右声道生成单声道音频来进行数据增强。
5.2. 训练细节
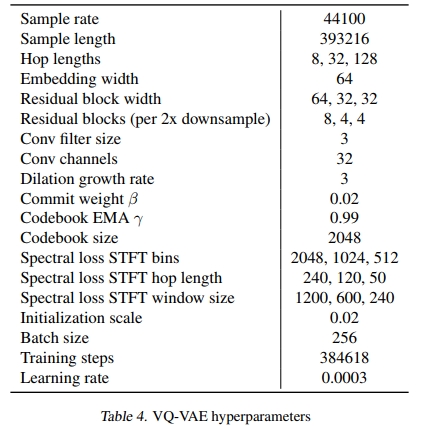
对于音乐VQ-VAE,我们使用了3层瓶颈,分别将44 kHz音频的维度压缩8倍、32倍和128倍,每层的码本大小为2048。VQ-VAE具有200万个参数,并在256个V100 GPU上对9秒音频片段进行了3天的训练。我们使用指数移动平均更新码本,遵循Razavi等(2019)的方法。对于我们的先验和上采样器模型,我们使用8192个VQ-VAE代码标记的上下文,分别对应于顶层、中层和底层约24秒、6秒和1.5秒的原始音频。上采样器具有10亿个参数,并在128个V100 GPU上训练了2周,而顶级先验具有50亿个参数,并在512个V100 GPU上训练了4周。我们使用Adam优化器,学习率为0.00015,权重衰减为0.002。对于歌词条件,我们重用了先验模型并添加了一个小型编码器,之后在512个V100 GPU上训练了2周。我们模型和训练的详细超参数见附录B.3。
5.3. 样本
我们训练了一系列样本质量逐步提高的模型。我们的第一个模型是在MAESTRO数据集上训练的,使用22 kHz的VQ-VAE代码和相对较小的先验模型。我们观察到,该模型可以生成高保真度的古典音乐样本,包含钢琴和偶尔的小提琴。然后,我们收集了一个更大且更多样化的歌曲数据集,包含流派和艺术家标签。当同一模型在这个新数据集上训练时,能够生成除古典音乐之外的多样化样本,并展示出超过一分钟的音乐性和连贯性。
尽管能够生成总体上高保真且连贯的歌曲具有新颖性,但样本质量仍受到一些因素的限制。首先,使用22 kHz采样率和小型上采样器在上采样和解码步骤中引入了噪声,我们听到的是颗粒状的纹理。我们通过在后续实验中使用44 kHz的VQ-VAE和10亿参数的上采样器来提高保真度,但代价是渲染时间更长。
其次,10亿参数的顶级先验不足以生成歌声和多样化的音乐音色。我们首先探索将模型大小增加到50亿参数。更大的容量使得模型能够更好地建模更广泛的歌曲分布,从而生成具有更好音乐性、更长连贯性和初步歌声的样本。尽管整体质量有所提高,但无条件模型仍然难以唱出可识别的单词。通过训练带有歌词条件的序列到序列模型并将数据集限制为主要为英文的歌曲,使得歌声既清晰又可控制。
我们最终将这一模型命名为Jukebox,它集成了所有这些改进。由于每个人对音乐的体验不同,通过平均意见分数或类似FID的指标来评估样本通常既复杂又缺乏意义。我们通过人工评估生成样本的连贯性、音乐性、多样性和新颖性。精选示例的链接已嵌入文本中。
连贯性
我们发现,样本在顶级先验的上下文长度内(约24秒)保持了高度的音乐连贯性,并且在滑动窗口生成长样本时,它们保持了相似的和声和质感。然而,由于顶级先验没有整首歌曲的上下文,我们听不到长期的音乐模式,也不会听到重复的副歌或旋律。
生成的歌曲从开头(例如掌声或缓慢的乐器热身)到类似副歌的部分,再到乐器间奏,最后以淡出或其他方式结束。顶级先验始终知道歌曲在时间上的完成比例,因此它能够模仿适当的开头、中间和结尾。
音乐性
样本经常模仿熟悉的音乐和声,歌词的编排通常非常自然。旋律中的最高音或最长音通常与人类歌手会选择强调的单词相匹配,歌词的呈现方式几乎总能捕捉到短语的韵律。这在嘻哈音乐生成中尤为明显,模型能够可靠地捕捉口语文本的节奏。然而,我们发现生成的旋律通常不如人类创作的旋律有趣。特别是,我们没有听到许多人类旋律中常见的前因后果模式,也很少听到旋律上令人难忘的副歌。
多样性
似然训练鼓励覆盖所有模式,因此我们期望模型能够生成多样化的样本。
-
重新演绎:我们生成了多个样本,这些样本以训练数据中存在的艺术家和歌词组合为条件。虽然偶尔鼓点和贝斯线或旋律间隔会呼应原版,但我们发现生成的样本中没有明显类似于原版歌曲的。
我们还生成了多个以与样本1相同的艺术家和歌词为条件的歌曲,得到样本9-12。这五首歌曲各有特色,具有不同的情绪和旋律,例如样本10在00:14处演奏了一个和声作为蓝调即兴演奏的一部分,这表明模型已经学会了广泛的演唱和演奏风格。补全
我们用现有歌曲的12秒片段作为初始输入,并要求模型以相同的风格补全歌曲。当初始片段包含歌声时,补全部分更有可能模仿原曲的旋律和节奏。而使用更通用或常见的开头作为初始片段时,生成的补全部分往往更加多样化。即使生成的样本在开头部分与原曲接近,大约30秒后也会完全偏离到新的音乐素材中。
重新演绎和补全虽然有趣且多样化,但总体而言,与原始歌曲相比,音乐质量仍有改进空间。完整树
为了更系统地理解多样性,我们从同一片段生成多个补全版本。我们从一个一分钟的样本开始,每一分钟的扩展部分独立采样四次。到三分钟时,共有16个补全版本。我们可以将这个分支树视为通过祖先采样探索不同可能性。在链接中生成的歌曲中,即使使用相同的初始片段,我们也听到了演唱和发展的多样性。我们注意到,这个特定样本在跟随歌词方面比许多其他样本更成功。对于某些流派(如嘻哈和说唱),线性移动窗口无法很好地对齐歌词,因此生成合理演唱的可能性较低。
新颖性
凭借对各种风格、歌词和原始音频的条件生成能力,我们希望Jukebox成为专业音乐人和音乐爱好者的有用工具。在本节中,我们感兴趣的是探索Jukebox的能力和应用。
新颖风格
我们生成了一些与艺术家通常不相关的非典型流派的歌曲。总体而言,我们发现,在使用相同声音的同时推广到新颖的演唱风格相当困难,因为艺术家嵌入会压倒其他信息。在Joe Bonamassa和Frank Sinatra的样本中,我们听到了乐器、能量和氛围的适度变化,这取决于流派嵌入。然而,我们尝试将乡村歌手Alan Jackson与嘻哈和朋克等非典型流派混合时,样本并未以有意义的方式偏离乡村风格。
新颖声音
我们选择了一些模型能够较好地复现其声音的艺术家,并通过插值他们的风格嵌入来合成新的声音。例如,Frank Sinatra和Alan Jackson的混合(样本4)听起来仍然类似于Frank Sinatra。在大多数情况下,模型以一种模糊可识别但独特的声音呈现,保留了不同的声乐特征。以Céline Dion嵌入为条件并除以二的样本1和2,音色和音调略有不同,但捕捉到了她独特的颤音。
我们还尝试在歌曲中途改变风格嵌入以创建二重唱(样本7)。这是在采样期间引导生成的另一种方式。在间奏结束时切换到另一种声音效果最佳;否则,模型会在单词或句子中间混合声音。新颖歌词
我们让Jukebox演唱由GPT-2生成的诗歌和新诗句,以证明它确实可以演唱新歌词。虽然训练数据由词汇有限且结构受限的歌词组成,但模型已经学会跟随大多数提示并演唱即使是新单词(包括深度学习文献中的技术术语)。然而,为了获得最佳效果,我们发现拼写困难单词或首字母缩略词是有用的。如果文本在长度、押韵或节奏质量上与给定艺术家的歌词分布匹配,生成的样本质量会显著提高。例如,嘻哈歌词往往比其他流派更长,常见的重音音节很容易形成清晰的节奏。
新颖即兴演奏
Jukebox的另一个有用应用是能够记录一个不完整的想法并探索各种补全版本,而无需将其转换为符号表示,这可能会丢失音色和情绪的细节。我们整理了内部音乐家的新颖即兴演奏录音,并在采样期间将其作为初始输入。样本6以Elton John歌曲中不常见的音乐风格开始,模型仍然延续了这一曲调并进一步发展。同样,样本1的开头是一个5/4复拍子的前卫爵士乐片段,这在嘻哈音乐中从未使用过。尽管具有这种新颖性,节奏在整个歌曲中持续存在,并与说唱自然结合。
5.4. VQ-VAE消融实验
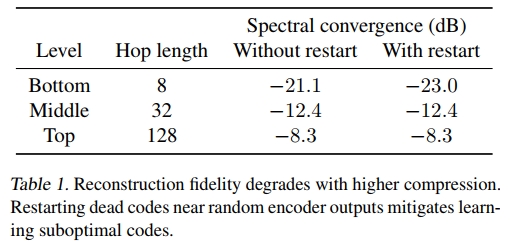
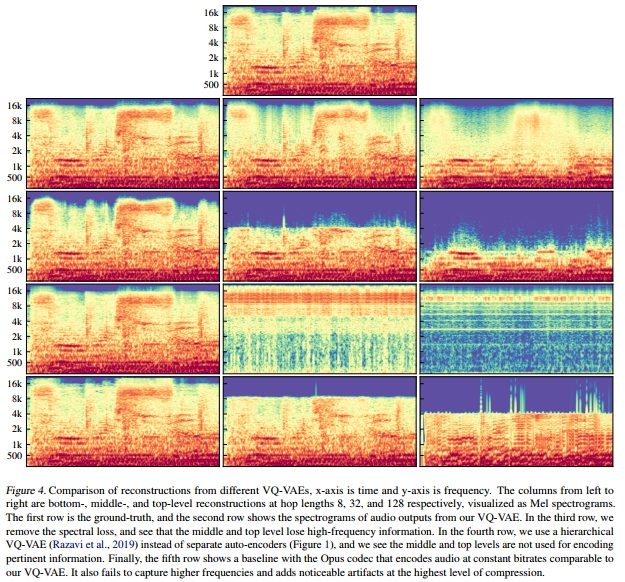

我们比较了在不同压缩比、目标和架构下训练的原始音频VQ-VAE。由于我们使用具有连续表示的非自回归解码器进行输出,因此我们报告了频谱收敛性(Sturmel & Daudet, 2011),它测量了相对于信号的频谱误差量,作为测试误差和重建保真度的代理。我们在5000个保留的3秒音频片段上进行了评估,并以分贝为单位报告平均值。本节中的所有模型均以批量大小为32、44 kHz采样的3秒音频片段进行训练。如前所述,我们分别使用8、32和128的跳跃长度作为底层、中层和顶层的设置。
在表1中,我们看到增加跳跃大小会导致更高的重建误差。图4确实显示,在我们运行的所有消融实验中,中层和顶层缺失了大量信息,尤其是高频部分。这是预期的,因为音频在更大的跳跃大小下被压缩得更多。
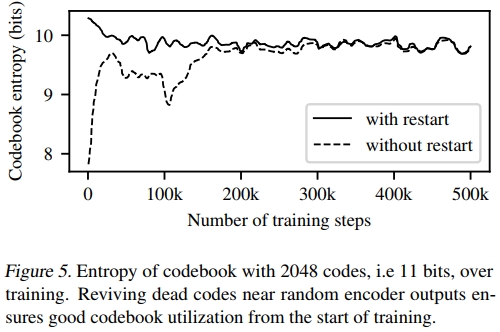
为了缓解码本崩溃问题,我们在随机编码器嵌入附近重新启动失效的码本。在图5中,我们看到这从训练早期就产生了更高的码本使用率。没有随机重启训练的模型可以收敛到相同的测试误差和码本使用率,但需要更多的训练步骤。在初始化不佳的情况下,这些模型有时会以次优的码本结束,从而损害重建保真度。
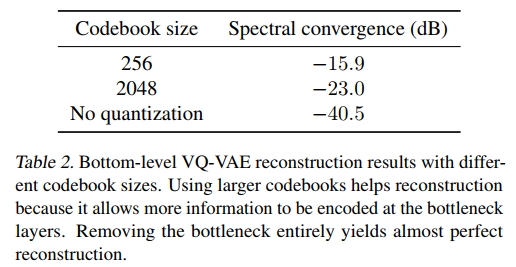
码本大小也很重要,因为它通过瓶颈层设定了通道容量的上限。在表2中,我们发现当码本大小从2048减少到256时,重建误差显著增加。我们还与一个使用连续表示而不进行矢量量化的模型进行了比较。我们可以将这个模型视为使用了一个包含所有编码器嵌入的极大码本。该模型实现了几乎完美的重建,频谱误差可以忽略不计。
当模型仅使用L2损失进行训练时,重建结果往往因缺失高频而听起来浑浊,随着跳跃大小的增加,这一问题更加严重。在图4中,我们看到没有频谱损失的顶层码本在2 kHz以上的信息捕捉较少,重建效果较差(表3)。然而,我们观察到,虽然频谱损失有助于编码更多信息,但它也会添加失真伪影,我们听到的是刺耳的噪声。
最后,我们训练了一个原始音频分层VQ-VAE(Razavi等,2019),发现通常很难将信息推送到更高层级。该模型的训练时间是之前模型的两倍,但如图4所示,中层和顶层的重建效果并未捕捉到太多信息。可能在底层开始良好重建音频之前,更高层级的码本已经崩溃。使底层显式建模残差将更多信息推送到顶层。但我们发现,单独的自编码器更干净且更有效。
6. 相关工作
深度学习中的生成模型:生成模型旨在通过学习数据的分布来生成新数据,可以通过显式建模分布或隐式构建采样方法来实现(Goodfellow, 2016)。传统上,建模高维数据中的相互依赖性被认为极其困难,但从深度玻尔兹曼机(Salakhutdinov & Hinton, 2009)开始,各种深度生成模型被引入。生成对抗网络(GANs)(Goodfellow等,2014)使用生成器和判别器网络相互竞争,使生成的样本尽可能与真实数据无法区分,并以其生成高质量图像的能力而闻名(Zhang等,2019b;Brock等,2019)。自回归生成模型如NADE(Uria等,2016)、PixelCNN(Van den Oord等,2016)和Transformer(Vaswani等,2017)使用概率链规则将数据的联合分布分解为更简单分布的乘积,而基于流的模型(Dinh等,2015;2017;Rezende & Mohamed, 2015;Kingma & Dhariwal, 2018)学习一系列可逆变换,将数据分布映射到更简单的分布(如高斯分布)。自回归流(Papamakarios等,2017;Kingma等,2016)结合了这两种思想,以实现更快的密度估计或数据生成。变分自编码器(VAEs)(Rezende等,2014;Kingma & Welling, 2014)在编码器-解码器设置中对潜在代码施加高斯先验,从而可以从中学到数据分布。
音乐的生成模型:符号音乐的生成建模可以追溯到半个多世纪前,Hiller Jr & Isaacson(1957)提出了基于马尔可夫链的第一首计算机生成音乐。早期的多种方法包括基于规则的系统(Moorer, 1972)、混沌和自相似性(Pressing, 1988)、细胞自动机(Beyls, 1989)、拼接合成(Jehan, 2005)和约束编程(Anders & Miranda, 2011)。最近的数据驱动方法包括DeepBach(Hadjeres等,2017)和Coconet(Huang等,2017),它们使用吉布斯采样生成巴赫风格的音符;MidiNet(Yang等,2017)和MuseGAN(Dong等,2018)使用生成对抗网络;MusicVAE(Roberts等,2018)和HRNN(Wu等,2019)使用分层递归网络;Music Transformer(Huang等,2019a)和MuseNet(Payne, 2019)使用Transformer自回归预测MIDI音符事件。还有一些方法基于符号音乐信息合成音乐,例如NSynth(Engel等,2017)使用WaveNet风格的自编码器,Mel2Mel(Kim等,2019)和Wave2Midi2Wave(Hawthorne等,2019)使用WaveNet基于钢琴卷表示合成音乐,GanSynth(Engel等,2019)使用生成对抗网络生成幅度谱图和瞬时频率以简化谱图反演。音乐生成模型还可用于音乐风格迁移,例如Midi-VAE(Brunner等,2018)使用变分自编码器在古典和爵士音乐之间迁移风格,LakhNES(Donahue等,2019)使用Transformer架构生成芯片音乐,Universal Music Translator Network(Mor等,2019)使用去噪自编码器分离音乐风格和内容。
音频的样本级生成:近年来,多种原始音频生成模型被提出。WaveNet(Oord等,2016)使用一系列扩张卷积对原始波形进行逐样本自回归概率建模,以指数级增加上下文长度。它可以无条件生成逼真的音频,也可以通过声学特征或频谱图进行条件生成。WaveNet的自回归特性使其采样速度极慢,并且它对音频样本使用分类分布,引入了量化噪声。Parallel WaveNet(Oord等,2018)通过使用逻辑斯谛混合分布(一种连续概率分布)并执行概率密度蒸馏来改进这一点,蒸馏过程从预训练的自回归模型中学到一个并行前馈网络,从而允许更快地采样高保真音频。ClariNet(Ping等,2019)使用简单的高斯分布实现了类似的音频质量,从而具有闭式损失函数,消除了蒙特卡罗采样的需求。SampleRNN(Mehri等,2017)使用多尺度分层递归神经网络与卷积上采样来建模长程复杂结构。WaveRNN(Kalchbrenner等,2018)使用递归神经网络分别处理最高有效字节和最低有效字节,可以在移动设备上高效部署,同时具有与WaveNet相当的音频质量。WaveGlow(Prenger等,2019)是一种基于流的并行样本级音频合成模型,可以通过简单的最大似然估计进行训练,因此比蒸馏所需的两阶段训练过程更具优势。Parallel WaveGAN(Yamamoto等,2020)和MelGAN(Kumar等,2019)是基于GAN的方法,直接建模音频波形,以显著更少的参数实现了与WaveNet和WaveGlow模型相当的质量。虽然上述方法作为复杂的原始音频生成模型,可以基于紧凑且可控的音频表示(如梅尔频谱图)进行条件生成,但MelNet(Vasquez & Lewis, 2019)采取了不同的方法,分层生成高分辨率梅尔频谱图,之后通过简单的基于梯度的优化可以生成高保真音频。
VQ-VAE:Oord等(2017)提出了VQ-VAE,这是一种通过矢量量化将极长上下文输入下采样为较短离散潜在编码的方法,并展示了它可以生成高质量的图像和音频,同时学习无监督的音素表示。Razavi等(2019)通过引入图像的离散表示层次扩展了上述模型,并展示了生成的模型可以将高级语义分离到具有最大感受野的最高层离散代码中,同时在较低层捕捉局部特征(如纹理)。他们使用分层模型为条件ImageNet和FFHQ数据集生成高多样性和高保真图像。Dieleman等(2018)尝试了该方法的变体,其中多个连续编码器进一步压缩来自上一级的有损离散编码。这种方法的缺点是每一步都会丢失信息,并且需要为每个VQ-VAE级别单独训练,导致层次崩溃问题。De Fauw等(2019)使用了已知会导致忽略潜在变量问题的AR解码器,并提出了缓解方法。(Razavi等,2019)中的前馈解码器不存在此问题,因此我们采用了他们的方法。
语音合成:生成自然的人类语音需要理解语言特征、声音映射和表达的可控性。许多文本到语音(TTS)系统依赖于高度工程化的特征(Klatt, 1980)、精心策划的声音片段(Hunt & Black, 1996)、统计参数建模(Zen等,2009)以及通常复杂的流水线(如Arık等,2017所述)。这些方法相当复杂,生成的语音往往不自然或含糊不清。最近的工作如Deep Voice 3(Ping等,2018)、Tacotron 2(Shen等,2018)和Char2Wav(Sotelo等,2017)使用序列到序列架构(Sutskever等,2014)端到端学习语音合成。设计空间广阔,但典型方法通常包括双向编码器、解码器和声码器,以构建文本表示、音频特征和最终的原始波形。为了生成多种语音,文本到语音模型还可以基于说话者身份(Oord等,2016;Gibiansky等,2017;Jia等,2018)以及文本提示进行条件生成。通过学习和操作辅助嵌入,模型可以在测试时模仿新语音(Arık等,2018a;Taigman等,2018)。然而,这些方法需要标注数据。聚类(Dehak等,2011)、启动(Wang等,2018)和变分自编码器(Hsu等,2019;Akuzawa等,2018)等思想已被用于以无监督方式学习更广泛的语音风格并控制表达性。还有一些工作通过额外控制音高和音色来合成歌唱。与TTS文献类似,早期工作使用拼接方法(Bonada & Serra, 2007)连接精心策划的短歌唱片段,以及统计参数方法(Saino等,2006;Oura等,2010),允许从训练数据中建模音色。这两种方法都施加了相当强的假设,导致明显的伪影。(Blaauw & Bonada, 2017)训练了一个带有参数声码器的神经TTS模型,以分离音高和音色,从而在生成时进行控制。
7. 未来工作
虽然我们的方法在生成连贯的长原始音频音乐样本方面迈出了一步,但我们认识到未来工作的几个方向。优秀的音乐生成应该在所有时间尺度上都具有高质量:它应该在整首作品中具有发展的音乐和情感结构,局部音符和和声始终合理,细腻且适当的微小音色和纹理细节,以及平衡和混合多个声部的音频录制质量,且没有不必要的噪声。我们认为当前模型在中时间尺度上表现较强:模型生成的样本在局部听起来通常非常好,具有有趣且多样化的和声、节奏、乐器和声音。我们经常对生成的旋律和节奏与特定歌词的契合度感到非常印象深刻。然而,虽然样本在较长时间尺度上保持一致,但我们注意到它们缺乏传统的更大音乐结构(如重复的副歌或具有问答形式的旋律)。此外,在最小尺度上,我们有时会听到音频噪声或刺耳声。
除了样本质量外,我们还希望多样化模型能够生成的语言和风格。我们当前的模型仅在检测到主要语言为英语的歌曲上进行了训练(Sites, 2013)。未来,我们希望包括其他语言和艺术家。我们认为这不仅对生成严格符合这些风格的音乐感兴趣,而且因为历史上我们看到许多创造力和发展来自于现有音乐风格的非常规融合。最后,我们认为计算机音乐生成作为人类音乐家的工具非常重要,尤其是对那些对音乐感兴趣但没有正式训练的人。虽然我们能够通过歌词和MIDI条件在一定程度上引导当前模型,但我们可以想象许多其他可能的方式让人类影响生成过程,包括指示各部分的情态或动态,或控制鼓、歌手或其他乐器的演奏时间。
当前模型生成1分钟的顶级标记大约需要1小时。上采样过程非常缓慢,因为它是逐样本顺序进行的。目前,上采样1分钟的顶级标记大约需要8小时。我们可以在顶级层面创建一个“人在回路”的协同作曲过程,使用VQ-VAE解码器快速上采样顶级标记,以听到模型生成的非常粗糙的效果。顶级模型生成多个样本,用户选择最喜欢的样本(通过粗糙的VQ-VAE解码听取),然后模型继续生成多个样本以延续用户的选择。如果生成和Transformer上采样步骤更快,这一过程将得到显著改进。我们的模型具有快速的并行似然评估能力,但自回归采样速度较慢。我们可以改用具有快速并行采样但自回归似然评估较慢的模型(Kingma等,2016),并将当前模型的信息蒸馏到其中(Oord等,2018)。蒸馏过程通过从并行采样器生成样本并使用并行似然评估器评估其似然和熵,然后通过最小化其与当前模型的KL散度来优化采样器。
8. 结论
我们介绍了Jukebox,这是一个能够生成模仿多种风格和艺术家的原始音频音乐的模型。我们可以根据特定的艺术家和流派对音乐进行条件生成,并可以选择为样本指定歌词。我们详细介绍了训练分层VQ-VAE以有效将音乐压缩为标记的必要细节。虽然之前的工作生成了20-30秒范围内的原始音频音乐,但我们的模型能够生成长达数分钟的作品,并且具有自然声音的可识别歌唱。
A. 可扩展的Transformer
我们通过对Sparse Transformer(Child等,2019)进行一些小的改动,使其更具可扩展性且更易于实现。我们实现了一种更简单的注意力模式,其性能相同,但无需自定义内核来实现。我们通过在整个模型中使用相同的初始化规模简化了初始化过程,而无需根据输入规模和深度重新调整权重,并通过全半精度训练优化了内存占用,即模型权重、梯度和优化器状态均以半精度存储,并以半精度进行计算。为了应对fp16格式较窄的动态范围,我们使用梯度和Adam优化器状态的动态缩放。
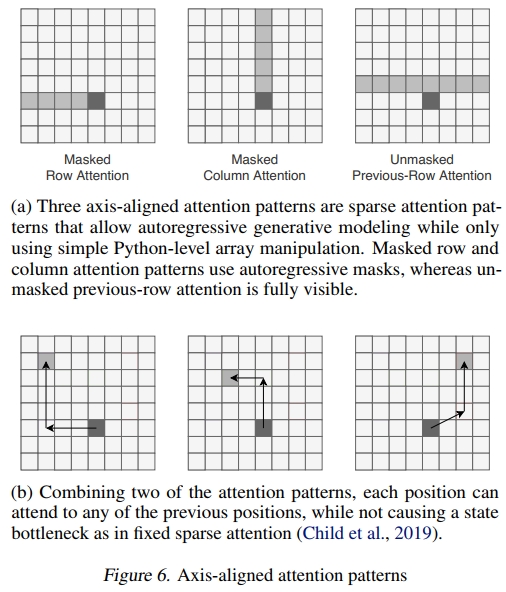
轴对齐的注意力模式:Sparse Transformer(Child等,2019)通过将输入序列重塑为形状为(块数,块长度)的2-D序列来稀疏化注意力模式,从而使用分解注意力。他们观察到,跨步注意力模式在图像和音频上效果最佳,因为它没有固定注意力的状态瓶颈。然而,他们的实现需要专门的CUDA内核。我们可以通过掩码行、掩码列和未掩码的前一行注意力来实现类似的模式。掩码行捕捉局部上下文,而掩码列和未掩码的前一行注意力捕捉所有前一行的上下文。我们观察到这种模式在计算速度和训练损失方面表现相同。这些模式中的每一个都可以通过沿适当轴转置或切片输入序列直接实现为密集注意力,因此不需要特殊的CUDA内核来实现。这也可以轻松扩展到视频领域。与我们的工作互补的是,(Ho等,2019)中引入了一种类似的模式,他们也使用了轴对齐注意力,但采用了双流架构。
半精度参数和动态缩放的优化器状态:为了训练大型模型,(Child等,2019)使用梯度检查点重新计算,使用半精度激活和梯度进行计算,并使用动态损失缩放。虽然这加快了在Volta核心上的训练速度,但由于以全浮点精度存储参数和Adam状态,内存使用量仍然很高。为了进一步扩展我们的模型,我们将矩阵乘法参数及其Adam状态以半精度存储,从而将内存使用量减半。我们使用单个参数s来设置所有权重的规模,并将所有矩阵乘法和输入/输出嵌入3初始化为N(0; s),位置嵌入初始化为N(0; 2s)。
初始化确保所有参数处于相似的动态范围内,并允许我们完全以半精度进行训练而不会损失训练性能。对于Adam状态张量(m_t, v_t),我们进行动态缩放。对于每次迭代和每个参数,我们在转换之前重新缩放其状态张量,使其最大值对应于float16范围的最大值,从而最大化float16范围的使用。因此,我们将状态m_t存储为元组(scale, (m_t/scale).half()),其中scale = m_t.max()/float16.max(),v_t同理。上述方法使我们能够将大小为1B参数的模型适应到8192个标记的大上下文中。为了训练更大的模型,我们使用GPipe(Huang等,2019b)。
B. 实验细节
B.1. 音乐VQ-VAE
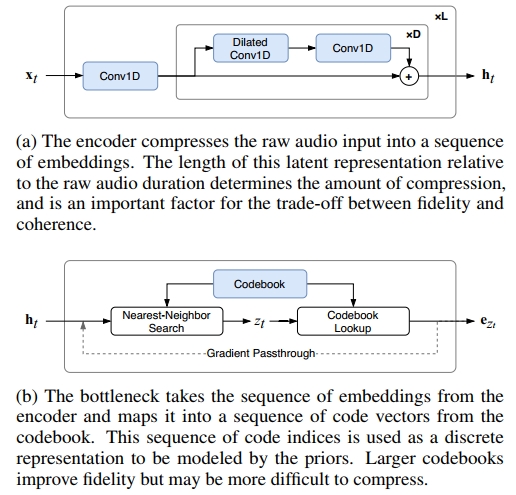
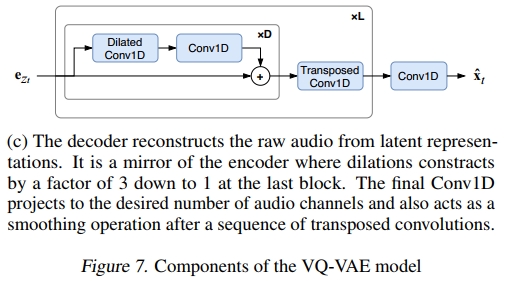
我们使用了三个独立的原始音频VQ-VAE,分别为底层、中层和顶层先验生成不同跳跃大小的离散代码。所有自编码器均包含非因果的扩张1-D卷积,并使用非自回归重建损失独立训练。这些网络中的基本构建块共享相同的架构,如图7所示。每个编码器块由一个下采样卷积、一个残差网络和一个核大小为3的1D卷积组成。这些残差网络中的扩张因子为3,以增加感受野。解码器块通过核大小为3的1D卷积、扩张随深度收缩的残差网络和上采样转置卷积来镜像这一结构。这里,所有重采样卷积使用核大小为4和步幅为2的卷积,因此每个构建块将跳跃长度改变2倍。为了在时间上获得更高的压缩率,我们只需堆叠更多这样的块。例如,使用七个块可以为顶层自编码器生成跳跃长度为128的代码。
每个残差网络在中层和顶层VQ-VAE中有四个残差块,分别对应120毫秒和480毫秒的感受野。由于增加残差深度有助于略微提高重建质量,我们将底层的残差块数量增加了一倍。这将每个代码的感受野显著增加到约2秒,但实际的感受野主要是局部的。
我们还尝试使用单一解码器并建模残差以分离学习到的表示(如Razavi等,2019),希望上采样先验能够简单地填补局部音乐结构。然而,将信息推送到顶层非常具有挑战性,因为最底层在训练早期几乎完美地重建了音频。当我们添加辅助目标以鼓励更多地使用顶层时,顶层代码会对最终输出产生严重的失真。(Dieleman等,2018)中也展示了类似的挑战。
B.2. 音乐先验和上采样器
我们的音乐先验和上采样器模型的架构细节如图8所示。它们对每个级别的标记进行自回归建模,并以艺术家和流派等信息为条件,在上采样器的情况下还以来自上层的标记为条件(图8a)。每个艺术家和流派都作为嵌入向量学习,其和在每个序列中作为第一个标记提供。此外,位置嵌入作为歌曲持续时间内每个位置的绝对和相对时间的函数进行学习。在上采样器模型中,上层标记通过条件网络进行上采样,使用WaveNet风格的扩张卷积,然后是一个转置1-D卷积层(图8b)。
当模型在歌词上训练时,顶层先验使用与每个音频片段对应的歌词数据,并训练一个编码器-解码器Transformer,如图8c所示。所有Transformer堆栈使用稀疏自注意力层,重复三种分解注意力类型(行、列和前一行),当存在时,编码器-解码器注意力层与其他注意力类型交错。每层由注意力和MLP前馈网络的残差连接组成,每个连接前都有层归一化(见图8d)。
B.3. 超参数
对于所有Transformer的残差块,我们使用与模型宽度相同的MLP块,以及查询、键和值宽度为模型宽度0.25倍的注意力块。对于所有卷积残差块,我们使用与模型宽度相同通道数的卷积。
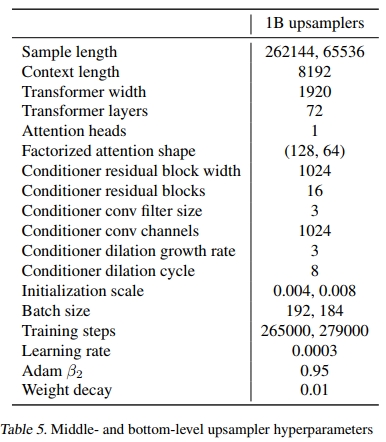
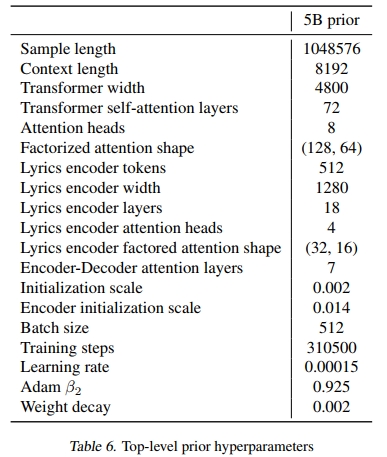
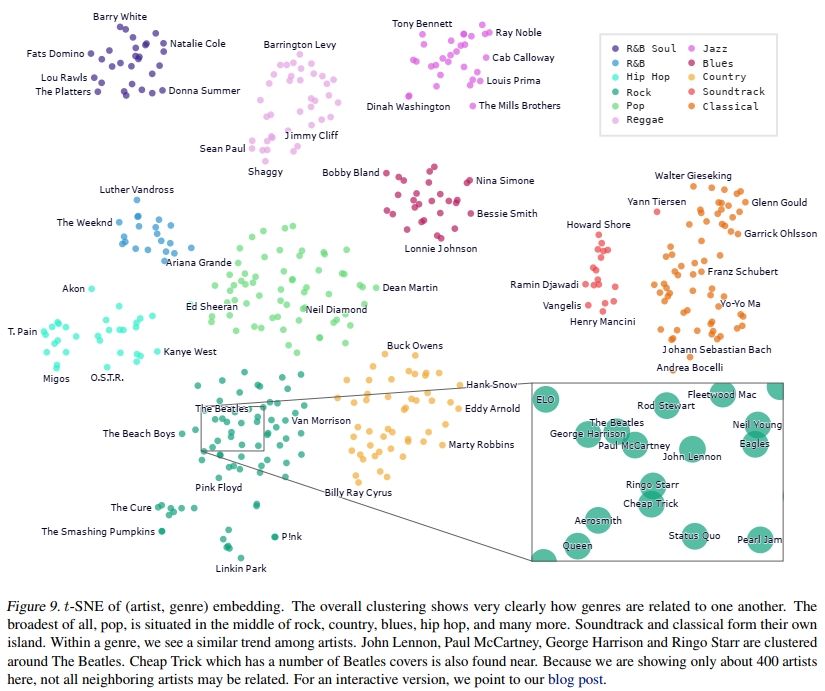
B.4. 艺术家的t-SNE图


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











