






- 缺点:
只是简单的根据 特征数据 预测 变量值。
没有实现滚动预测(用前几天的股价数据预测未来几天的股价)。
存在过拟合的问题。
- 部分数据如下,全部数据已上传(【免费】sh.600000.csv股票数据集资源-CSDN文库)
| code | date | open | low | close | high |
| sh.600000 | 2000/6/1 | 23.5 | 23.36 | 23.44 | 23.68 |
| sh.600000 | 2000/6/2 | 23.5 | 23.4 | 23.7 | 23.97 |
| sh.600000 | 2000/6/5 | 23.8 | 23.59 | 23.65 | 23.97 |
- 完整代码:(有更好的序列预测模型,建议搜一下Github,例如:tsmixer)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import preprocessing
#导入必要的库
#读取数据
df1=pd.read_csv('sh.600000.csv').iloc[:,2:]
df1.tail()
#进行数据归一化
min_max_scaler = preprocessing.MinMaxScaler()
df0=min_max_scaler.fit_transform(df1)
df = pd.DataFrame(df0, columns=df1.columns)
X=df.iloc[:,:-1]
y=df.iloc[:,-1]
print(X.shape)
print(y.shape)
#构造训练集测试集
y=pd.DataFrame(y.values,columns=['target'])
x=X
input_size=len(x.iloc[1,:])
cut=len(y)//10
X_train, X_test=x.iloc[:-cut],x.iloc[-cut:]#列表的切片操作
y_train, y_test=y.iloc[:-cut],y.iloc[-cut:]
X_train,X_test,y_train,y_test=X_train.values,X_test.values,y_train.values,y_test.values
x.iloc[:-cut]
print(X_train.size)#通过输出训练集测试集的大小来判断数据格式正确。
print(X_test.size)
print(y_train.size)
print(y_test.size)
#建立bp模型 训练
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.optimizers import Adam
import time
model = Sequential() #层次模型
model.add(Dense(16,input_dim=input_size)) #输入层,Dense表示BP层
model.add(Activation('relu')) #添加激活函数
model.add(Dense(4)) #中间层
model.add(Activation('relu')) #添加激活函数
model.add(Dense(1)) #输出层
model.compile(loss='mean_squared_error', optimizer='Adam') #编译模型
use_time = time.time()
model.fit(X_train, y_train,epochs=1000, batch_size=256, verbose=0) #训练模型nb_epoch=50次
use_time = time.time()-use_time
print(f'BP train time:{use_time:.5f}s')
#在训练集上的拟合结果
y_train_predict=model.predict(X_train)
y_train_predict=y_train_predict[:,0]
y_train_predict.shape
plt.figure(dpi=150)
plt.plot(y_train.flatten(), label='y_train')
plt.plot(y_train_predict.flatten(), label='y_predict')
plt.legend()
plt.show()
draw=pd.concat([pd.DataFrame(y_train),pd.DataFrame(y_train_predict)],axis=1)
draw.iloc[100:150,0].plot(figsize=(12,6))
draw.iloc[100:150,1].plot(figsize=(12,6))
plt.legend(('real', 'predict'),fontsize='15')
plt.title("Train Data",fontsize='30') #添加标题
#在测试集上的预测
y_test_predict=model.predict(X_test)
y_test_predict=y_test_predict[:,0]
draw=pd.concat([pd.DataFrame(y_test),pd.DataFrame(y_test_predict)],axis=1);
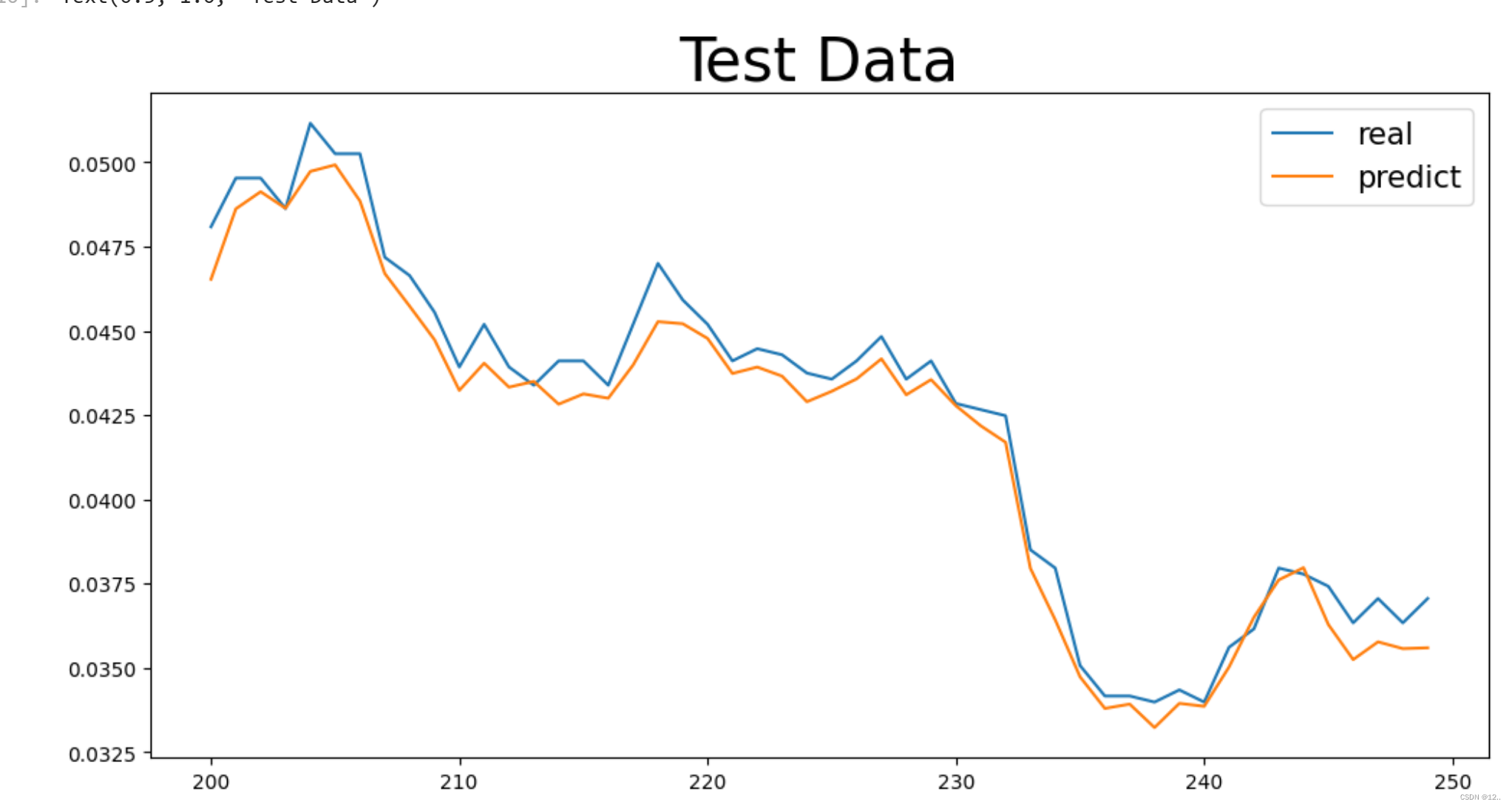
draw.iloc[200:250,0].plot(figsize=(12,6))
draw.iloc[200:250,1].plot(figsize=(12,6))
plt.legend(('real', 'predict'),loc='upper right',fontsize='15')
plt.title("Test Data",fontsize='30') #添加标题
#输出结果
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
import math
def mape(y_true, y_pred):
return np.mean(np.abs((y_pred - y_true) / y_true)) * 100
print('训练集上的MAE/MSE/MAPE')
print(mean_absolute_error(y_train_predict, y_train))
print(mean_squared_error(y_train_predict, y_train) )
print(mape(y_train_predict, y_train[:,0]) )
print('测试集上的MAE/MSE/MAPE')
print(mean_absolute_error(y_test_predict, y_test))
print(mean_squared_error(y_test_predict, y_test) )
print(mape(y_test_predict, y_test[:,0]) )
y_var_test=y_test[1:]-y_test[:len(y_test)-1]
y_var_predict=y_test_predict[1:]-y_test_predict[:len(y_test_predict)-1]
txt=np.zeros(len(y_var_test))
for i in range(len(y_var_test-1)):
txt[i]=np.sign(y_var_test[i])==np.sign(y_var_predict[i])
result=sum(txt)/len(txt)
print('预测涨跌正确:',result)
print('训练时间(秒):',15.25)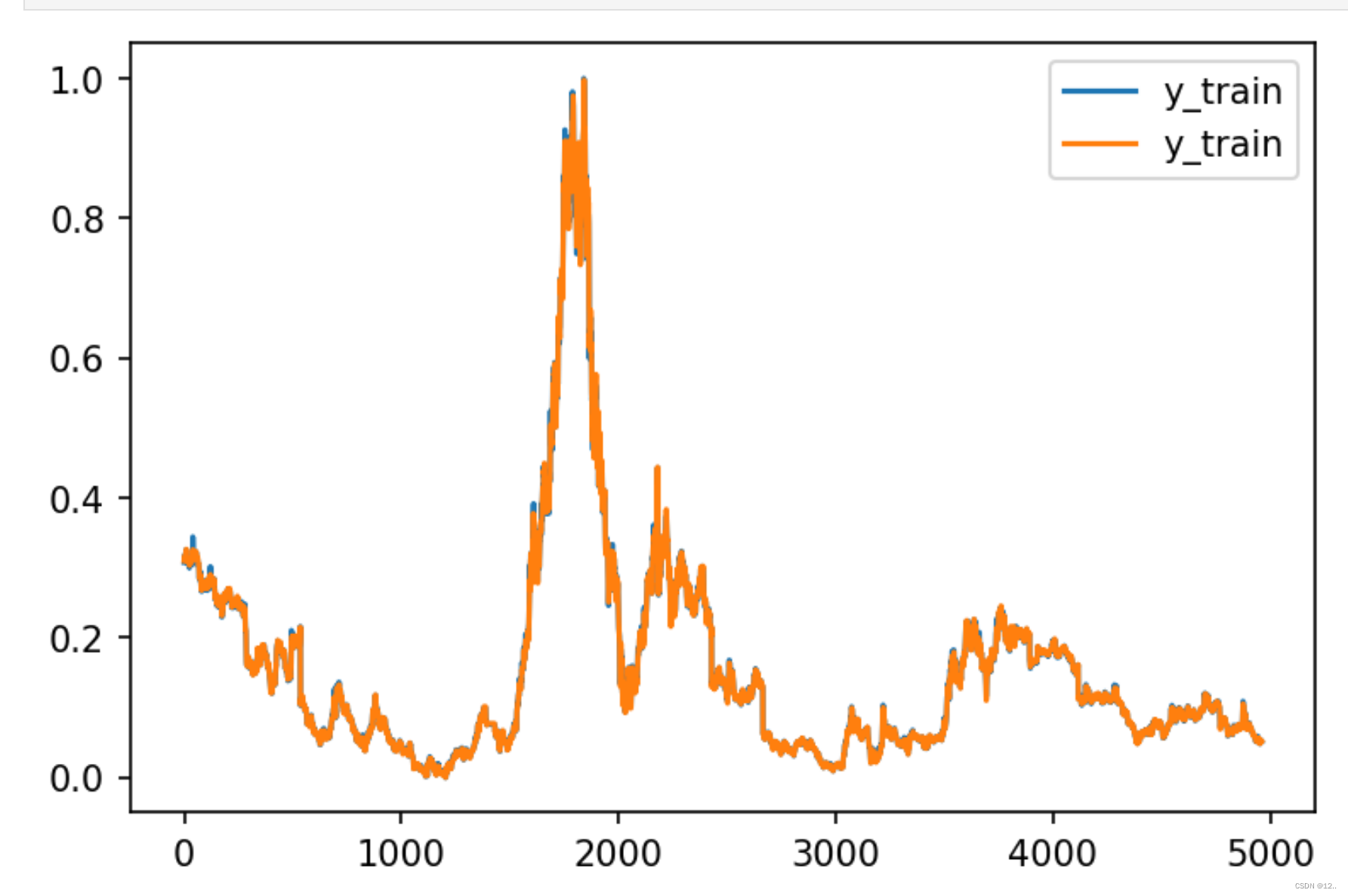
















 903
903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











