







摘要
问题生成在教育环境中有很多应用。在审查内容和测试本身时,问题生成可以证明对学生有帮助。此外,问题生成模型可以通过减轻创建评估和其他实践材料的负担来帮助教师。本文旨在通过变压器模型和提示工程从文本数据生成问题的最佳方法。
在这项研究中,我们在 SQuAD 问答数据集上微调了一个预训练的 distilBERT 模型来生成问题。除了训练 Transformer 模型外,还应用了提示工程来有效地使用 Meta 的 LLAMa 模型生成问题。将生成的问题与 SQuAD 数据集中的基线问题进行比较,以评估四种不同的提示的有效性。所有四个提示平均表现出超过 60% 的相似性。在提示生成的问题中,30% 的相似度得分大于 70%
介绍
问题生成是一项必不可少的 NLP 任务。其主要应用之一是它可以用作学习工具。
主动召回是通过回答问题来检索信息的做法。
根据心理科学协会 (APS),主动回忆是一种高效用学习技术,因为学习者在主动回忆研究后表现出更高的学术表现 [DRM+13]。可以生成问题的模型将帮助学生使用主动召回来审查材料并减少创建问题所需的时间。
根据 CBE 生命科学教育的研究,使用主动学习策略的学生得分分别比没有在考试 1 和 2 上使用主动学习策略的学生高 5.5% 和 10.2% [WSRF21]。问题生成系统还可以激励学生参与教育活动,因为学习者会知道他们将在材料上进行测试 [Hei11]。在线课程和材料需要很多问题,因此该模型将降低问题生成成本 [PLCK19]。此外,它将允许学生测试他们对不包括指导问题的材料的知识。另一方面,问题生成对于教师也很有价值,因为它允许教育工作者将原来制定问题的时间花费在别处。评估需要恒定流量的新问题,因为问题的值在多次使用后下降,因为考生可能会分享它们。
问题生成是一项生成任务,涉及使用语言数据进行监督学习。该任务涉及获取输入数据(上下文和答案的自然语言文本)并将其转换为输出数据,即问题。我们测试了两个模型:变压器模型distilBERT 和 Meta 的 LLAMA 大型语言模型 (LLM),通过提示工程。我们使用 F1 分数和使用 spaCy 向量相似度的 LLAMA 评估变压器模型
背景
在过去的几年里,问题生成的任务发展迅速。Ali 和 Chali 使用 TREC 2007 问答轨道训练他们的模型。该数据集在目标下有一系列事实、列表和其他问题[ACH10]。他们将复杂的句子简化为具有句法解析的基本结构。但是,它们无法处理语义信息的词义消歧。袁和王实现了一个循环模型,使用 SQuAD 1arXiv:2310.18867v1 [cs.CL] 29 Oct 2023 数据集 [YWG+17]。在他们的实现中,编码器处理答案和文档,而解码器生成问题。他们面临类似实体的挑战,交换相关动词,他们的模型需要常识。同样,Duan 和 Tang 使用卷积神经网络 (CNN) 和循环神经网络 (RNN) [DTCZ17]。Chen 和 Wu 最近实现了一个基于强化学习的 Graph2Sequence 模型 [CWZ19]。
大多数先前的工作通常会产生低质量的问题。我们建议使用具有提示工程的大型语言模型 (LLM) 来应对这些挑战。先前的论文没有解决基于提示工程的问题生成任务方法。此外,由于 LLM 已经在大量数据上进行了训练,因此它们具有先前模型缺乏的常识知识。
数据集
在本文中,Stanford 的 SQuAD 数据集用于生成问题。[RZLL16],[RJL18]。变压器模型在 SQuAD 数据集上进行评估和训练。
由于 SQuAD 版本 2 数据集具有无法回答的问题,我们使用了 SQuAD 1.1 数据集 [G+22]。对于问题生成任务,无法回答的问题不会很有用,因为我们想生成问题来测试阅读理解。该数据集包含来自 500 篇文章的 100,000 个问题。虽然该数据集通常用于回答问题,但我们将其反转以进行问题生成。SQuAD 数据集在训练集中(8759 个样本)和验证集(10570 个样本)之间拆分了大约 90/10。
对于数据预处理,输入被标记化。长上下文被拆分;然而,如果答案是上下文被拆分的位置、超参数、文档步幅允许拆分上下文的两个部分之间的重叠。我们还使用 SQuAD 数据集进行提示工程。我们将 SQuAD 问题与 LLAMA 的提示生成问题进行了比较,以评估生成的问题的质量。
4 方法/模型
4.1 Transformer DistilBert
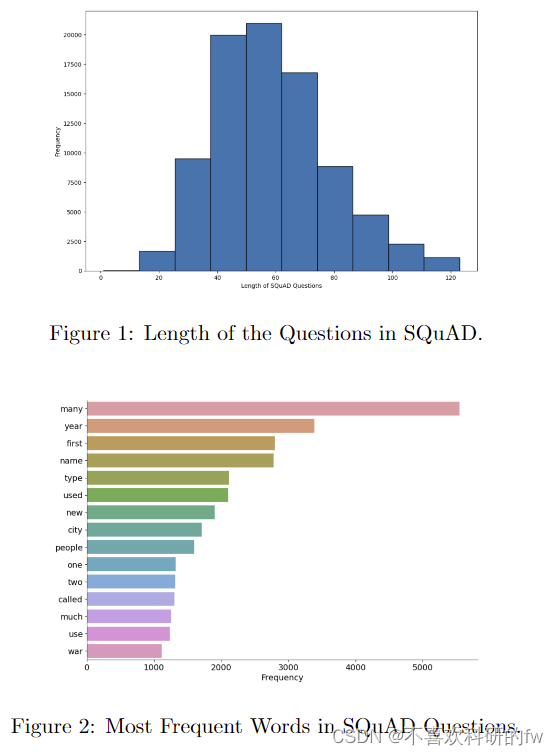
Transformers 是深度学习模型,它由一个独特的架构组成,该架构保留了句子中所有单词之间的关系。Transformers 没有使用循环神经网络 (RNN) 实现,仅使用注意力机制 [VSP+17]。它们由一个编码器和一个解码器组成。编码器从输入中提取特征,解码器使用特征为任务生成预测。BERT(来自 Transformers 的双向编码器表示)是深度神经网络中广泛使用的预训练语言模型 [DCLT18]。图 3 说明了 DistilBERT 模型架构,这是 BERT 模型的较小版本。
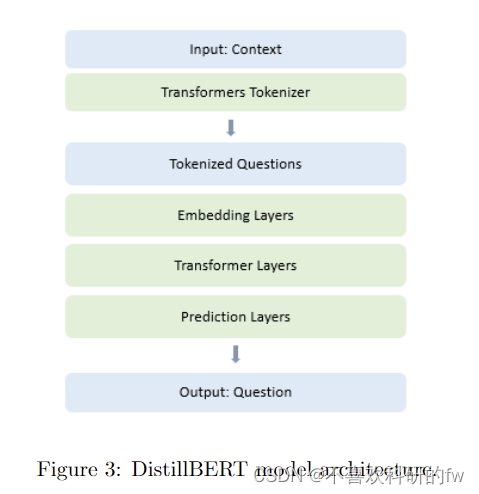
DistilBERT 是 BERT 的蒸馏版本,超参数比 BERT-baseuncased [SDCW19] 少 40%。我们在 SQuAD 数据集上微调 DistilBERT 模型以生成问题。首先,SQuAD 数据集颠倒,即我们将数据集转换为 Pandas Dataframe,并交换“问题”和“答案”列。
微调预训练模型的参数包括学习率。00005,权重衰减0.01,训练周期设置为3。图4显示了DistilBERT问题生成任务的过程。
4.2 提示工程
提示工程是为LLM制定特定提示以生成所需输出的做法。Andrew Ng 和 Isa Fulford 概述了提示工程的两个主要原则:编写清晰和具体的指令并允许模型思考 [NF]。我们使用 Meta 的 LLAMA 模型 [TLI+23] 的这些指南为问题生成任务开发了四个提示。温度,提示的可变性,设置为 0.5,以确保不同的响应。每个提示都会产生五个问题。表 1 显示了四个提示。

我们从 SQuAD 数据集中随机选择了 50 个上下文的样本。我们根据 SQuAD 的每个上下文下的基线问题评估了四种不同的提示。对于每个提示,生成 250 个问题。我们使用使用词嵌入来衡量生成的问题和基线问题之间的句子相似性的 spaCy 度量。我们记录了每个生成的问题的最大相似度分数以及每个上下文中每个提示类型的最大相似度分数。图 5 显示了提示工程的过程以及如何评估提示。
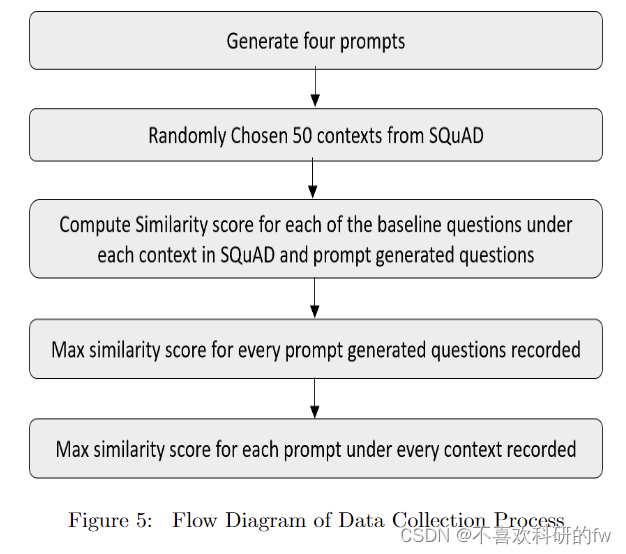
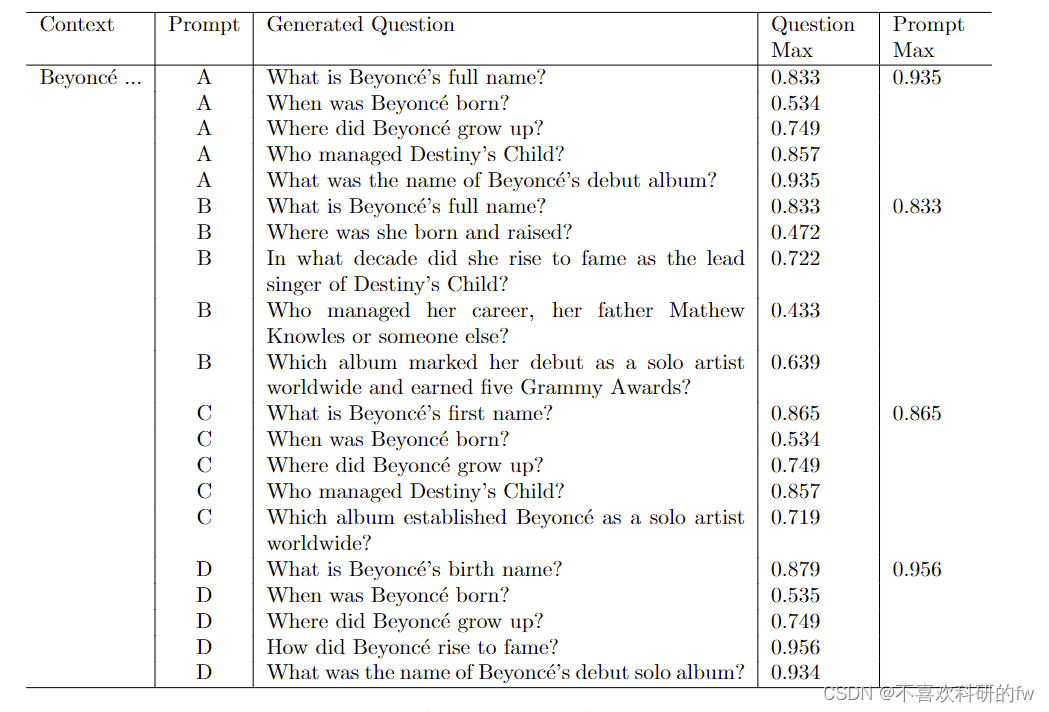
表 2 是上下文数据收集样本:“Beyonc ́e Giselle Knowles-Carter(出生 9 月 4 日,1981 年)是美国歌手、歌曲作者、记录制作人和女演员。在德克萨斯州休斯顿的 Born 和提出,她在各种歌唱和舞蹈比赛中作为孩子表演,并在 1990 年代后期上升到名声,作为 R&B 女孩组 Destiny ́s Child 的领先歌手。由她的父亲 Mathew Knowles 管理,该小组当时成为世界最佳销售女孩组之一。他们的 hiatus 在 Love (2003) 中看到了 Beyonc ́e ́s debut Al专辑 Dangery 的释放,它确立了她作为全球独奏艺术家,获得了五个 Grammy 奖,并以 Billboard Hot 100 个数字一单“爱中的疯狂”和“Babby Boy”为特色。”
显示了四个提示生成的问题。“Prompt Max”是特定提示下所有生成问题的最大相似度分数。
5 结果和讨论
5.1 transformer
使用 PyTorch 的 Trainer 类下的评估指标,变压器模型的 F1 得分为 15.88。发现 F1 分数低的一个关键原因是 Transformer 模型无法生成问题,而是生成的句子类似于 SQuAD 中的答案。这些预测的输出可能是因为模型已经熟悉问答任务并生成答案,因此它无法生成问题。
DistilBERT 模型在 Wikipedia 和 Toronto Book Corpus 的 330 亿个单词上进行了训练,因此对 SQuAD 等小得多的数据集进行微调对于反转 DistilBERT 回答问题的固有行为是无效的。由于 Transformer 模型无法生成问题,我们没有使用度量来评估生成的输出。
prompt 工程
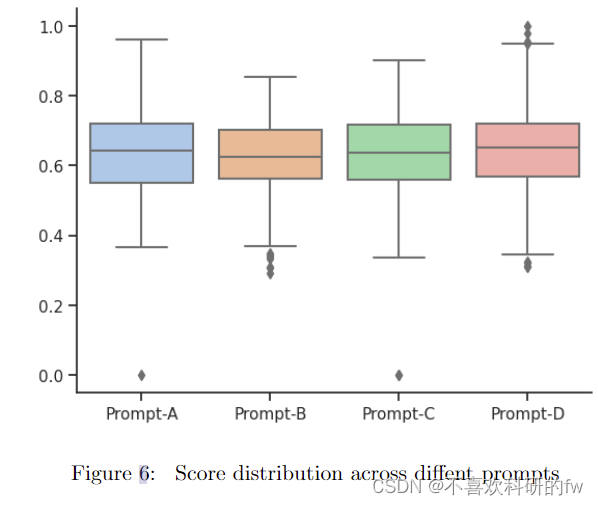
我们使用 spaCy 度量进行相似性评分。图 6 是每个提示下所有生成问题的相似度分数箱线图。箱线图显示,Prompt D生成的问题的中位数相似度得分在0.6444时最高。此外,Prompt D也具有最高的异常值,其中一个与1的相似度得分完美匹配。Prompts A和C的平均相似度得分分别为0.6387和0.6321。提示 B 表现最差,平均最低为 0.62227。
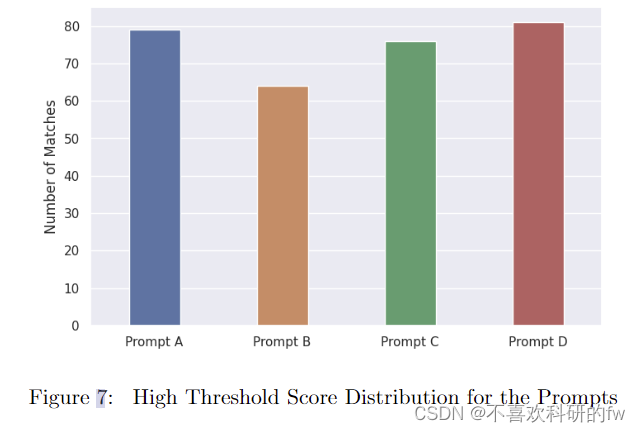
我们使用的另一种方法来确定哪个提示表现最好是与基线问题最匹配的提示。我们建立了一个 0.7 个相似度分数的阈值作为匹配。在将相似度得分高于 0.7 的生成问题与基线问题进行比较后,我们发现大多数生成的问题与基线问题具有相同的含义;而相似度得分低于 0.7 生成的问题本质上是不同的。我们将匹配定义为基线和生成的问题几乎相同时。图 7表明Prompts A、B、C和D分别有79、64、76和81个匹配,在250个问题中,每个提示总共生成。提示D的匹配次数最多,因此在给定SQuAD数据集质量最高的问题的情况下,它可以生成最高质量的问题。提示 B 的匹配次数最少。Prompt B 中的单词“复杂”可能已经从上下文中生成了无法回答的问题,并且需要更关键的思维,因此在相似性度量下表现不佳。表 3 显示了 Prompt B 生成的无法回答的问题。
D表现最好 A表现第二好 B/C表现区别不大 质量一般

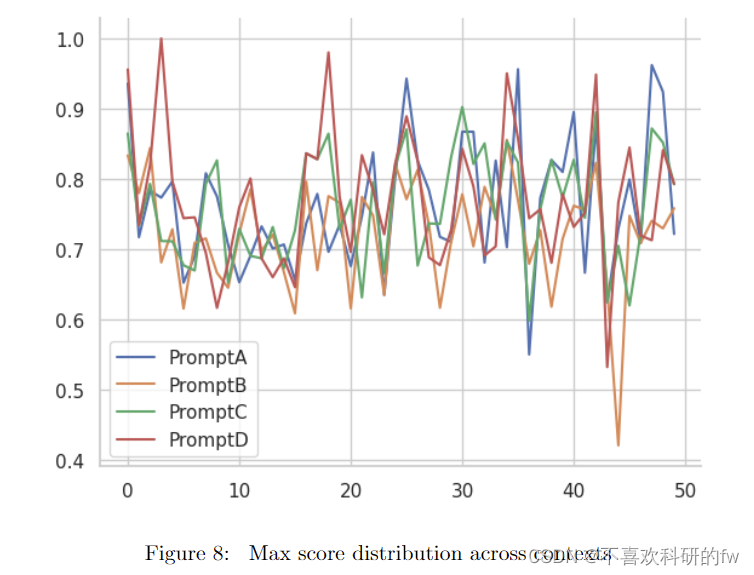
最后,图 8 是总共 50 个上下文中的每一个下每个提示的最大分数分布图。通常,红色 (Prompt D) 和蓝色 (Prompt A) 行比橙色 (Prompt B) 和绿色 (Prompt C) 行更显着。与 Prompt A、C 和 D 相比,提示 B 的上下文 45 具有特别低的相似度分数,A、C、D相似度得分分别为 0.73、0.70 和 0.77。这可能是因为 Prompt B 生成了复合问题,其中两个问题合并为一个。例如,其中一个问题是,“Nirvana 在多大程度上可以被视为痛苦周期的解放,以及这是如何实现的?”
6 结论
在本文中,我们在问题生成任务上微调了一个 distilBERT 模型。该变压器模型不能生成 F1 得分为 15.88 的问题。另一方面,Meta 的 LLAMA 模型使用我们使用提示工程指南创建的提示成功地生成问题。
由于 Transformer 模型无法生成问题,并且 Meta 的 LLAMA 模型是,我们决定只评估 LLAMA 生成的问题。我们使用相似性度量来确定我们创建的四个提示中的哪一个是最有效的。我们发现最复杂的提示 (Prompt D) 导致与 SQuAD 在 81 个匹配处的基线问题最匹配。最简单的提示 (Prompt A) 使用 79 个匹配执行了第二好的。提示 C 有 76 个匹配。最后,Prompt B 在 64 个匹配处具有显着减少的匹配数。需要注意的是,除了添加的单词“复杂”之外,Prompt B 与 Prompt A 相同,这表明相似度得分度量奖励简单的事实问题而不是复合问题。
我们计划扩展我们的研究以包括其他 LLM,例如 Dolly 模型、GPT-4 和 PaLM 2。此外,我们计划将问题生成模型与分类模型相结合,该模型对特定教育主题下的上下文进行分类,以使问题更适合除阅读理解之外的每个主题。















 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









